题目
表: Person

编写一个 SQL 查询来报告所有重复的电子邮件。 请注意,可以保证电子邮件字段不为 NULL。
以 任意顺序 返回结果表。
查询结果格式如下例。
示例 1:
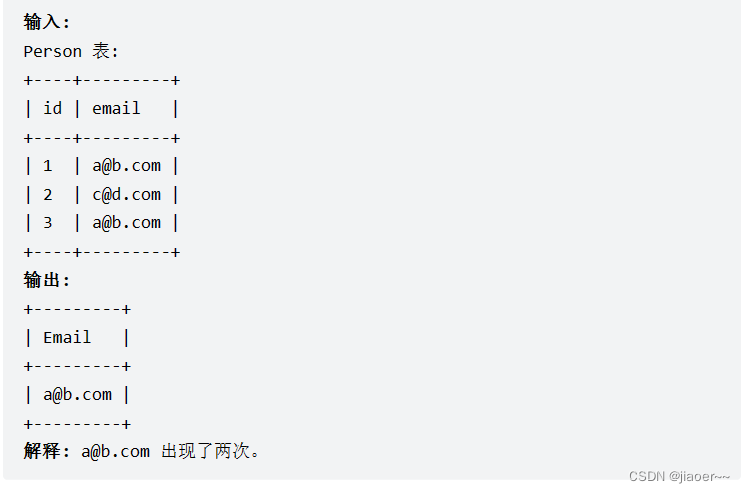 解题思路
解题思路
前置知识
count()
1.count(*) :统计所有的行数,包括为null的行(COUNT(*)不单会进行全表扫描,也会对表的每个字段进行扫描。而COUNT('x')或者COUNT(COLUMN)或者COUNT(0)等则只进行一个字段的全表扫描)。
2.count(1):计算一共有多少符合条件的行,不会忽略null值(其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1..同理,count(2),也可以,得到的值完全一样,count('x'),count('y')都是可以的。count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。)
3.count(列名):查询列名那一列的,字段为null不统计(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
HAVING COUNT() 是 SQL 中用于筛选分组结果的关键字,它通常与 GROUP BY 一起使用。HAVING COUNT() 的作用是对分组后的结果进行过滤,只保留满足条件的分组结果。
有了上述知识我们来解决一下这个问题
1.题目要求我们查询 所有重复的电子邮件 ,首先我们要用 group by 对 email 的值进行分组
2.分好组后 我们用 count( ) 函数计算 分组后结果大于1的 email。
代码实现
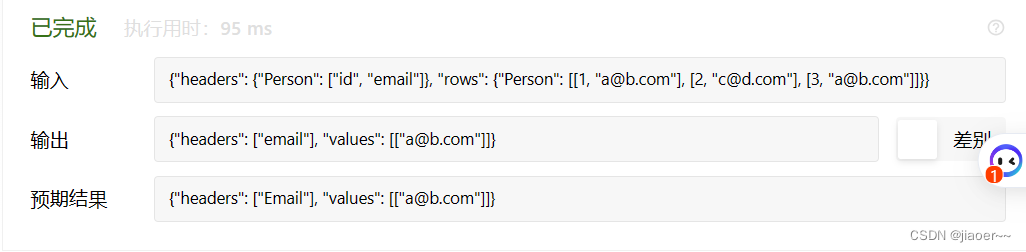
select email from Person group by email having count(email)>1 测试结果