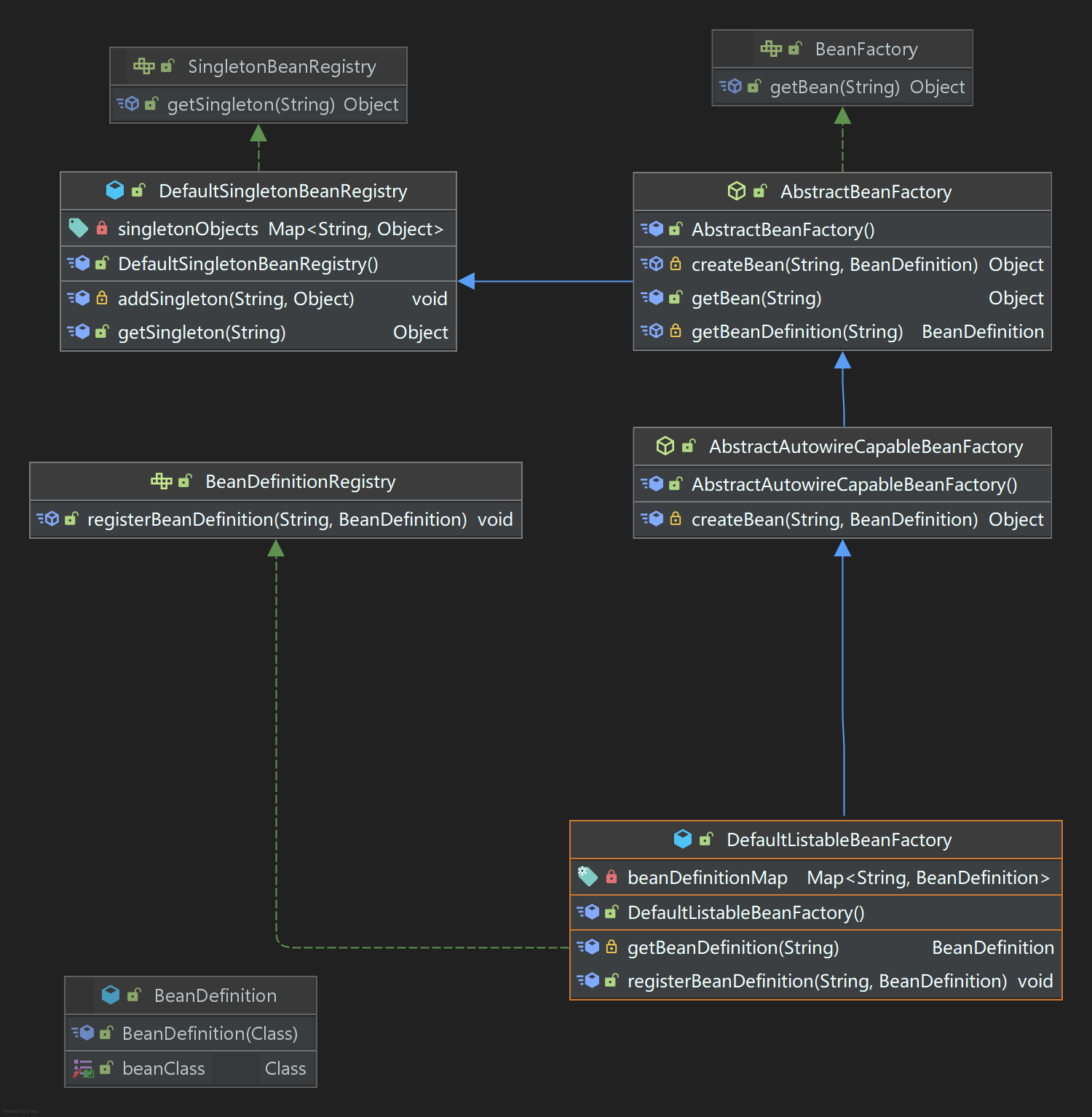
DeepLab V3
- 遇到的问题和解决方法
- 相关工作
- DeepLab V3中的两种模型结构
- cascaded model
- ASPP model
- 相对于DeepLab V2的优化
- Multi-grid Method
- ASPP的改进
- 消融实验
- cascaded model消融实验
- ASPP model消融实验
- 和其他网络的对比
- 实验总结
- 网络模型图
遇到的问题和解决方法
对于DeepLab系列的文章它们想解决的问题都是一致的
分辨率被降低(主要由于下采样stride>1的层导致)
目标的多尺度问题
相关工作
针对于上边的问题,在DeepLab V3出现了一些相较于V2的一些优化,比如去掉了CRF,因为CRF虽然是有提升,但是提升已经是非常小了,但是它的花费相对于其他的不是一个数量级,下边讲对于模型和优化进行详细的说明。
