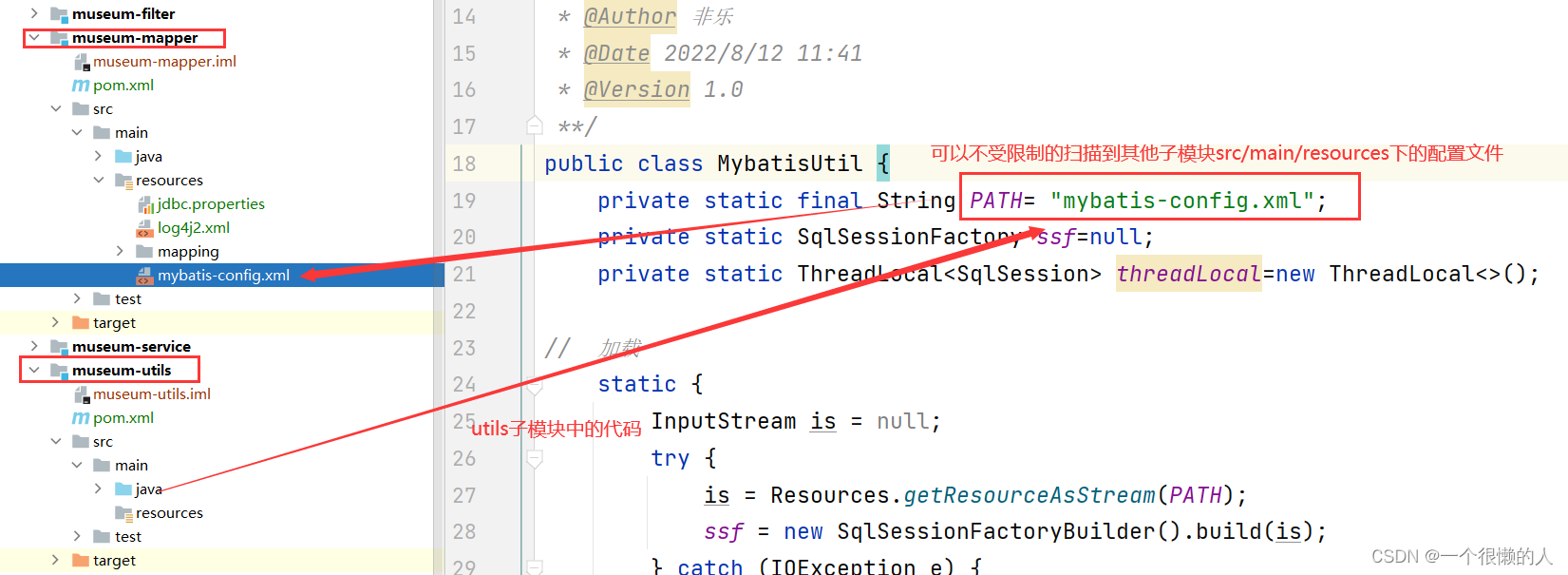
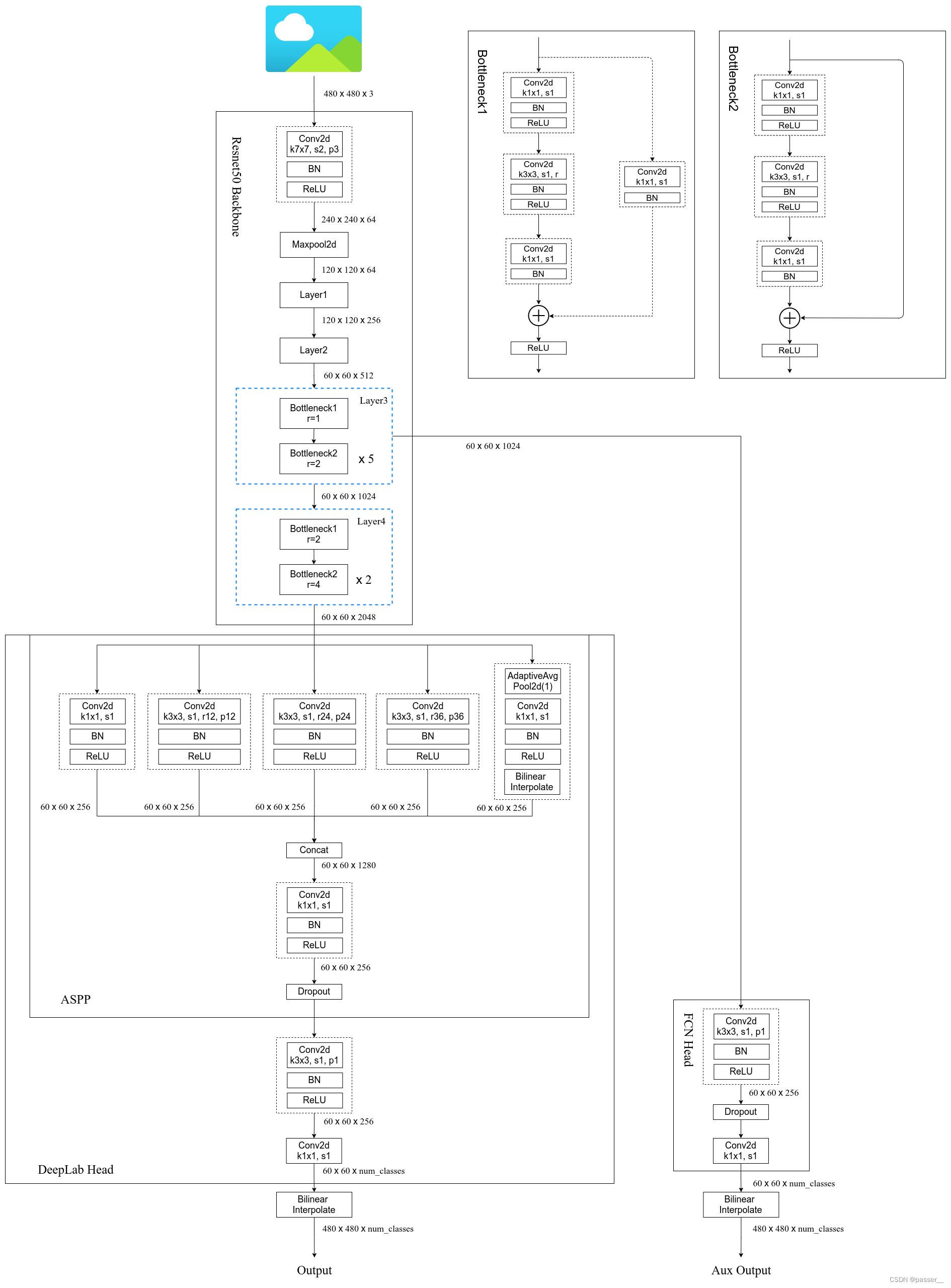
刚开始学习编程,我们很少会关注这个文件,只知道一个目录中存在该文件,该目录就是一个package,不存在就是普通的目录,普通的目录在导入包时,pycharm并不会智能提示。
Python中每新建一个package都会默认生成一个__init__.py文件,在做Python项目时,会存在很多个package,这时候__init__.py可以发挥强大的作用,我们可以在__init__.py文件中写一些代码方便我们调用该package下的模块。
1. __init__.py是何时调用的
当我们import某个package时,会首先调用该package下的__init__.py
package1/
__init__.py
subPack1/
__init__.py
module_11.py
module_12.py
module_13.py
main.py
例如我们存在一个项目,目录结构如上所示,在 subPack1下的__init__.py下我们增加如下代码
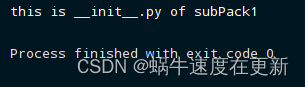
print(f'this is __init__.py of subPack1')然后我们在main.py文件中导入subPack1, main.py文件中的代码如下:
import subPack1直接运行main.py,这是我们可以看到控制台输出:
2. __init__.py何时使用(应用场景)
当我们开发项目时,会存在多个package,但是我们在导入包的时候会使用绝对路径,这样在多个文件都引用时,会显得特别麻烦,这时候我们就可以利用每个package中的__init__.py文件,最终的结果就是简洁易读。
我们可以想一下,当我们使用第三方包pandas时,是如何导入的DataFrame()类的,使用如下的语句就可以直接导入进来:
from pandas import DataFrame
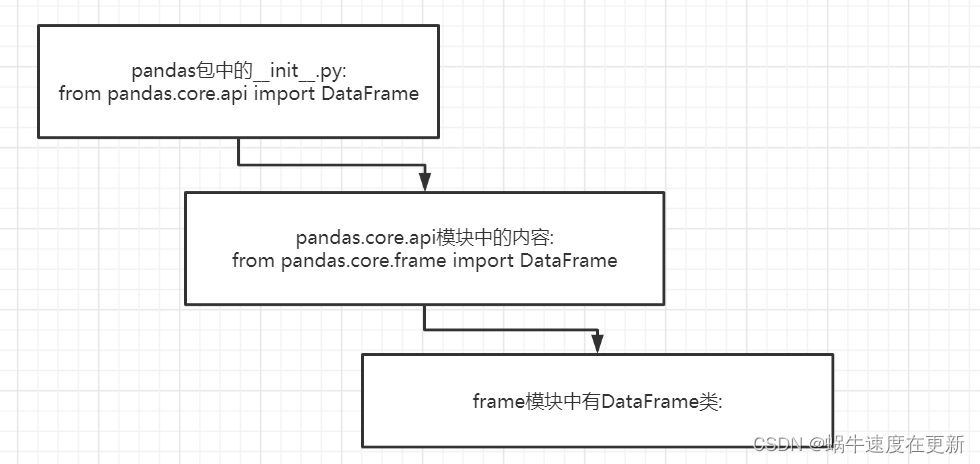
我们下面就一探究竟,为什么这样就直接可以使用 DataFrame,通过查看pandas安装包,我们可以发现DataFrame()是在frame.py模块下,目录结构如下:

下面我们就看看,这是如何做到的
