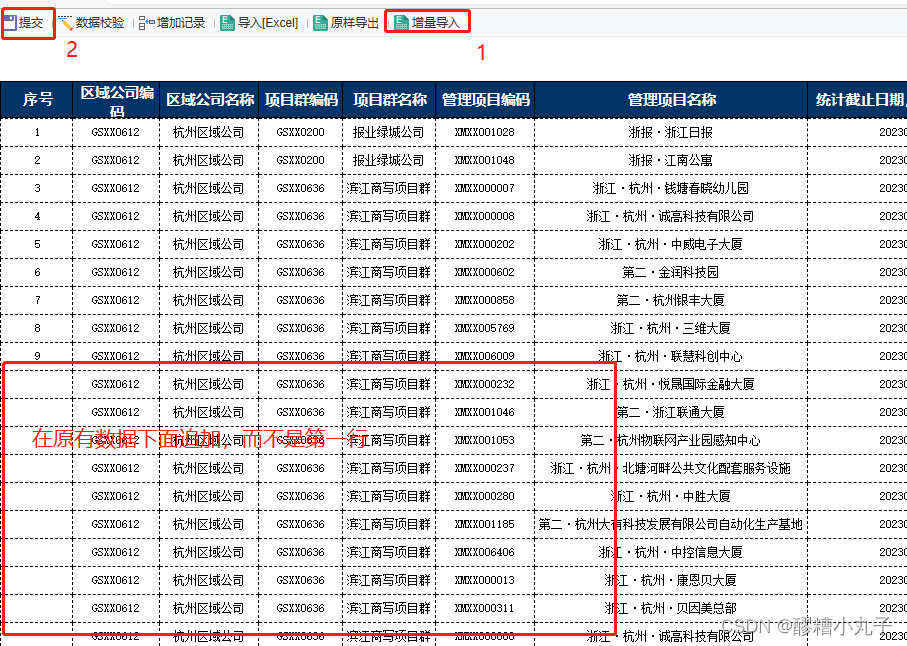
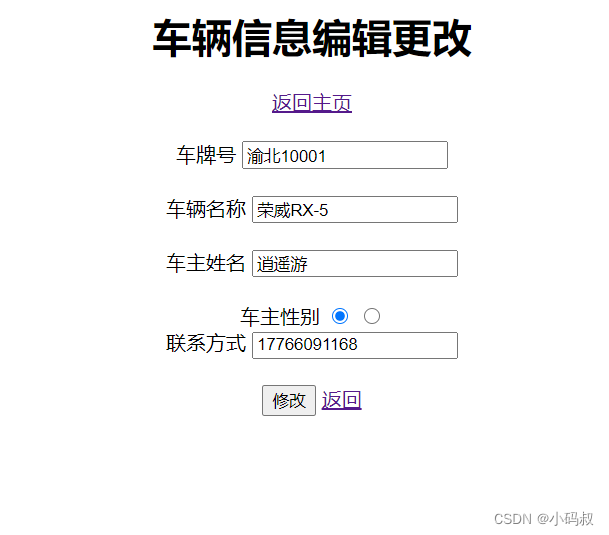
在未优化的矩阵乘法C+=A*B中,a、b和c分别是指向矩阵 A、B 和 C 的全局内存的指针;blockDim.x、blockDim.y、 和TILE_DIM都等于 w。wxw-thread 块中的每个线程计算 C 的tile中的一个元素,row并且col是由特定线程计算的 C 中元素的行和列。该for循环i将 A 的行乘以 B 的列,然后将其写入 C。
其中 A 的维度为 Mxw,B 的维度为 wxN,C 的维度为 MxN。为了保持内核简单,M 和 N 是 32 的倍数,因为当前设备的warp size (w) ,即warp内thread数量是 32。
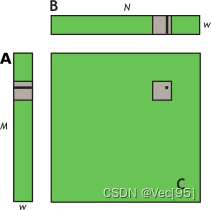
这里启动 N/w x M/w 块的网格,其中每个线程块根据 A 的同一tile和 B 的同一tile计算 C 中不同tile的元素。
每个wxw-thread 块中的每个线程计算 C 的图块tile中的一个元素,row和col是由特定线程计算的 C 中元素的行和列。该for循环i将 A 的行乘以 B 的列,然后将其写入 C。
使用全局内存,不做任何优化的代码如下,注意这个计算是在每个C的tile中都进行:
__global__ void simpleMultiply(float *a, float* b, float *c,
int N)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int i = 0; i < TILE_DIM; i++) {
sum += a[row*TILE_DIM+i] * b[i*N+col];
}
c[row*N+col] = sum;
}由于A 的tile中的每个元素是行主序的读取,因此仅以完全合并的方式(不浪费带宽)从全局内存读取一次到共享内存。在循环的每次迭代中for循环中,共享内存中的值会广播到 warp 中的所有线程。在将A 的图块读入共享内存后要执行__syncthreads()来同步数据。使用共享内存来装A,但不装B的代码如下:
__global__ void coalescedMultiply(float *a, float* b, float *c,
int N)
{
__shared__ float aTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x];
__syncwarp();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i]* b[i*N+col];
}
c[row*N+col] = sum;
}为了进一步改进,接下来使用共享内存来提高矩阵B的全局内存加载效率。在计算矩阵C的tile的每一行时,读取B的整个tile进入共享内存,可以消除对 Btile的重复读取。图和代码如下:
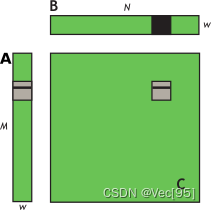
__global__ void sharedABMultiply(float *a, float* b, float *c,
int N)
{
__shared__ float aTile[TILE_DIM][TILE_DIM],
bTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x];
bTile[threadIdx.y][threadIdx.x] = b[threadIdx.y*N+col];
__syncthreads();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i]* bTile[i][threadIdx.x];
}
c[row*N+col] = sum;
}