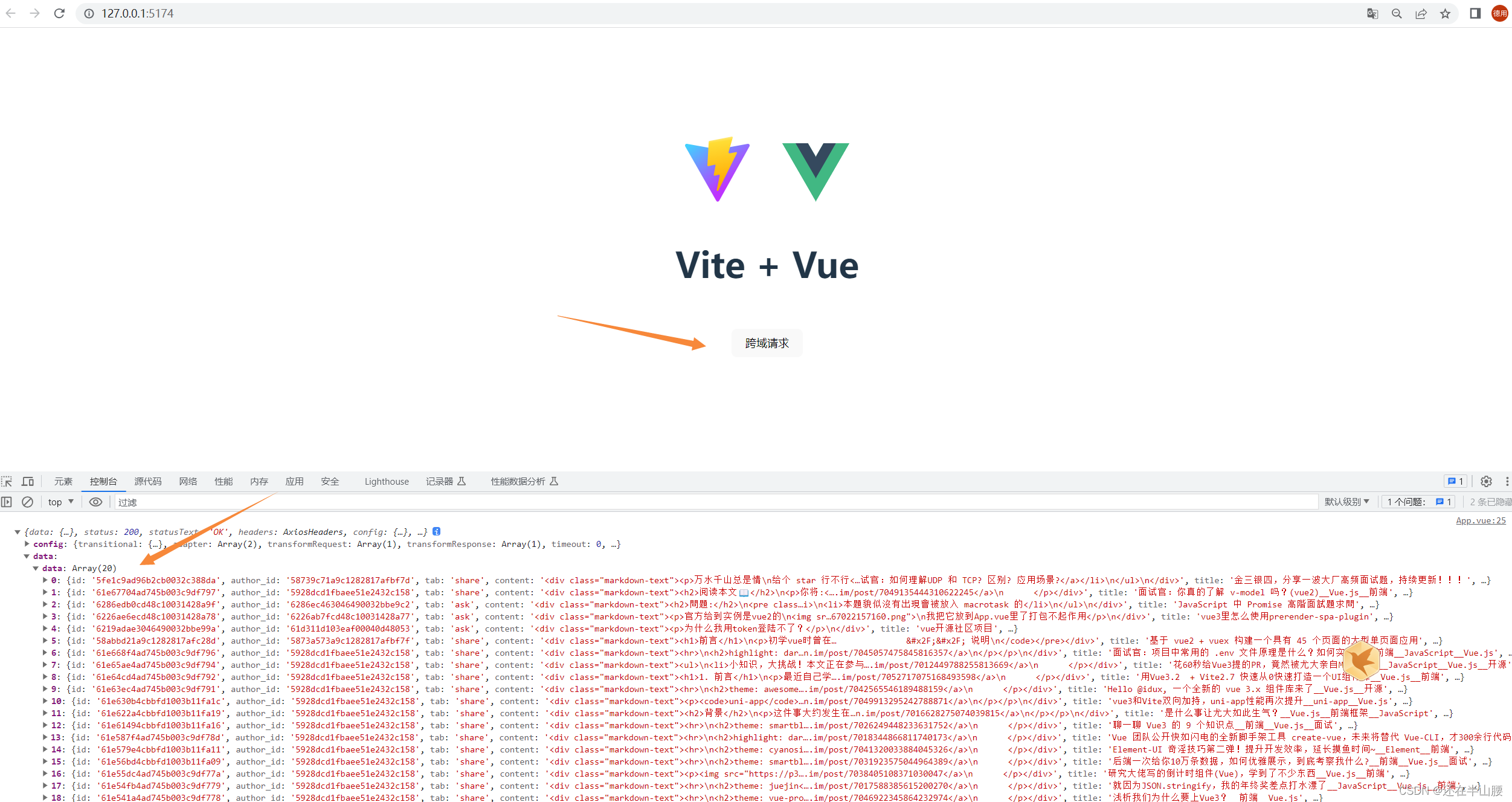
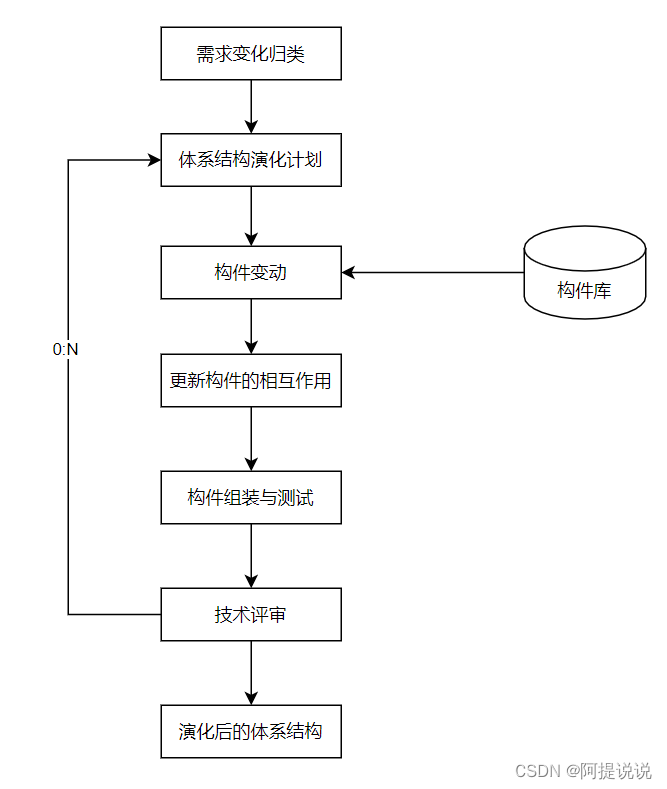
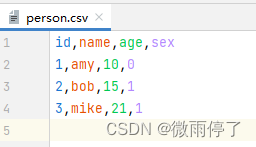
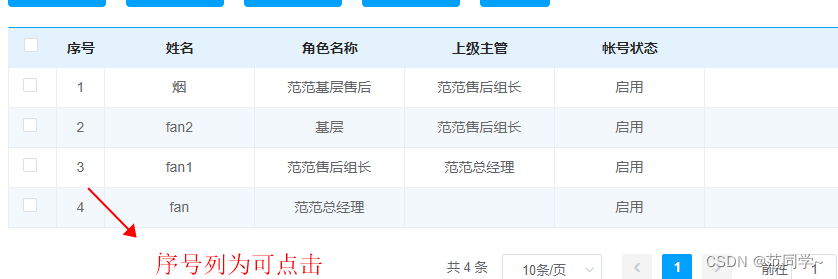
SELECT:语句用于从数据库中选取数据
从 "Websites" 表中选取 "name" 和 "country" 列
SELECT name,country FROM Websites从 "Websites" 表中选取所有列
SELECT * FROM Websites;SELECT DISTINCT:用于返回唯一不同的值
从 "Websites" 表的 "country" 列中选取唯一不同的值,也就是去掉 "country" 列重复值
SELECT DISTINCT country FROM Websites;WHERE:用于过滤记录
从 "Websites" 表中选取国家为 "CN" 的所有网站
SELECT * FROM Websites WHERE country='CN'
// 'CN' 文本字段使用了单引号。如果是数值字段,请不要使用引号AND & OR:基于一个以上的条件对记录进行过滤
从 "Websites" 表中选取国家为 "CN" 且alexa排名大于 "50" 的所有网站
SELECT * FROM Websites WHERE country='CN' AND alexa > 50;从 "Websites" 表中选取国家为 "USA" 或者 "CN" 的所有客户
SELECT * FROM Websites WHERE country='USA' OR country='CN'从 "Websites" 表中选取 alexa 排名大于 "15" 且国家为 "CN" 或 "USA" 的所有网站
SELECT * FROM Websites WHERE alexa > 15 AND (country='CN' OR country='USA')ORDER BY:用于对结果集进行排序
从 "Websites" 表中选取所有网站,并按照 "alexa" 列排序
SELECT * FROM Websites ORDER BY alexa;从 "Websites" 表中选取所有网站,并按照 "alexa" 列降序排序
SELECT * FROM Websites ORDER BY alexa DESC;从 "Websites" 表中选取所有网站,并按照 "country" 和 "alexa" 列排序
SELECT * FROM Websites ORDER BY country,alexa;INSERT INTO:用于向表中插入新记录
向 "Websites" 表中插入一个新行
INSERT INTO Websites (name, url, alexa, country) VALUES ('百度','https://www.baidu.com/','4','CN');向 "Websites" 表的指定的列插入数据
INSERT INTO Websites (name, url, country) VALUES ('stackoverflow', 'http://stackoverflow.com/', 'IND');UPDATE:用于更新表中的记录
把 "菜鸟教程" 的 alexa 排名更新为 5000,country 改为 USA
UPDATE Websites SET alexa='5000', country='USA' WHERE name='菜鸟教程'DELETE:用于删除表中的记录
从 "Websites" 表中删除网站名为 "Facebook" 且国家为 USA 的网站
