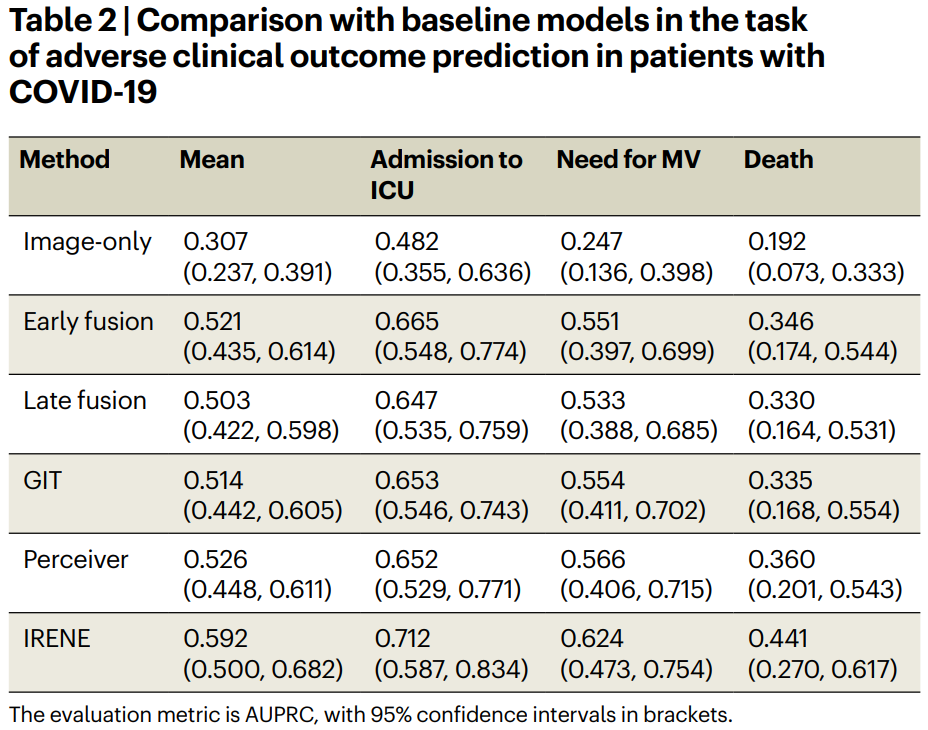
page cache 在内核中的数据结构是一个叫做 address_space 的结构体:struct address_space。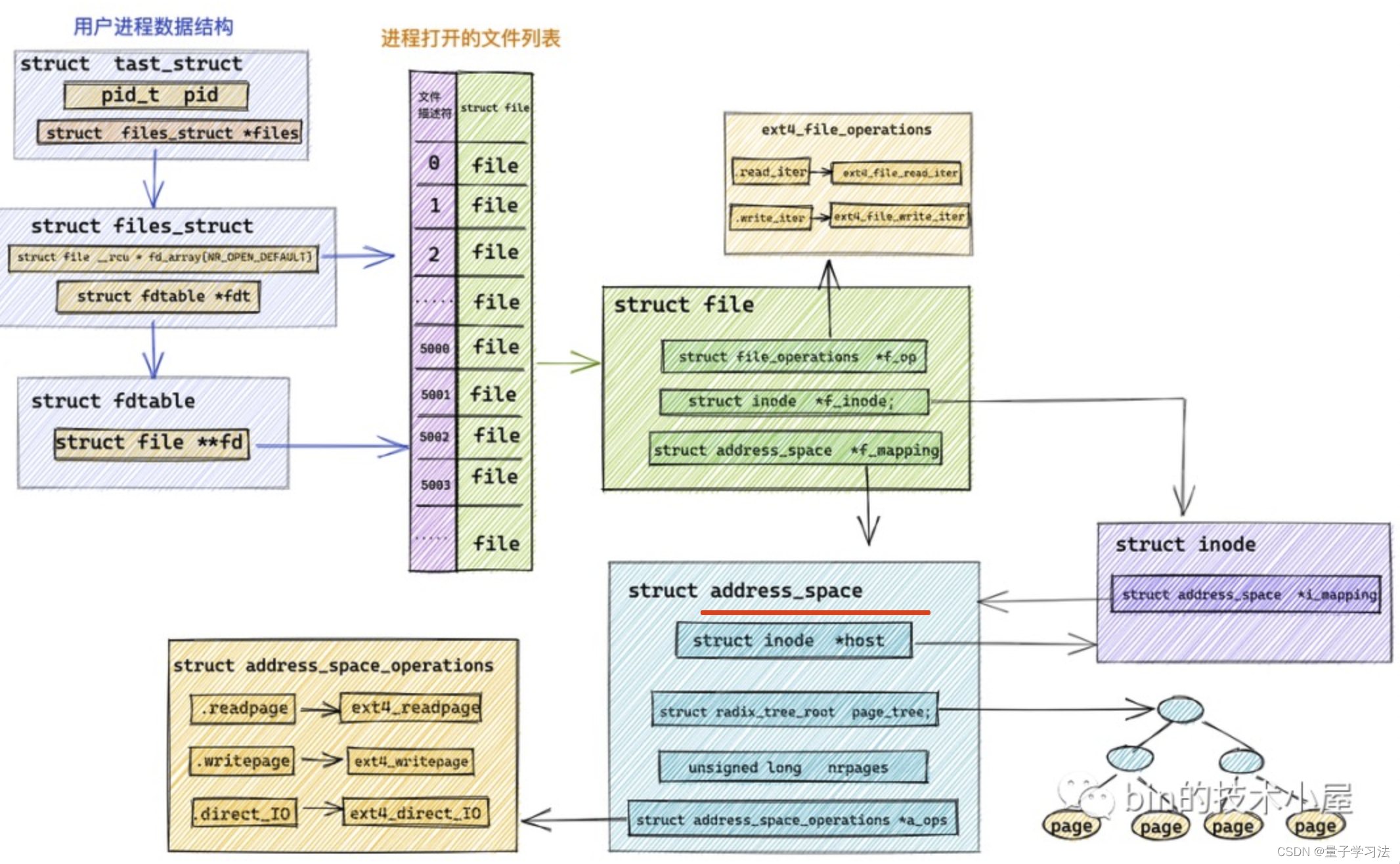
struct address_space {
struct inode *host; // 关联 page cache 对应文件的 inode
struct radix_tree_root page_tree; // 这里就是 page cache。里边缓存了文件的所有缓存页面
spinlock_t tree_lock; // 访问 page_tree 时用到的自旋锁
unsigned long nrpages; // page cache 中缓存的页面总数
..........省略..........
const struct address_space_operations *a_ops; // 定义对 page cache 中缓存页的各种操作方法
..........省略..........
}基树 radix_tree (和mysql中B+很类似)
struct radix_tree_node {
void __rcu *slots[RADIX_TREE_MAP_SIZE]; //包含 64 个指针的数组。用于指向下一层节点或者缓存页
unsigned char offset; //父节点中指向该节点的指针在父节点 slots 数组中的偏移
unsigned char count;//记录当前节点的 slots 数组指向了多少个节点
struct radix_tree_node *parent; // 父节点指针
struct radix_tree_root *root; // 根节点
..........省略.........
