一、通过程序验证系统内存分配机制
1、实验:
两个char 指针,连续先后在内存中各申请100、102个字节, 它们实际上会占用多少字节的内存空间?
如果两个char 指针,连续先后在内存中各申请200个字节, 它们实际上会占用多少字节的内存空间?
2、程序以及运行结果:
#include<iostream>
#include <unistd.h>
#include <malloc.h>
using namespace std;
int main(){
char* p1 = (char *)malloc(100);
char* p2 = (char *)malloc(102);
cout << malloc_usable_size(p1) << endl;
cout << malloc_usable_size(p2) << endl;
cout << static_cast<void *>(p1) << endl;
cout << static_cast<void *>(p2) << endl;
free(p1);
free(p2);
return 0;
}运行出的两个指针的实际占用大小都是104字节。
通过进一步的实验发现分配的内存大小和实际占用内存有如下关系:
| 分配的内存大小 | 实际占用内存大小 |
| 0 ~ 24 | 24 |
| 25 ~ 40 | 40 |
| 41 ~ 56 | 56 |
| ... | ... |
| 89~104 | 104 |
| ... | ... |
#include<iostream>
#include <unistd.h>
#include <malloc.h>
using namespace std;
int main(){
char* p1 = (char *)malloc(200);
printf("p1 = %p\n", p1);
char* p2 = (char *)malloc(200);
printf("p2 = %p\n", p2);
printf("p1内存起始地址:%x\n", p1);
printf("p2内存起始地址:%x\n", p2);
printf("使用cat /proc/%d/maps查看内存分配\n",getpid());
getchar();
free(p1);
p1 = NULL;
free(p2);
p2 = NULL;
return 0;
}实际上,除了200字节的可用空间外,还需要耗费内存控制块的空间。malloc 返回给用户态的内存起始地址比进程的多了 16 字节。这个多出来的 16 字节就是保存了该内存块的描述信息。
3、实验结果分析
通过上述实验结果可以得出,在64位系统下,我们申请的可用内存的大小会是16x + 8,分配的内存大小在每个区间内会对应相同的一个实际占用内存大小。那么这样内存分配的目的是什么呢?通过查阅相关资料得出,这样做是为了使得内存对齐,从而提升效率。除了可用空间外,还需要耗费内存控制块的空间。所以malloc实际分配的内存大小会大于我们所需要的大小,并且由字节对齐和内存控制块两方面决定。
二、内存对齐
1、前言
内存用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。内存是外存和CPU进行沟通的桥梁,是计算机中非常重要的组成部分。
执行一个程序时,先由输入设备向CPU发出操作指令,CPU接收到操作指令后,硬盘中对应的程序就会被直接加载到内存中。然后,CPU 再对内存进行寻址操作,把加载到内存中的指令翻译出来,发送操作信号给操作控制器,实现程序的运行。计算机中程序的运行都是在内存中进行,所以内存的性能的好坏会影响计算机的性能。
2、内存对齐是什么?为什么要进行内存对齐?
内存对齐就是把各种类型数据按照一定的规则在空间上排列,而不是按照顺序一个接一个的排放,这种就称为内存对齐,内存对齐是指首地址对齐。原因如下:
(1)性能方面考虑:
CPU每次访问内存是以字长为单位访问的,所以应该内存对齐。如果访问未对齐的存,CPU需要进行两次访问操作。 因此,内存对齐可以提升性能。
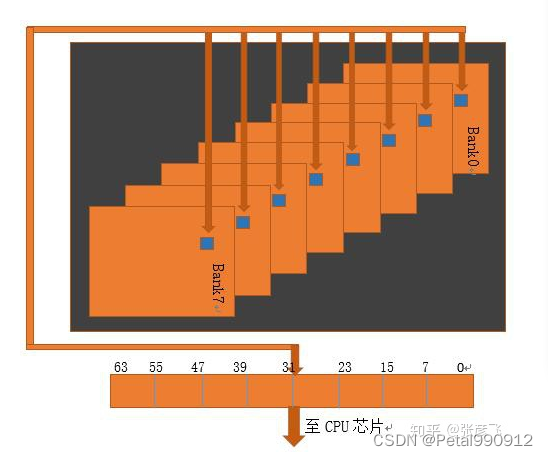
从硬件角度分析,因为内存条就是这么设计的,内存颗粒chip里的bank是并行的。一个内存是由许多chip组成,而每个chip内部是由8个bank组成。bank也就是一个二维矩阵,矩阵里的一个元素保存一个字节。
在应用程序中,内存中连续的8个字节看似是连续的,但是在物理上并不是连续的,这是由于8个bank实际上是可以并行工作的。内存对其的情况下,工作一次,把得到的数据拼起来,就能得到内存中地址连续的8个字节,从而提高了IO效率。
(2)平台方面考虑:
有些硬件平台上的CPU可以访问任意地址上的任意数据的,但有些只能在特定地址访问数据,否则会抛出硬件异常。因为不同的硬件平台具有一定的差别,因此,在编译阶段,把分配的内存对齐,就具有了可移植性了。
3、如果内存不对齐,会发生什么?