DELETE FROM Websites WHERE name='Facebook' AND country='USA';SELECT TOP:用于规定要返回的记录的数目
从 "Websites" 表中选取头两条记录
SELECT * FROM Websites LIMIT 2从 websites 表中选取前面百分之 50 的记录
SELECT TOP 50 PERCENT * FROM WebsitesLIKE:用于在 WHERE 子句中搜索列中的指定模式
选取 name 以字母 "G" 开始的所有客户
SELECT * FROM Websites WHERE name LIKE 'G%';IN:允许在 WHERE 子句中规定多个值
选取 name 为 "Google" 或 "菜鸟教程" 的所有网站
SELECT * FROM Websites WHERE name IN ('Google','菜鸟教程');//in 与 = 的转换
select * from Websites where name in ('Google','菜鸟教程');
select * from Websites where name='Google' or name='菜鸟教程'BETWEEN:用于选取介于两个值之间的数据范围内的值
选取 alexa 介于 1 和 20 之间的所有网站
SELECT * FROM Websites WHERE alexa BETWEEN 1 AND 20;不在上面实例范围内的所有网站
SELECT * FROM Websites WHERE alexa NOT BETWEEN 1 AND 20;选取 alexa 介于 1 和 20 之间但 country 不为 USA 和 IND 的所有网站
SELECT * FROM Websites WHERE (alexa BETWEEN 1 AND 20) AND country NOT IN ('USA', 'IND');通配符:用于替代字符串中的任何其他字符
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [word] | 字符列中的任何单一字符 |
| [^word] 或 [!word] | 不在字符列中的任何单一字符 |
选取 name 以 "G" 开始,然后是一个任意字符,然后是 "o",然后是一个任意字符,然后是 "le" 的所有网站
SELECT * FROM Websites WHERE name LIKE 'G_o_le';别名:可以为表名称或列名称指定别名
指定了两个别名,一个是 name 列的别名,一个是 country 列的别名
SELECT name AS n, country AS c FROM Websites;INNER JOIN:在表中存在至少一个匹配时返回行
将返回所有网站的访问记录
SELECT Websites.name, access_log.count, access_log.date FROM Websites INNER JOIN access_log
ON Websites.id=access_log.site_id ORDER BY access_log.count;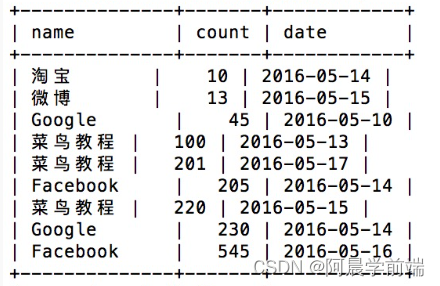
在使用 join 时,on 和 where 条件的区别
- on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
- where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
LEFT JOIN:从左表返回所有的行。如果右表中没有匹配,则结果为 NULL