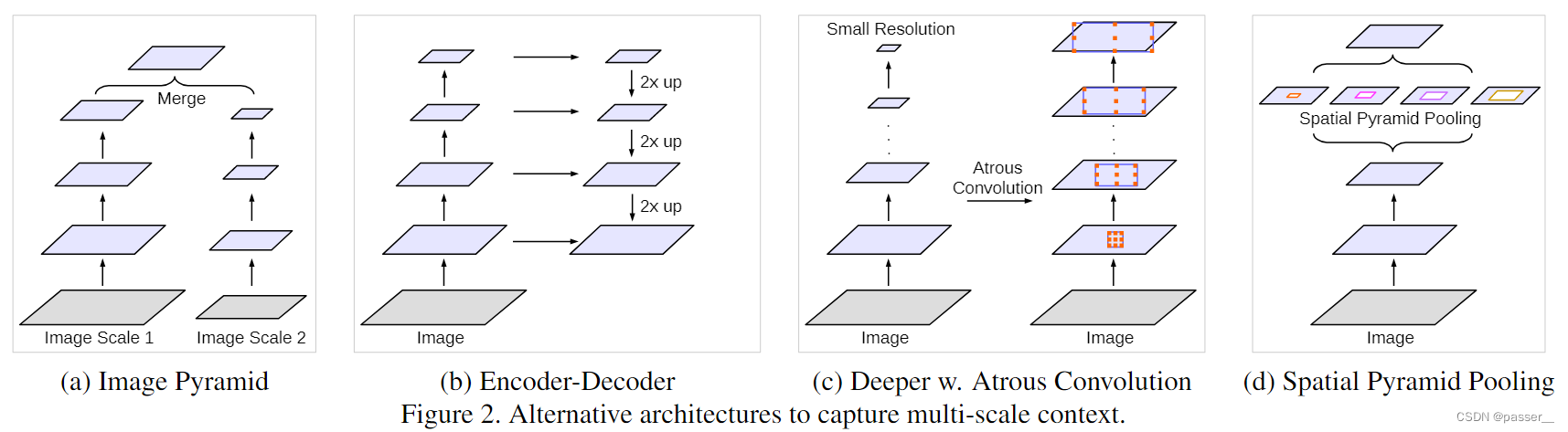
作者整理了目前已经出现的几种多尺度的方法:
- 第一种:图像金字塔,即将输入图像缩放成不同比例,将预测结果融合得到最后输出。
- 第二种:Encoder-Decoder:类似于U-Net,即将Encoder阶段的多尺度特征运用到Decoder阶段上来恢复空间分辨率。
- 第三种:在原始模型的顶端叠加额外的模块,利用空洞卷积以捕捉像素间长距离信息。
- 第四种:多尺度捕获信息。用不同的采样率捕获信息,在多个尺度上进行空洞卷积/池化。起到了提取多尺度特征的作用。
DeepLab V3中的两种模型结构
在本文中作者提出了两种不同的结构,而且在后边进行的实验的结果中也会有两种不同模型的一个性能对比,第一种模型叫做cascaded model,第二种叫ASPP model,目前在github复现的代码中,主要还是ASPP model,而且作者对于两个网络的评价也是ASPP model的性能要比cascaded model效果更佳的好。
