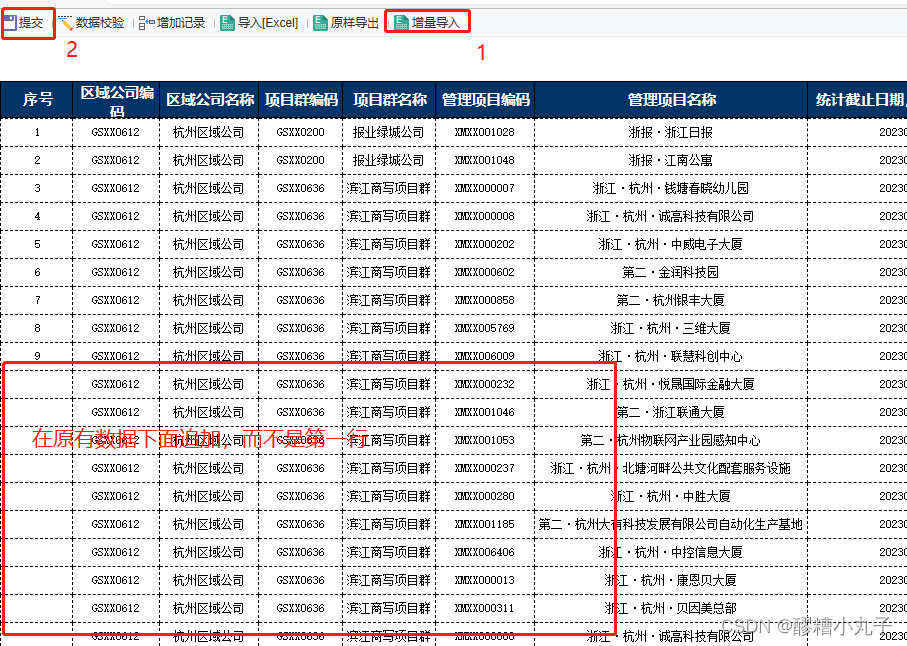
有时候我们会将csv文件的某列对应某列(或这某几列);如{A:[B,C,D,E]},说白了就是一个键对应的值是一个列表,但是有时候我们的值在表头中位置不一致,这时候我们就需要先获取每一个字段的索引值,这样程序就会通过索引值自动找到对应的值在表头中的索引。
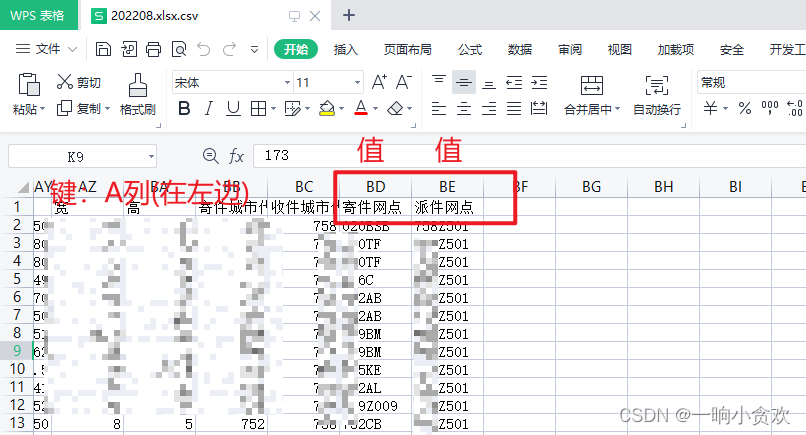
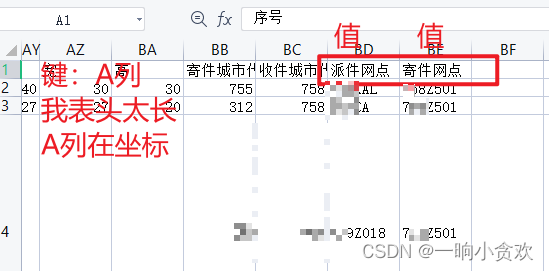
如下图(我故意写反了):
1、将A列作为键
2、将[寄件网点,派件网点]作为值,但是位置不一定
解决方案,找到索引,前提是字段必须在表头中
import csv
with open('./原始账单大网(csv)/' + f, newline='', encoding='utf-8') as csvfile:
# 读取 CSV 文件内容
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# 遍历 CSV 文件中的每一行数据
zd_list = ['寄件网点', '派件网点']
indexs_list = []
for row in reader:
count += 1
if count == 1:
for z in zd_list:
# print(row.index(z))
indexs_list.append(row.index(z))
else:
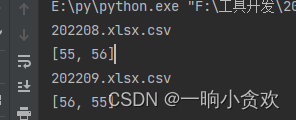
print(indexs_list)
break
成功找到
下面是作json文件
1、 list_a.append((row[0], row[indexs_list[0]] + “=” + row[indexs_list[1]]))
2、row[0],这个就是我的A列,也就是键
3、 row[indexs_list[0]] + “=” + row[indexs_list[1]],这个就是我的值[‘寄件网点’, ‘派件网点’],中间通过“=”,等号连接,方便split切割,当然可以继续添加其他字段
import json
import os
from collections import defaultdict
import csv
def write_json():
for f in os.listdir('./数据源(csv)/'):
list_a = []
d = defaultdict(list)
count = 0
print(f)
with open('./数据源(csv)/' + f, newline='', encoding='utf-8') as csvfile:
# 读取 CSV 文件内容
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# 遍历 CSV 文件中的每一行数据
zd_list = ['寄件网点', '派件网点']
indexs_list = []
for row in reader:
count += 1
if count == 1:
for z in zd_list:
# print(row.index(z))
indexs_list.append(row.index(z))
