当HBase中数据量大时,可以使用HBase中提供的MapReduce程序来进行计数统计。语法如下:
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter '表名'1 启动YARN集群
启动yarn集群
start-yarn.sh启动history server
mr-jobhistory-daemon.sh start historyserver2 执行MR JOB
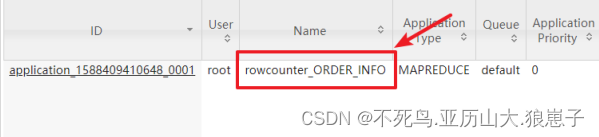
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO'通过观察YARN的WEB UI,我们发现HBase启动了一个名字为rowcounter_ORDER_INFO的作业。