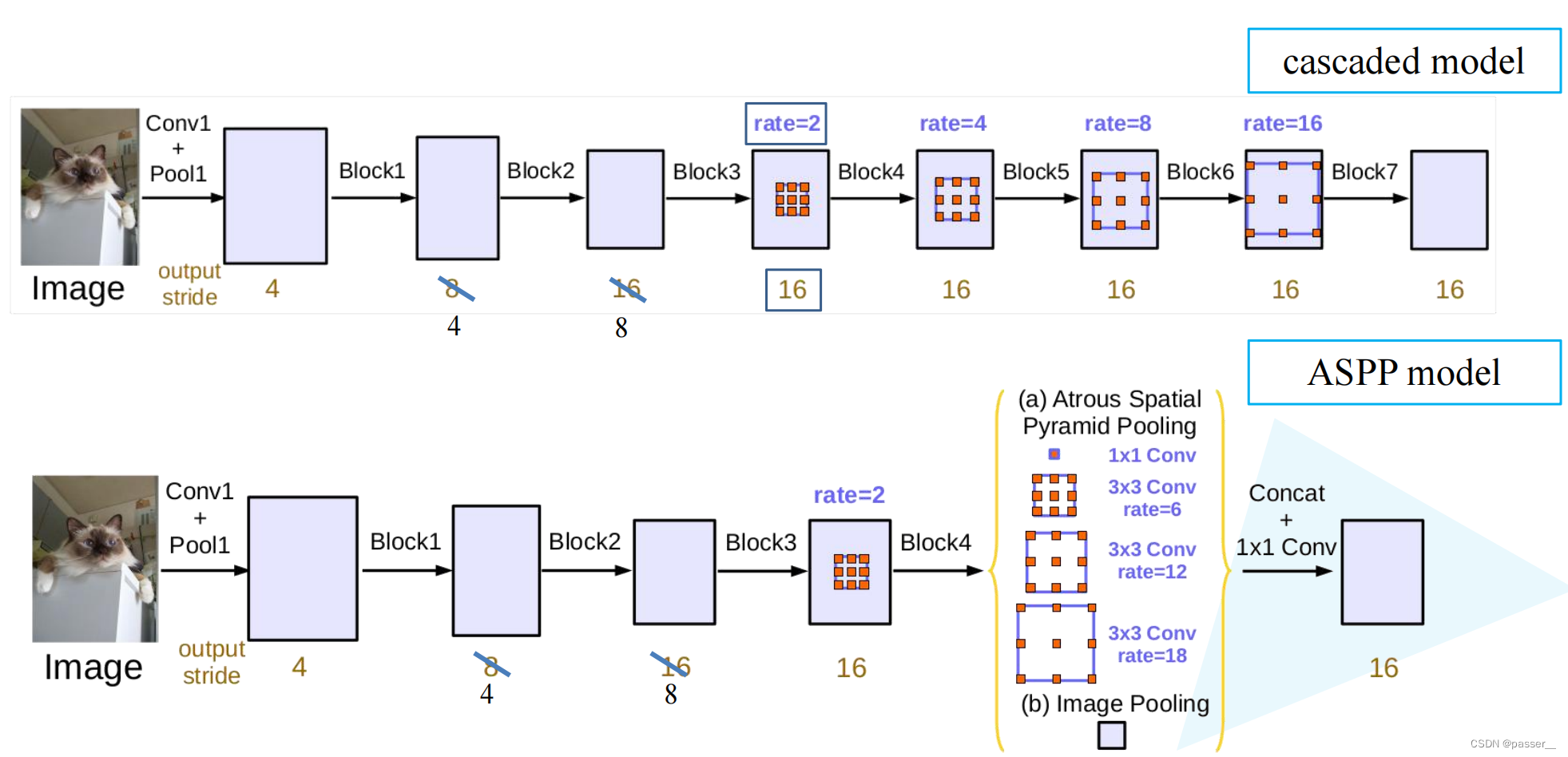
cascaded model
在这篇文章中,大部分实验都是围绕这个模型来做的,如下图所示(文章中的model指的是b),对于下图的Block1,2,3,4都是ResNet网络中原始的模块(Block4 中第一个残差结构里的3 * 3的卷积层和捷径分支上的1 * 1的卷积层的 stride从2变成了1这样图片就不会下采样,后续是额外新增加的一些模块,不过对于Block5,6,7它们的结构都是Block是一样的,不过它们的卷积都换成了膨胀卷积。另外说明一下,图中的rate=2并不代表最后的膨胀系数是2, 真正采用的膨胀系数应该是图中的rate乘上Multi-Grid参数,比如Block4中rate=2,Multi-Grid=(1, 2, 4)那么真正采用的膨胀系数是2 x (1, 2, 4)=(2, 4, 8)。关于Multi-Grid参数后面会提到。
