1.系统通配符
* #所有
. #当前目录
.. #当前目录的上一级目录
- #当前目录的上一次所在的目录
~ #家目录
# #注释,超级管理员的命令行提示符
$ #引用变量,普通用户的命令行提示符
? #匹配任意一个字符,必须是一个
! #非,取反
[] #匹配中括号中任意一个字符
{} #生成序列,整体
[^] #排除中括号中所有字符
`` #优先执行反引号里面的命令
$() #优先执行里面的命令
&& #前面一个命令执行成功,才会执行后面的命令
|| #前面的命令执行失败,才会执行后面的命令
| #管道,将前面的命令的输出结果交给管道后面的命令
\ #转义字符,取消一些特殊字符的含义
& #将程序放到后台运行2.正则元字符
^ #开头
$ #结尾
^$ #空行
\ #转义字符
. #任意字符,除了换行符
[] #匹配中括号中的任意一个字符
[^] #匹配[^]之外的所有字符
[a-z] #匹配所有小写字母
[0-9] #匹配所有数字
[A-Z] #匹配所有大写字母
? #匹配前面的字符出现0次或者1次 #扩展
* #匹配前面的字符出现0次或者0次以上
+ #匹配前面的字符出现1次或者1次以上 #扩展
.* #所有
() #整体,后向引用,创建一个用于匹配的字符串 #扩展
{n} #n数字, 前面的字符出现n次
{n,} #前面的字符至少出现n次
{n,m} #前面的字符出现至少n次,最多m次 n<m
{,m} #前面的字符最多出现m次
| #或者 #扩展正则
\w #匹配字母,数字,下划线,汉字
\s #匹配任意空白字符
\d #匹配数字
\b #匹配单词的开始或结束
\n #换行符
\W #匹配任意不是字母,数字,下划线,汉字的字符
\S #匹配任意不是空白符的字符
\D #匹配任意非数字字符
\B #匹配不是单词开头或者结束的位置
-----特定匹配------
[[:upper:]] #所有大写字母
[[:lower:]] #所有小写字母
[[:alpha:]] #所有字母
[[:space:]] #所有空白字符
[[:digit:]] #所有数字
[[:alnum:]] #所有字母和数字
[[:punct:]] #所有特殊符号3.正则基础扩展
零宽断言
(?=ip) #匹配ip字符串前面的内容
(?<=ip) #匹配ip字符串后面的内容
(?!ip) #反向判断断言,如果不匹配ip字符串则取前面的内容,匹配则不取
(?<!) #反向判断断言,如果不匹配ip字符串则取后面的内容,匹配则不取捕获
(ip) #匹配字符串为ip的值,捕获文本到自动命名的组中
(?<name>ip) #匹配字符串为ip的值,捕获文本到名称为name的组中
(?:ip) #匹配字符串为ip的值,不捕获文本,也不分配到组中4.正则的使用
以下使用grep过滤命令来对正则规则来实战,我这边随便用一个文件,此前先来了解一下grep的参数功能
-i #忽略大小写
-v #排除
-n #显示过滤出来的内容所在文件的行号
-c #将过滤出来的内容进行统计
-w #精确匹配
-o #只显示过滤出来的内容
-E #支持扩展正则,正则的扩展参数需要加上-E,以上正则参数有备注哪些是扩展参数,如果实在不清楚,使用正则规则都加-E也不会有问题
-r #递归过滤
-R #递归过滤
-A #显示过滤出来内容在原文本中的下多少行
-B #显示过滤出来内容在原文本中的上多少行
-C #向上向下各多少行
过滤以HTTP开头的行
grep '^HTTP' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

过滤以}结尾的行
grep '}$' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

将空行过滤掉,这里结合grep的-v参数配合正则去过滤
grep -v '^$' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

使用转义符取消字符的属性从而匹配符合的内容
grep '\?' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配任意字符,除了空行
grep '.' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配所有,包含空行(对比上下图可以看到,下面图是有匹配空行的,上图没有匹配空行)
grep '.*' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配含有特定字符的行
grep '[ab]' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配含有特定字符串的行
grep -E '(or)' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

排除开头含有[]中任意字符的行
grep '^[^H#]' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配含有数字的行,此处使用正则符号*,匹配的数字至少需要出现0次以上(在引入两个命令做统计,sort统计相同的行数,uniq -c是去重)
grep -E '[0-9]*' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd |sort |uniq -c

匹配含有数字的行,此处使用正则符号+,匹配的数字至少需要出现1次以上(对比上下图的匹配可以发现,使用正则符号*和+的区别,因为*至少匹配的数字出现0次以上就可以,所以可以匹配到所有的行包括空行,而+至少匹配的数字出现1次以上才可以,所以只能匹配到带数字的行)
grep -E '[0-9]+' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd |sort |uniq -c

匹配含有数字的行,此处使用正则符号+,匹配的数字只能出现0次或者1次(看下图的效果与正则符号*的输出对比可以看到,*是可以连续匹配0次以上,而?只能匹配0次或者一次,所以?的输出结果每次只能输出一位数字,而*对于连续的数字可以一直匹配,此处使用了grep的-o参数是只输出匹配的结果,不输出其它内容)
grep -Eo '[0-9]?' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd
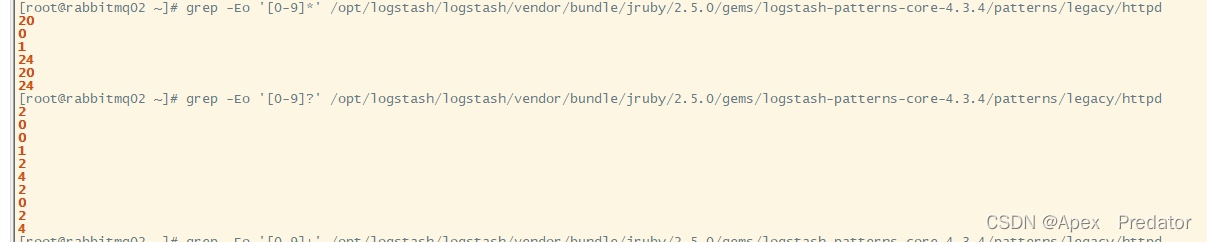
匹配至少连续匹配1个数字,至多连续匹配两个数字的行(可以看一下两条命令输出的对比)
grep -E '[0-9]{1,2}' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd
grep -E '[0-9]{2,3}' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配多个特定字符串的行(以下两种方式都可以)
grep -E 'client|pid' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd
grep -E '(client|pid)' /opt/logstash/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.3.4/patterns/legacy/httpd

匹配ip地址(ip地址的每一位都有可能是1位数或者2位数或者3位数,所以使用{,}来限定最少匹配一位最多匹配三位,而且ip地址中的.需要使用转义符\来转移,不然的话就会相当于正则符.的功能匹配任意字符了)
ip add | grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'
ip add | grep -oP '\b(\d{1,}\.)(\d{1,3}\.)(\d{1,3}\.)\d{1,3}\b'

匹配身份证号(以下两个命令都可以匹配)
grep -Eo '[0-9]{17}[0-9X]{1}' 1.txt
grep -Eo '[0-9X]{18}' 1.txt

零宽断言示例,去掉前后项取中间项
echo 44178124592350982X |grep -Po '(?<=4)[0-9]{16}(?=X)'
![]()