1. Kmeans聚类算法简介
由于具有出色的速度和良好的可扩展性,Kmeans聚类算法算得上是最著名的聚类方法。Kmeans算法是一个重复移动类中心点的过程,把类的中心点,也称重心(centroids),移动到其包含成员的平均位置,然后重新划分其内部成员。k是算法计算出的超参数,表示类的数量;Kmeans可以自动分配样本到不同的类,但是不能决定究竟要分几个类。k必须是一个比训练集样本数小的正整数。有时,类的数量是由问题内容指定的。例如,一个鞋厂有三种新款式,它想知道每种新款式都有哪些潜在客户,于是它调研客户,然后从数据里找出三类。也有一些问题没有指定聚类的数量,最优的聚类数量是不确定的。
Kmeans的参数是类的重心位置和其内部观测值的位置。与广义线性模型和决策树类似,Kmeans参数的最优解也是以成本函数最小化为目标。Kmeans成本函数公式如下:
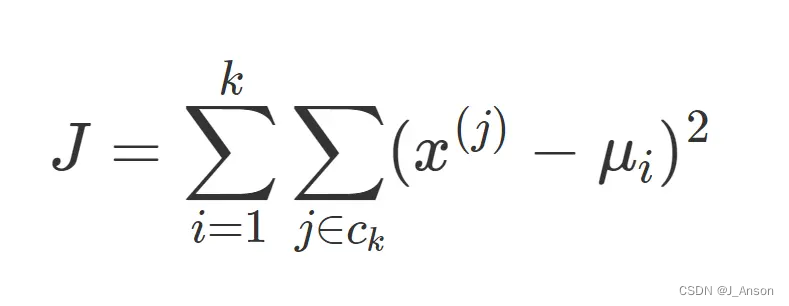
μi是第k个类的重心位置。成本函数是各个类畸变程度(distortions)之和。每个类的畸变程度等于该类重心与其内部成员位置距离的平方和。若类内部的成员彼此间越紧凑则类的畸变程度越小,反之,若类内部的成员彼此间越分散则类的畸变程度越大。求解成本函数最小化的参数就是一个重复配置每个类包含的观测值,并不断移动类重心的过程。首先,类的重心是随机确定的位置。实际上,重心位置等于随机选择的观测值的位置。每次迭代的时候,Kmeans会把观测值分配到离它们最近的类,然后把重心移动到该类全部成员位置的平均值那里。
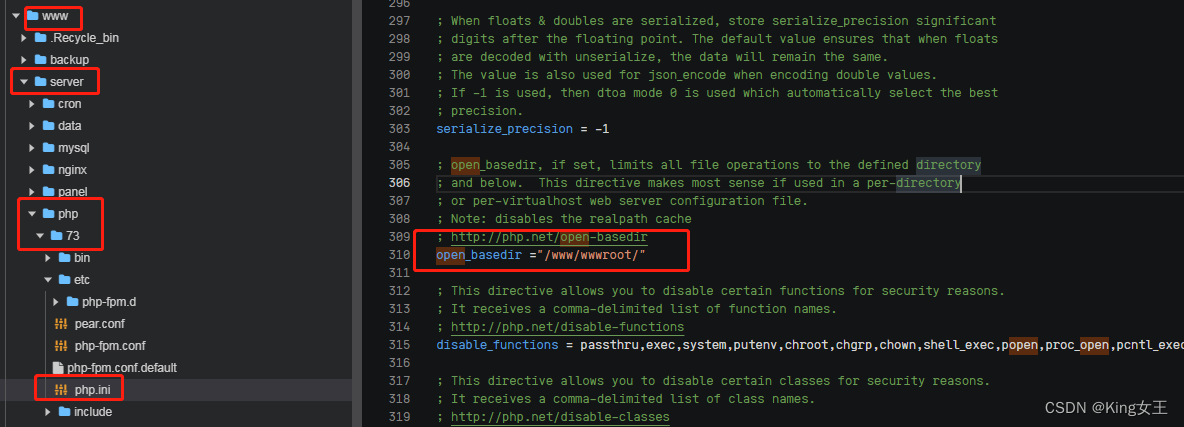
本文尝试利用KMeans分割图像的前景和背景。使用sklearn中的KMeans算法,利用matplotlib画图工具绘制图片,并准备两张图片。图片挑选其中一张背景色较为复杂,且前景色与背景色存在颜色色域重叠;另一张背景色较为单一,且与前景色区别较大。

2.导入包
import os.path
import matplotlib.pyplot as plt
from matplotlib.image import imread
import numpy as np
from sklearn.cluster import KMeans3.编写实现方法
image_names = ["dog.jpeg", "flower.jpg"]
for image_name in image_names:
image = imread(f"../data/{image_name}")
X = image.reshape(-1, 3)
save_path = "../data/res/"
if not os.path.exists(save_path):
os.makedirs(save_path)
plt.imsave(f"../data/res/{image_name.split('.')[0]}1.jpeg", image)
for k in range(2, 10):
kmeans = KMeans(n_clusters=k, n_init=10, random_state=20).fit(X)
img = kmeans.cluster_centers_[kmeans.labels_].astype(np.uint8)
img = img.reshape(image.shape)
plt.figure(figsize=(10, 5))
plt.imsave(f"../data/res/{image_name.split('.')[0]}{k}.jpeg", img)
从分割结果上看,dog的效果一般,flower的效果较好。