文章题为
「A transformer-based representation learning model with unified processing of multimodal input for clinical diagnostics」
https://www.nature.com/articles/s41551-023-01045-x
(arXiv版链接: https://arxiv.org/abs/2306.00864)
https://github.com/RL4M/IRENE
该研究聚焦于医学人工智能,提出了一种针对临床疾病诊断的多模态表征学习模型。
主要使用了 肺部图片与临床文本信息作为多模态的输入;
1. 研究背景
1.1 introduction
在临床诊断中,为了做出准确的决策,医生通常需要综合考虑患者的主诉、医学影像和实验室化验结果等多模态信息。然而,在基于机器学习的智能医学诊断中,如何更好地解读医学影像及相关临床信息仍有待商榷。当前的多模态临床决策支持系统主要采用非统一的方式来融合多模态数据。
根据融合阶段的不同,我们可以将传统的非统一的多模态融合方法划分为两个大类,即早期和晚期融合。然而,无论是早期还是晚期融合都选择将多模态诊断过程分离成两个相对独立的阶段:对每种模态单独进行特征抽取和多个模态特征的融合。这种设计有一个天然的局限性:无法发现和编码不同模态之间的内部关联。另一个潜在的问题是,传统的多模态人工智能诊断方法往往需要对文本进行结构化,而文本结构化过程存在标注流程复杂、劳动密集等诸多问题。
与此同时,基于Transformer架构的深度学习方法正在重塑自然语言处理和计算机视觉领域。与卷积神经网络和词嵌入算法相比,Transformer对输入数据的形式几乎没有假设,因此有望从多模态输入数据中学习更高质量的特征表达。而且,Transformer的基本架构组件(即自注意力模块)在不同模态上几乎保持不变,为构建统一且灵活的模型提供了更好的机会。
1.2 contribution
IRENE具有以下三个优点:
-
使用统一架构进行多模态表征学习,避免了分离的表征学习路径;
-
无需进行繁琐的文本结构化步骤,直接在原始文本上进行表征学习;
-
通过双向多模态注意力机制发现和编码不同模态之间的相互关联。
1.3 related work
2. 方法
2.1 文本信息与图片的输入
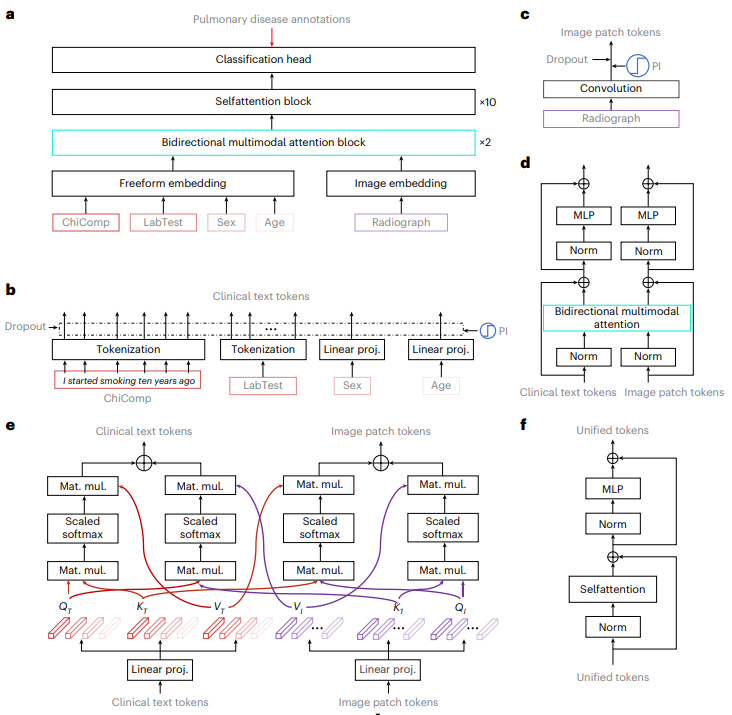
2.2 统一各个模态表示
IRENE的核心是统一的多模态诊断Transformer(即MDT)和双向多模态注意力机制。MDT是一种新的Transformer堆叠结构,直接从多模态输入数据中生成诊断结果。
与之前的非统一方法不同,这种新算法通过渐进地从多模态临床信息中学习整体表征,放弃了单独学习各种模态特征的技术路线。此外,MDT赋予IRENE在非结构化原始文本上进行表征学习的能力,避免了非统一方法中繁琐的文本结构化步骤。
2.3 处理模态的差异