Websites 作为左表,access_log 作为右表
SELECT Websites.name, access_log.count, access_log.date FROM Websites LEFT JOIN access_log
ON Websites.id=access_log.site_id ORDER BY access_log.count DESC;
RIGHT JOIN:从右表返回所有的行,即使左表中没有匹配。如果左表中没有匹配,则结果为 NULL
Websites 作为左表,access_log 作为右表
SELECT websites.name, access_log.count, access_log.date FROM websites RIGHT JOIN access_log
ON access_log.site_id=websites.id ORDER BY access_log.count DESC;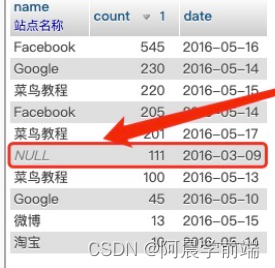
UNION:符合并两个或多个 SELECT 语句的结果
从 "Websites" 和 "apps" 表中选取所有不同的country(只有不同的值)
SELECT country FROM Websites UNION SELECT country FROM apps ORDER BY country
//UNION 不能用于列出两个表中所有的countryCREATE DATABASE:用于创建数据库
创建一个名为 "my_db" 的数据库
CREATE DATABASE my_dbCREATE TABLE:用于创建数据库中的表
创建一个名为 "Persons" 的表,包含五列:PersonID、LastName、FirstName、Address 和 City
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)NOT NULL 约束:强制列不接受 NULL 值
UNIQUE 约束:唯一标识数据库表中的每条记录
PRIMARY KEY 约束:唯一标识数据库表中的每条记录。
- UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。PRIMARY KEY 约束拥有自动定义的 UNIQUE 约束。
- 请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
FOREIGN KEY 约束:一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)
AUTO INCREMENT:会在新记录插入表中时生成一个唯一的数字
AVG() 函数:返回数值列的平均值
从 "access_log" 表的 "count" 列获取平均值
SELECT AVG(count) AS CountAverage FROM access_log;选择访问量高于平均访问量的 "site_id" 和 "count"
SELECT site_id, count FROM access_log
WHERE count > (SELECT AVG(count) FROM access_log);COUNT() 函数:返回匹配指定条件的行数
计算 "access_log" 表中 "site_id"=3 的总访问量
SELECT COUNT(count) AS nums FROM access_log WHERE site_id=3;计算 "access_log" 表中总记录数
SELECT COUNT(*) AS nums FROM access_log;FIRST() 函数:返回指定的列中第一个记录的值
选取 "Websites" 表的 "name" 列中第一个记录的值