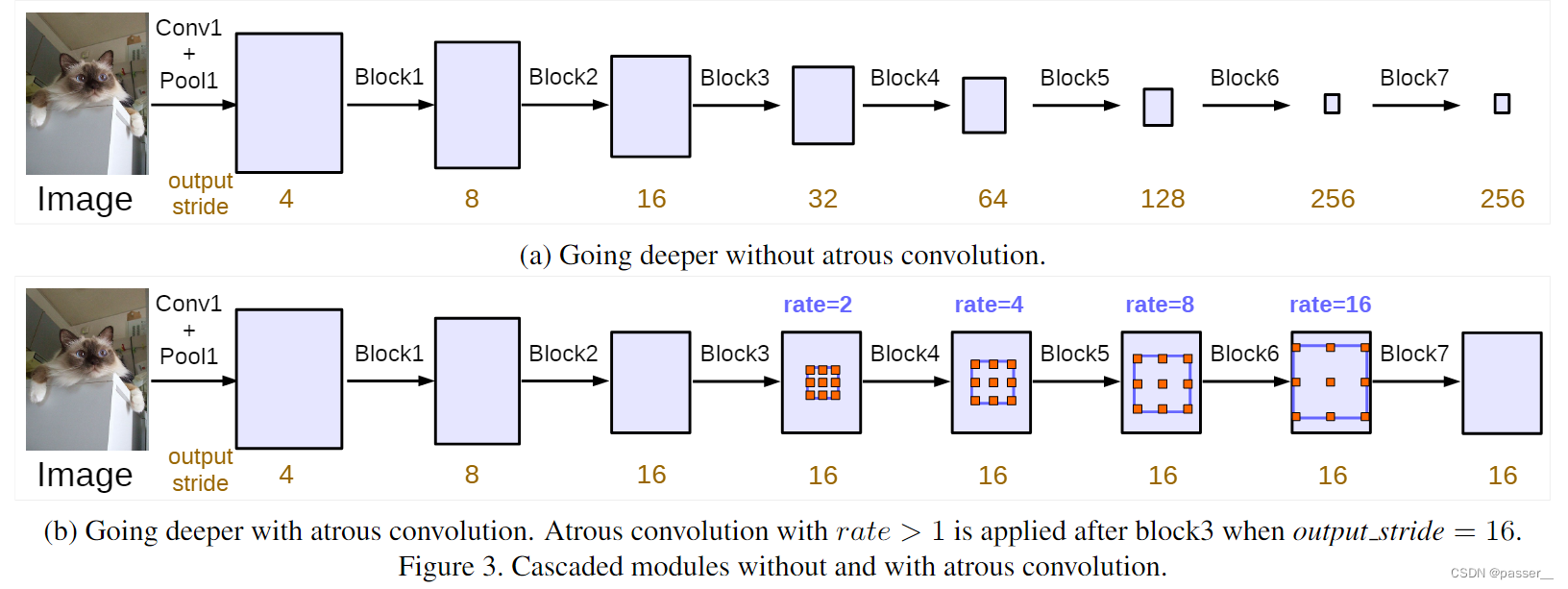
作者将output_stride从8到256都设置,但是将output_stride设置太大,效果就会变差,但是可能是当时的显存不足,原论文中将output_stride设置为16(训练设置为16,测试是8),但是目前Github复现都将output_stride设置为8(训练和测试都是8)。

ASPP model
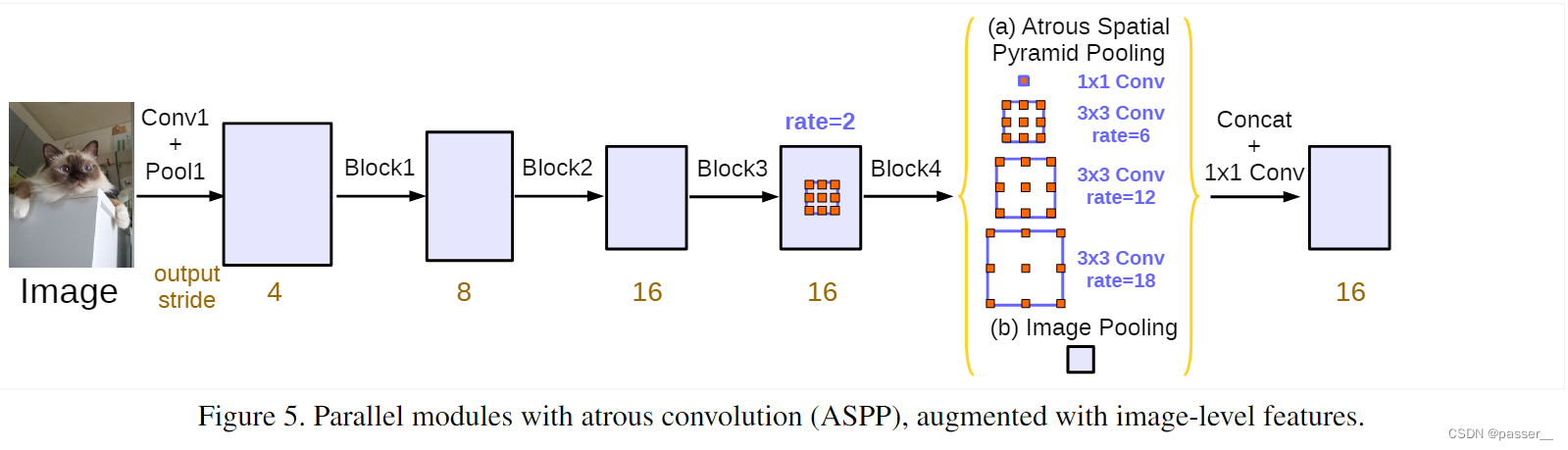
对于ASPP model和上边那个模型同样的问题,对于output_stirde都是设置为8。
对于ASPP的改进详情参考下边。
相对于DeepLab V2的优化
Multi-grid Method
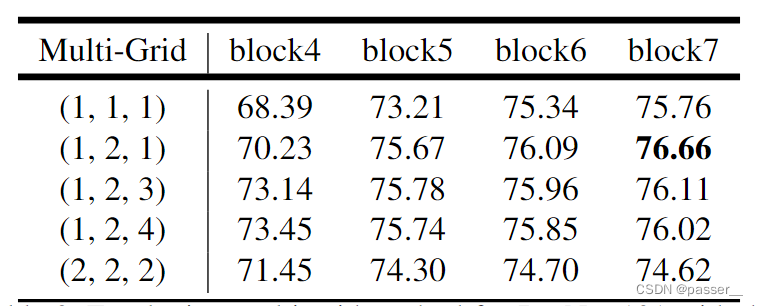