else:
# print(indexs_list)
# 处理每一行数据
# print(row)
list_a.append((row[2], row[indexs_list[0]] + "=" + row[indexs_list[1]]))
for key, value in list_a:
d[key].append(value) # 省去了if判断语句
with open(f"./json文件/{f}.json", "w", encoding="utf-8") as f_w:
f_w.write(json.dumps(d, ensure_ascii=False))
print(f"{f},转换json成功")
然后是将刚刚的json文件合并成一个
def merge_json():
# 定义一个空的字典,用于存储合并后的json数据
merged_data = {}
# 遍历所有的json文件,将数据合并到merged_data中
for file in os.listdir("./json文件/", ):
with open("./json文件/" + file, 'r', encoding="utf-8") as f:
data = json.load(f)
merged_data.update(data)
# 将合并后的json数据写入到merged_file中
with open("合并json/res.json", 'w', encoding="utf-8") as f:
json.dump(merged_data, f, ensure_ascii=False) # 防止中文乱码
# merge_json()
最后是匹配
import json
import os
import numpy as np
import openpyxl
import pandas
wb = openpyxl.load_workbook("./模板(勿动)/"+os.listdir("./模板(勿动)/")[0])
ws = wb.active
with open("合并json/res.json", "r", encoding="utf-8")as f:
res = json.load(f)
# print(res['SF16xxxxxxx'])
df = pandas.read_excel("./数据源/"+os.listdir("./数据源/")[0],usecols="A",dtype=str,keep_default_na='')
ydh_list = np.asarray(df.stack())
for y in ydh_list:
# print(y)
res2 = res.get(y,"-")
if res2 != "-":
ws.append([y,res2[0].split("=")[0],res2[0].split("=")[1]])
else:
ws.append([y,'',''])
wb.save("./匹配结果.xlsx")
全部匹配到,当然匹配不到可以为空,代码里我也加了
![[Flask] Flask的请求与响应](https://img-blog.csdnimg.cn/0742a04b8a1d4fb982659866335bbcba.png)