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; // radix_tree 中的二维标记数组,用于标记子节点的状态。
};radix_tree 的标记

PG_dirty 和 PG_writeback 就是缓存页的状态,而内核不仅仅是需要在 page cache 中高效搜索请求数据所在的缓存页,还需要高效搜索给定状态的缓存页。
比如:快速查找 page cache 中的所有脏页。但是如果此时 page cache 中的大部分缓存页都不是脏页,那么顺序遍历 radix_tree 的方式就实在是太慢了,所以为了快速搜索到脏页,就需要在 radix_tree 中的每个节点 radix_tree_node 中加入一个针对其所有子节点的脏页标记,如果其中一个子节点被标记被脏时,那么这个子节点对应的父节点 radix_tree_node 结构中的对应脏页标记位就会被置 1 。
而用来存储脏页标记的正是上小节中提到的 tags 二维数组。其中第一维 tags[] 用来表示标记类型,有多少标记类型,数组大小就为多少,比如 tags[0] 表示 PG_dirty 标记数组,tags[1] 表示 PG_writeback 标记数组。

-
内核首先调用 find_get_entry 方法根据缓存页的 offset 到 page cache 中去查找看请求的文件页是否已经在页高速缓存中。如果存在直接返回。
-
如果请求的文件页不在 page cache 中,内核则会首先会在物理内存中分配一个内存页,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。
-
随后会通过 address_space_operations 重定义的 readpage 激活块设备驱动从磁盘中读取请求数据,然后用读取到的数据填充新分配的内存页。
page cache 中查找缓存页
-
内核首先调用 find_get_entry 方法根据缓存页的 offset 到 page cache 中去查找看请求的文件页是否已经在页高速缓存中。如果存在直接返回。
-
如果请求的文件页不在 page cache 中,内核则会首先会在物理内存中分配一个内存页,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。
-
随后会通过 address_space_operations 重定义的 readpage 激活块设备驱动从磁盘中读取请求数据,然后用读取到的数据填充新分配的内存页。
文件页的预读
-
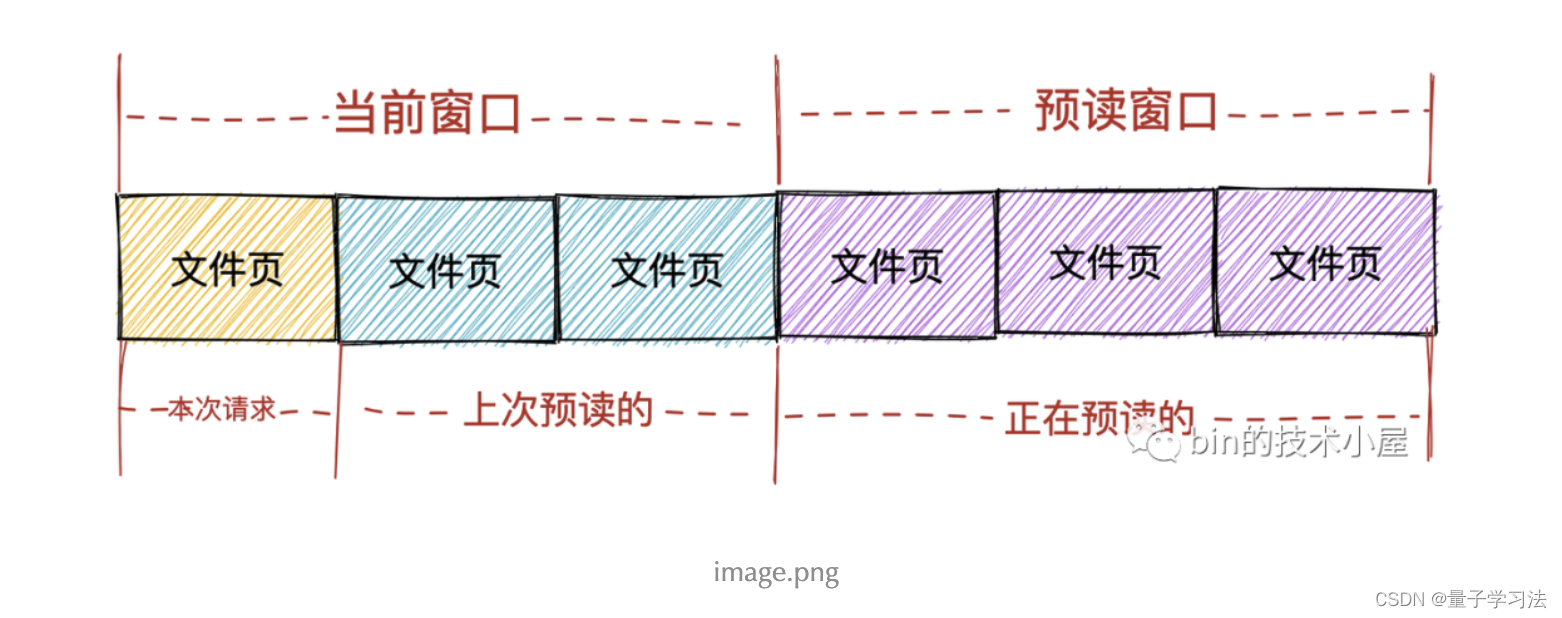
当前窗口(current window): 表示进程本次文件请求可以直接读取的页面集合,这个集合中的页面全部已经缓存在 page cache 中,进程可以直接读取返回。当前窗口中包含进程本次请求的文件页以及上次内核预读的文件页集合。表示进程本次可以从 page cache 直接获取的页面范围。