作者测试了不同的Multi-Grid,看看如何设置更加的合理(炼丹),上表是以cascaded model(ResNet101作为Backbone为例)为实验对象,研究采用不同的Multi-Grid参数的效果。注意,刚刚在讲cascaded model时有提到,blocks中真正采用的膨胀系数应该是图中的rate乘上这里的Multi-Grid参数。通过实验发现,当采用三个额外的Block时(即额外添加Block5,Block6和Block7)将Multi-Grid设置成(1, 2, 1)效果最好。另外如果不添加任何额外Block(即没有Block5,Block6和Block7)将Multi-Grid设置成(1, 2, 4)效果最好,因为在ASPP model中是没有额外添加Block层的,后面讲ASPP model的消融实验时采用的就是Multi-Grid等于(1, 2, 4)的情况。
ASPP的改进
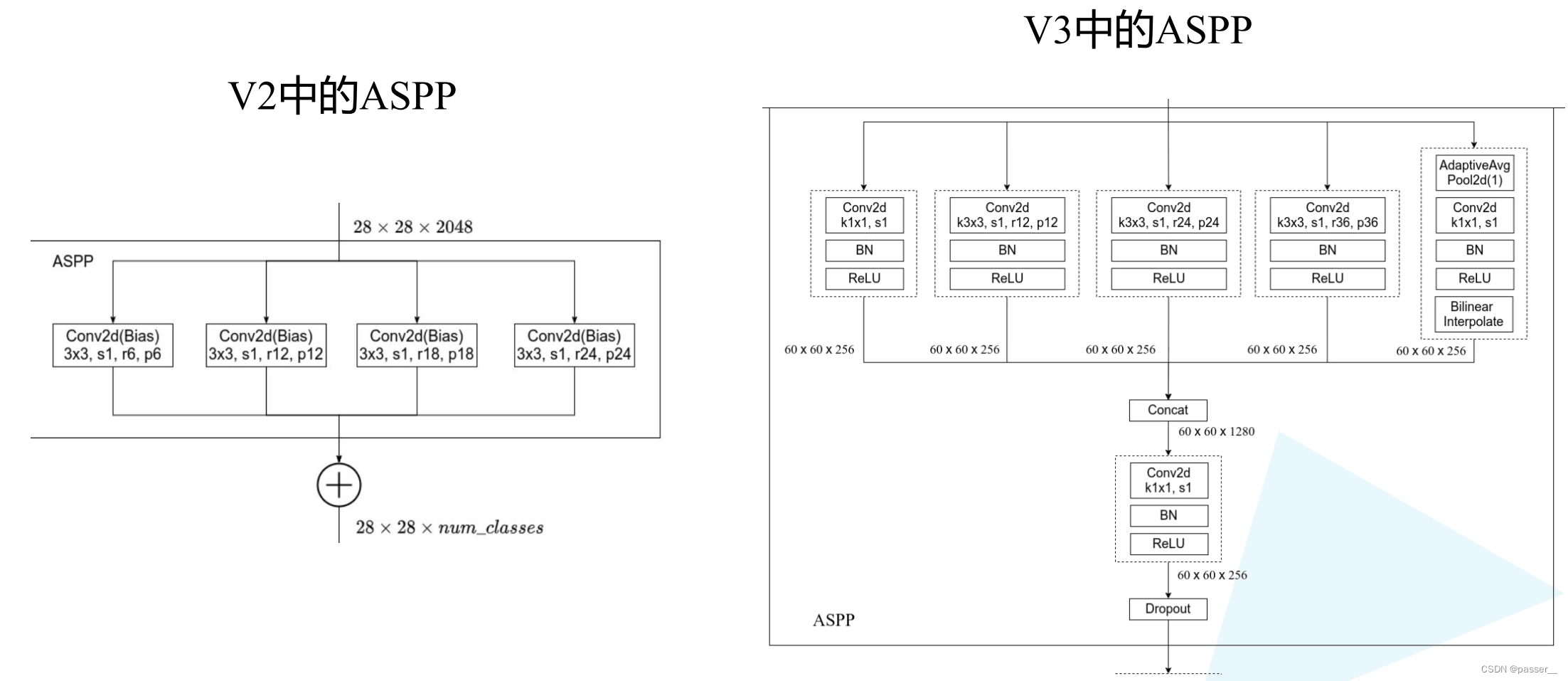
对比V2和V3中的ASPP结构。V3中的ASPP结构有5个并行分支,分别是一个1x1的卷积层,三个3x3的膨胀卷积层,以及一个全局平均池化层(后面还跟有一个1x1的卷积层,然后通过双线性插值的方法还原回输入的W和H)。关于最后一个全局池化分支作者说是为了增加一个全局上下文信息global context information。然后通过Concat的方式将这5个分支的输出进行拼接(沿着channels方向),最后在通过一个1x1的卷积层进一步融合信息。
消融实验
cascaded model消融实验

- OS代表上文中讲到的output_stride,从图中可以发现8比16高了接近1.5个点
- MS代表多尺度,和DeepLabV2中类似,不过在DeepLab V3中采用的尺度更多scales = {0.5, 0.75, 1.0, 1.25, 1.5, 1.75}。