首先我们看一下core package的__init__.py中有哪些内内容,很抱歉,这个文件是空的,啥也没有,那么接下来我们就看上一级package pandas下的__init__.py中有哪些内容:
有用的内容如下:
可以看到pandas package从pandas.core.api中导入了DataFrame类
from pandas.core.api import (
# dtype
Int8Dtype,
Int16Dtype,
Int32Dtype,
Int64Dtype,
UInt8Dtype,
UInt16Dtype,
UInt32Dtype,
UInt64Dtype,
Float32Dtype,
Float64Dtype,
CategoricalDtype,
PeriodDtype,
IntervalDtype,
DatetimeTZDtype,
StringDtype,
BooleanDtype,
# missing
NA,
isna,
isnull,
notna,
notnull,
# indexes
Index,
CategoricalIndex,
Int64Index,
UInt64Index,
RangeIndex,
Float64Index,
MultiIndex,
IntervalIndex,
TimedeltaIndex,
DatetimeIndex,
PeriodIndex,
IndexSlice,
# tseries
NaT,
Period,
period_range,
Timedelta,
timedelta_range,
Timestamp,
date_range,
bdate_range,
Interval,
interval_range,
DateOffset,
# conversion
to_numeric,
to_datetime,
to_timedelta,
# misc
Flags,
Grouper,
factorize,
unique,
value_counts,
NamedAgg,
array,
Categorical,
set_eng_float_format,
Series,
DataFrame,
)我们接下来看看pandas.core.api这个模块中有哪些内容,可以看到该文件中存在如下代码:
# DataFrame needs to be imported after NamedAgg to avoid a circular import
from pandas.core.frame import DataFrame # isort:skip这样我们的思路就理顺了,另外说一点pandas.core.api中的内容完全可以方法core下的__init_.py中。
我们来理一下思路, 看下图结构,pandas.core.api中导入了DataFrame类,那么该文件中就存在DataFrame()类,可以使用print(dir())代码输出当前模块包含的其他对象。这样在最外侧的pandas包中的__init__.py中就可以使用绝对路径导入pandas.core.api文件中已经存在的DataFrame()类,这样我们在使用pandas时就可以直接from pandas import DataFrame使用了,如果__init__.py文件中没有任何内容,那么每次使用,我们就必须以绝对路径导出DataFrame类,这样一是不方便寻找,再一个是代码看起来可读性差。
除了上述作用以外,我们还可以看到pandas包下的__init__.py文件中还有如下内容:就是检查pandas包的依赖,这样每次用户导入pandas包是,就会立刻检查依赖是否存在,如果不存在,将会报错,提示用户安装。
hard_dependencies = ("numpy", "pytz", "dateutil")
missing_dependencies = []
for dependency in hard_dependencies:
try:
__import__(dependency)
except ImportError as e:
missing_dependencies.append(f"{dependency}: {e}")
if missing_dependencies:
raise ImportError(
"Unable to import required dependencies:\n" + "\n".join(missing_dependencies)
)
del hard_dependencies, dependency, missing_dependencies





![Matplotlib入门[07]——修改默认设置](https://img-blog.csdnimg.cn/e06ed3052bd94d6797c68b322dcc3f04.png)