-
预读窗口(ahead window):预读窗口的页面都是内核正在预读的文件页,它们此时并不在 page cache 中。这些页面并不是进程请求的文件页,但是内核根据空间局部性原理假定它们迟早会被进程请求。预读窗口内的页面紧跟着当前窗口后面,并且内核会动态调整预读窗口的大小(有点类似于 TCP 中的滑动窗口)。
触发内核进行文件预读的场景:
-
当进程采用 Buffered IO 模式通过系统调用 read 进行文件读取时,内核会触发预读。
-
通过 POSIX_FADV_WILLNEED 参数执行系统调用 posix_fadvise,会通知内核这个指定范围的文件页不就将会被访问。触发预读。
-
当进程显示执行 readahead() 系统调用时,会显示触发内核的预读动作。
-
当内核为内存文件映射区域分配一个物理页面时,会触发预读。关于内存映射的相关内容,笔者会在后面的文章为大家详细介绍。
-
和 posix_fadvise 一样的道理,系统调用 madvise 主要用来指定内存文件映射区域的访问模式。可通过 advice = MADV_WILLNEED 通知内核,某个文件内存映射区域中的指定范围的文件页在不久将会被访问。触发预读。
预读算法逻辑中,内核通过 struct file_ra_state 结构中封装的文件预读信息来判断文件的读取是否为顺序读。比如:
-
通过检查 ra->prev_pos 和 offset 是否相同,来判断当前请求页是否和最近一次请求的页相同,如果重复访问同一页,预读就会停止。
-
通过检查 ra->prev_pos 和 offset 是否相邻,来判断进程是否顺序读取文件。如果是顺序访问文件,预读就会增加。
-
当进程第一次访问文件时,并且请求的第一个文件页在文件中的偏移量为 0 时表示进程从头开始读取文件,那么内核就会认为进程想要顺序的访问文件,随后内核就会从文件的第一页开始创建一个新的当前窗口,初始的当前窗口总是 2 的次幂,窗口具体大小与进程的读操作所请求的页数有一定的关系。请求页数越大,当前窗口就越大,直到最大值 ra->ra_pages 。
-
相反,当进程第一次访问文件,但是请求页在文件中的偏移量不为 0 时,内核就会假定进程不准备顺序读取文件,函数就会暂时禁止预读。
-
一旦内核发现进程在当前窗口内执行了顺序读取,那么预读窗口就会被建立,预读窗口总是紧挨着当前窗口的最后一页。
-
预读窗口的大小和当前窗口有关,如果已经被预读的页不在 page cache 中(可能内存紧张,预读页被回收),那么预读窗口就会是
当前窗口大小 - 2,最小值为 4。否则预读窗口就会是当前窗口的4倍或者2倍。 -
当进程继续顺序访问文件时,最终预读窗口就会变为当前窗口,随后新的预读窗口就会被建立,随着进程顺序地读取文件,预读会越来越大,但是内核一旦发现对于文件的访问 offset 相对于上一次的请求页 ra->prev_pos 不是顺序的时候,当前窗口和预读窗口就会被清空,预读被暂时禁止。