为了更好地处理模态之间的差异,IRENE引入了双向多模态注意力机制,通过发现和编码不同模态之间的相互关联,将模态独立的特征表达和面向诊断的整体表征联系起来。这个明确的学习和编码过程可以看作是MDT中整体多模态表征学习过程的补充。
3. 实验
3.1 实验环境设置
3.2 对比实验
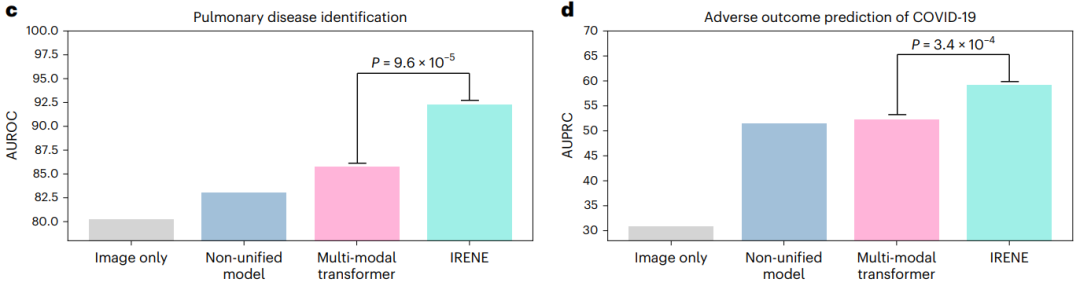
- IRENE在多模态医学诊断中比之前非统一的诊断范式更有效。
IRENE在诊断肺部疾病方面,相比于早期融合和晚期融合方法,平均提升了9%和10%。同时,IRENE在八种疾病上实现了至少约3%的性能提升,并显著改善了四种疾病(支气管扩张、气胸、ILD和结核病)的诊断效果,将其AUROC提高了超过10%。除此之外,IRENE的上述优势在COVID-19患者不良临床结局预测任务中得到了部分验证。相比于早期融合和晚期融合方法,IRENE将平均性能分别提升了7%和9%。
- IRENE提供了一种更好的适用于多模态医学诊断的Transformer架构。
与GIT和Perceiver相比,IRENE在医学诊断场景中具有明显优势。GIT在大规模多模态预训练方面存在困难,而IRENE可以通过双向多模态注意力机制有效利用有限的医学数据和互补的语义信息从而减少对预训练数据的依赖。此外,Perceiver将多模态输入简单串联,所以难以学习到IRENE的融合表征,这导致输入中占比较大的模态对最终诊断有较大的影响。IRENE利用双向多模态注意力机制学习整体多模态表征,平衡了多种模态数据对特征表达的影响,从而在不同任务中展现出令人满意的性能。
- IRENE简化了传统工作流程中对文本结构化的依赖。
在传统的非统一的多模态人工智能医学诊断方法中,处理非结构化文本的常规方式是进行文本结构化,其具体流程严重依赖于人工规则和现代自然语言处理工具的辅助。相比之下,IRENE可以接受非结构化的临床文本直接作为输入,从而降低了对繁琐的文本结构化步骤的依赖。
3.3 消融实验
3.3.1 肺部疾病识别任务
如表1所示,IRENE在识别肺部疾病方面明显优于仅依赖图像的模型、传统的非统一的诊断范式、以及两种最新的基于Transformer的多模态模型(即Perceiver和GIT)。
从实验指标上看,IRENE取得了最高的平均AUROC为0.924(95% CI:0.921,0.927),比仅将X光片作为输入的图像模型(0.805,95% CI:0.802,0.808)高出约12%。
与非统一的早期融合(0.835,95% CI:0.832,0.839)和晚期融合(0.826,95% CI:0.823,0.828)的诊断策略相比,IRENE取得了至少9%的性能优势。
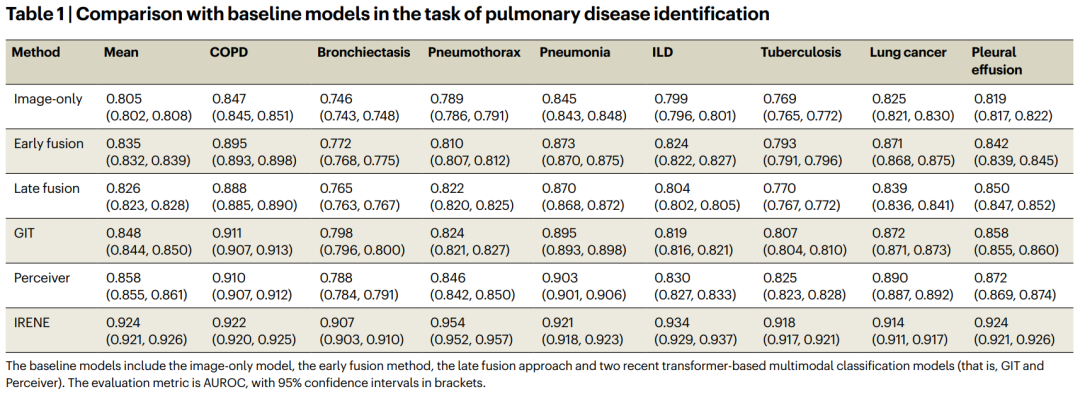
如果我们将IRENE与GIT(0.848,95% CI:0.844,0.850)比较,我们可以发现IRENE在AUROC上的优势超过7%。
即使与DeepMind开发的基于Transformer的多模态模型Perceiver比较,IRENE仍然取得了相当有竞争力的结果,超过了Perceiver(0.858,95% CI:0.855,0.861)6%。