- Flip代表增加一个水平翻转后的图像输入。
ASPP model消融实验

- MG代表Multi-Grid,刚刚在上面也有说在ASPP model中采用MG(1, 2, 4)是最好的。
- Image Pooling代表在ASPP中加入全局平均池化层分支(本来就属于那个ASPP中的一个分支)。
- OS代表output_stride,刚刚在上面也有提到将output_stride设置成8效果会更好
- MS代表多尺度,和DeepLabV2中类似,不过在DeepLab V3中采用的尺度更多scales = {0.5, 0.75, 1.0, 1.25, 1.5, 1.75}。
- Flip代表增加一个水平翻转后的图像输入。
- COCO代表在COCO数据集上进行预训练。
和其他网络的对比
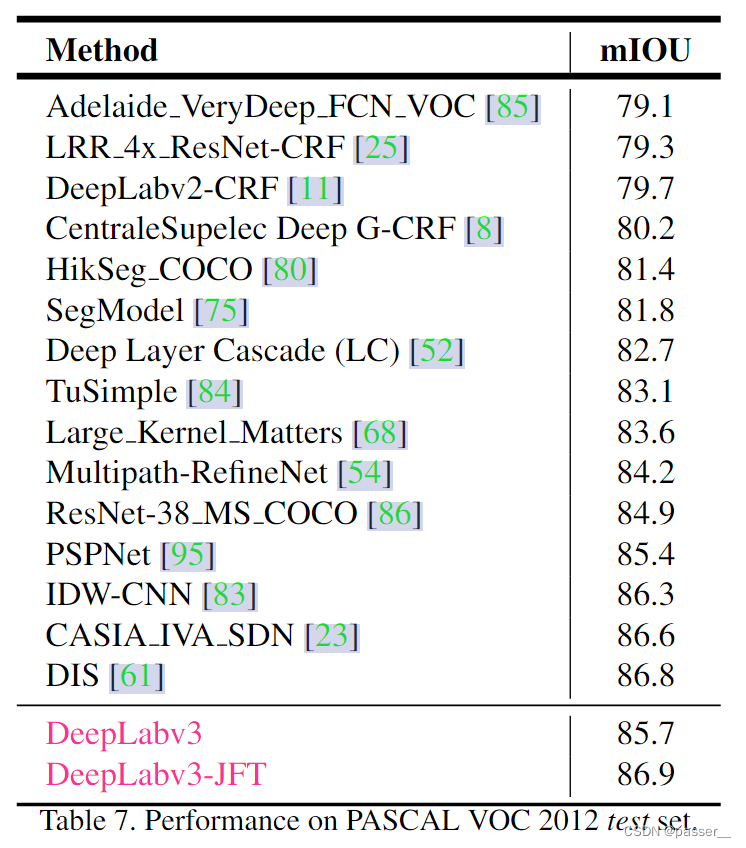
实验总结