SELECT name AS FirstSite FROM Websites LIMIT 1;LAST() 函数:返回指定的列中最后一个记录的值
选取 "Websites" 表的 "name" 列中最后一个记录的值
SELECT name FROM Websites ORDER BY id DESC LIMIT 1;MAX() 函数:返回指定列的最大值
"Websites" 表的 "alexa" 列获取最大值
ELECT MAX(alexa) AS max_alexa FROM WebsitesMIN() 函数:返回指定列的最小值
从 "Websites" 表的 "alexa" 列获取最小值
SELECT MIN(alexa) AS min_alexa FROM WebsitesSUM() 函数:返回数值列的总数
查找 "access_log" 表的 "count" 字段的总数
SELECT SUM(count) AS nums FROM access_logGROUP BY:结合一些聚合函数来使用,根据一个或多个列对结果集进行分组
统计 access_log 各个 site_id 的访问量
SELECT site_id, SUM(access_log.count) AS nums FROM access_log GROUP BY site_idGROUP BY 多表连接
SELECT Websites.name,COUNT(access_log.aid) AS nums FROM access_log
LEFT JOIN Websites ON access_log.site_id=Websites.id GROUP BY Websites.nameHAVING:可以让我们筛选分组后的各组数据;在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用
想要查找总访问量大于 200 的网站
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log
INNER JOIN Websites ON access_log.site_id=Websites.id)
GROUP BY Websites.name HAVING SUM(access_log.count) > 200想要查找总访问量大于 200 的网站,并且 alexa 排名小于 200
SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites
INNER JOIN access_log ON Websites.id=access_log.site_id
WHERE Websites.alexa < 200 GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;where 和having之后都是筛选条件,但是有区别的
- where在group by前, having在group by 之后
- 聚合函数(avg、sum、max、min、count),不能作为条件放在where之后,但可以放在having之后
UCASE() 函数:把字段的值转换为大写
从 "Websites" 表中选取 "name" 和 "url" 列,并把 "name" 列的值转换为大写
SELECT UCASE(name) AS site_title, url FROM Websites;LCASE() 函数:把字段的值转换为小写
从 "Websites" 表中选取 "name" 和 "url" 列,并把 "name" 列的值转换为小写
SELECT LCASE(name) AS site_title, url FROM Websites