当我们着眼于每种疾病,并将IRENE与所有五种基线中之前的最好结果进行比较时,我们发现在所有八种肺部疾病中,IRENE在支气管扩张(12%)、气胸(10%)、间质性肺疾病(ILD,10%)和结核病(9%)方面取得了最大的改进。
3.3.2 cov19识别任务
对COVID-19患者的分诊大量依赖于对胸部CT扫描和其他非影像临床信息的联合解读。
在这种情况下,IRENE显示出比它在肺部疾病识别任务中更大的优势。
如表2所示,IRENE在预测COVID-19患者的三种不良临床结局(即入住ICU、使用呼吸机、死亡)上面取得了令人印象深刻的性能提升。
在平均AUPRC方面,IRENE(0.592,95% CI:0.500, 0.682)的表现大幅度优于仅依赖影像的模型(0.307,95% CI:0.237, 0.391),
早期融合模型(0.521,95% CI:0.435, 0.614)和
晚期融合模型(0.503,95% CI:0.422, 0.598),分别几乎提高了29%,7%和9%。
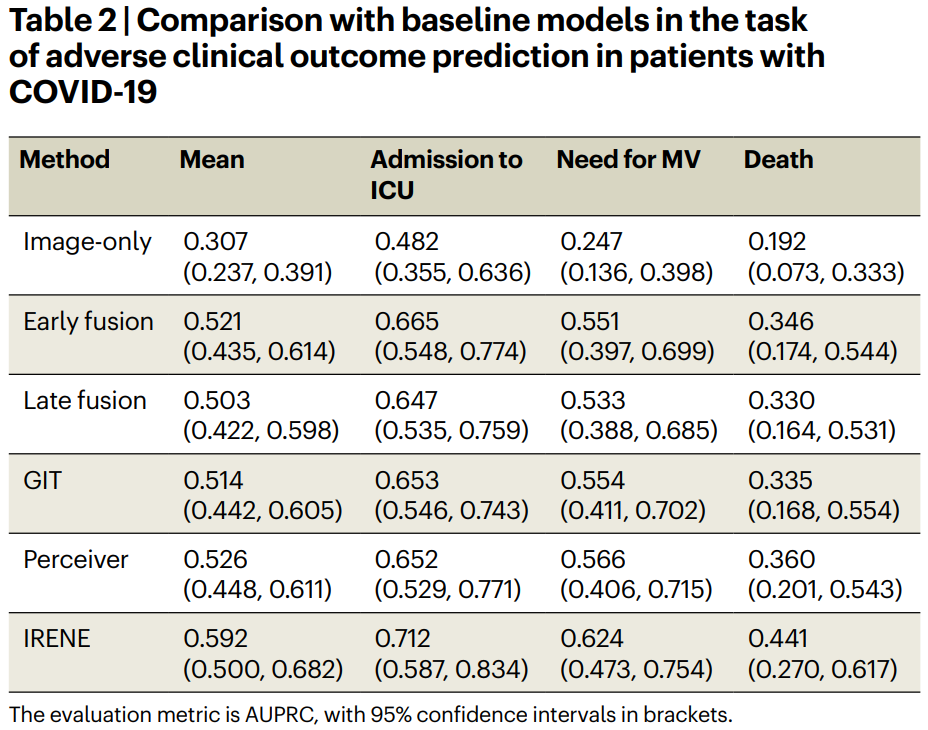
就特定的临床结果而言,IRENE(0.712,95% CI:0.587, 0.834)在预测入住ICU方面,比非统一的早期融合方法(0.665,95% CI:0.548, 0.774)获得了约5%的AUPRC提升。
同样,在预测是否对新冠病人使用呼吸机时,IRENE相比早期融合模型,取得了超过6%的性能提升。相较于仅依赖影像的模型(0.192,95% CI:0.073, 0.333)、早期融合模型(0.346,95% CI:0.174, 0.544)和晚期融合模型(0.335,95% CI:0.168, 0.554),IRENE(0.441,5% CI:0.270, 0.617)可以更准确的预测新冠病人的死亡结局。与两种基于Transformer的多模态模型(即GIT和Perceiver)相比,IRENE在平均性能上可以取得超过6%的优势。
4. 总结
结合最新的自然语言处理技术和图像识别技术,IRENE可以在医学诊断中起到重要的作用。它通过统一的多模态诊断Transformer和双向多模态注意力机制,渐进学习多模态临床数据的整体表征,放弃了单独学习各种模态特征的技术路线。在现实世界中,IRENE可以帮助简化患者护理流程,如患者分流和区分普通感冒患者与需要紧急干预的严重情况患者。此外,在诊断不确定或复杂的情况下,IRENE还可以作为医生的辅助工具,提供诊断建议,进一步增强医生的判断能力。除此之外,IRENE在医疗资源匮乏的地区具有重要价值。
文章的通讯作者是香港大学的俞益洲教授、四川大学华西医学院的王成弟教授、澳门科技大学的张康教授和四川大学华西医学院的李为民院长;第一作者为香港大学博士研究生周洪宇。
6月12日,国际顶级学术期刊《自然-生物医学工程》(英文名:Nature Biomedical Engineering)上线了一项由香港大学、四川大学华西医学院、深睿医疗和澳门科技大学合作完成的研究,