对于上图中发现DeepLab V3比V2提高了接近6个点,在论文中的 Effect of hyper-parameters 部分中提到了一些询问的小细节:
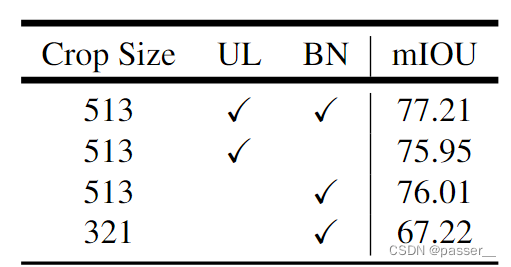
- 在训练过程中增大了训练输入图片的尺寸(论文中有个观点大家需要注意下,即采用大的膨胀系数时,输入的图像尺寸不能太小,否则3x3的膨胀卷积可能退化成1x1的普通卷积。)
- 计算损失时,是将预测的结果通过上采样还原回原尺度后(即网络最后的双线性插值上采样8倍)再和真实标签图像计算损失。而之前在V1和V2中是将真实标签图像下采用8倍然后和没有进行上采样的预测结果计算损失(当时这么做的目的是为了加快训练)。根据Table 8中的实验可以提升一个多点。
- 训练后,冻结bn层的参数然后在fine-turn下网络,根据Table 8中的实验可以提升一个多点。
网络模型图
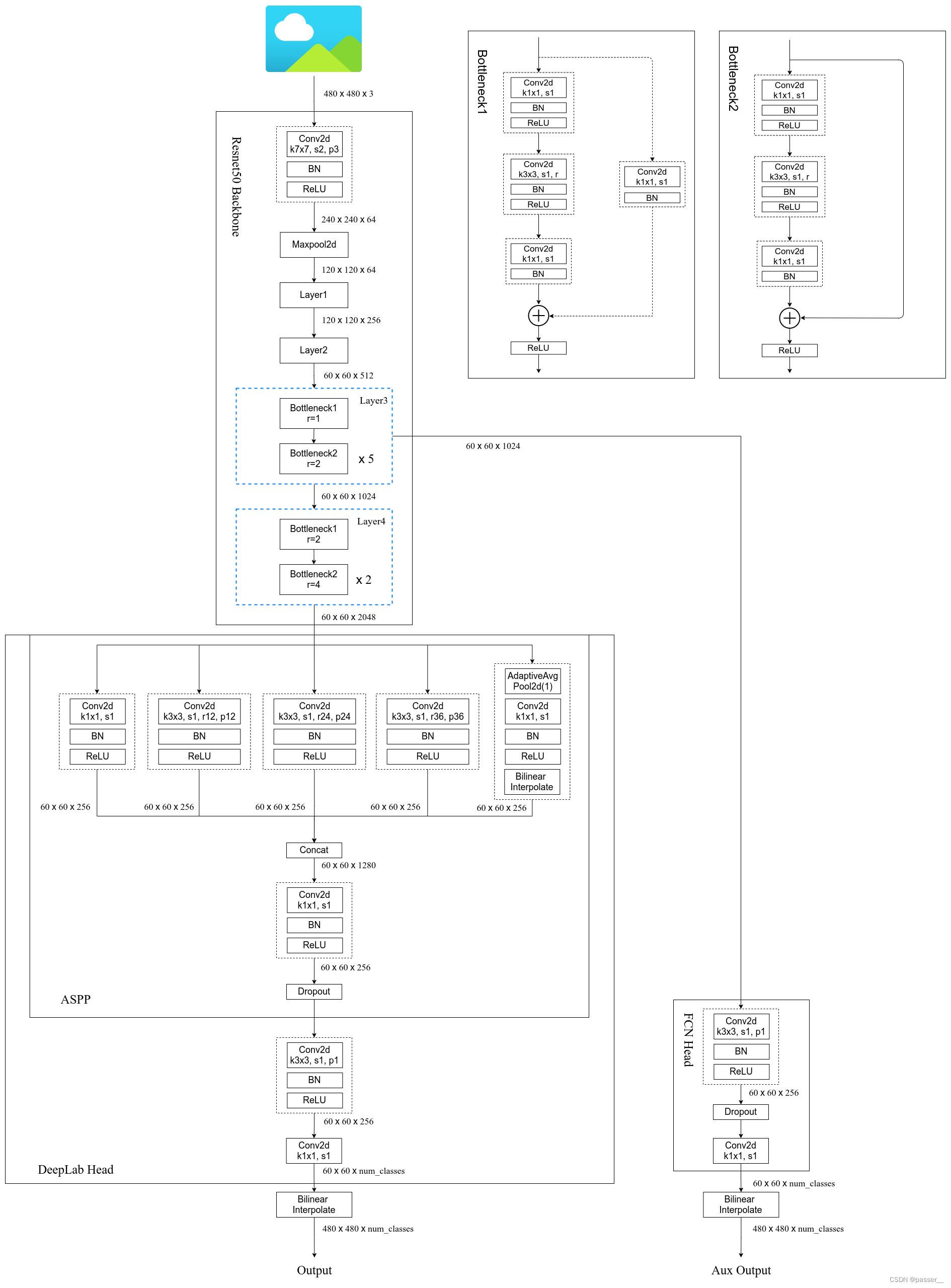
推荐视频讲解: 霹雳