未对齐的内存访问在不同的体系结构中会有不同的效果:有些计算机可以透明地处理未对齐访问,但会大大降低效率;有一些计算机可能会产生异常,并且可用调用一个异常处理程序改正;但有些计算机产生异常,但是不能校正错误;还有一些计算机没有办法处理未对齐访问,而直接读取不正确的内存地址,导致代码漏洞,并且难以发现。
三、内存管理
1、malloc
malloc申请内存的时候,分配的是虚拟内存,会有两种方法向操作系统申请内存:
(1)通过brk()系统调用从堆分配内存
(2)通过mmap()系统调用在文件映射区分配内存
malloc() 源码里默认定义了一个阈值:(不同的 glibc 版本定义的阈值也是不同的)
-
如果用户分配的内存小于 128 KB,则通过 brk() 申请内存;
-
如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存;
malloc 函数的实质有一个将可用的内存块连接为一个链表的空闲链表,有时候也用双向链表实现。每一个内存块都有一个首部称为内存控制块mem_control_block,该MCB中记录了该内存块的一些信息,例如下一个分配块的指针、当前分配块的长度、当前分配块是否可用。
typedef struct mem_control_block
{
size_t size; //本块大小
bool free; //空闲状态
struct mem_control_block *next; //后块指针
}MCB;
MCB *g_top = NULL; //栈顶指针malloc分配时会去搜索空闲链表,为了保证分配给程序的内存的连续性,根据内存匹配原则,找到一个能满足所需空间的空闲内存块,然后把该部分空间分配出去,并且返回这部分空间的起始指针。malloc返回的指针是可用空间的起始指针,也就是跟在首部后面的地址,上述分配块的首部对于程序是不可见的。如果不能找到满足条件的内存块,就会向操作系统申请扩展堆内存,操作系统会分配新的足量内存并将其控制块压入链表栈。

这相当于用到了池化技术,实现了一个内存池。先向操作系统申请了适当内存空间,然后自己进行管理。如果不够满足实际需求,再向操作系统申请。不需要每次malloc都进行系统调用,那样开销比较大,会影响系统的性能。
系统函数brk()和sbrk()被用来调节分配给进程的数据段的内存量。 brk和sbrk底层维护了一个堆上的指针,以增量的方式管理动态内存(堆)。通常,这些函数是由一个更大的内存管理库函数(如malloc)调用的。sbrk(x) 函数,x是申请空间大小,0不申请空间,大于0申请空间,小于0 释放空间。而brk(addr),需要将堆顶指针向后移动到哪个地址addr。移动的空间大小,就是申请的空间大小。
2、free
free会将内存块重新插入到空闲链表中,并且修改内存头部的空闲状态。free只接受一个指针,却可以释放恰当大小的内存,这是因为在分配的区域的首部保存了该区域的大小。
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存:1、通过 brk() 系统调用从堆分配内存;2、通过 mmap() 系统调用在文件映射区域分配内存。采用第一种方式申请的内存,堆内存还存在,没有归还给操作系统,而是放回内存池里;采用第二种方式申请的内存会归还给操作系统。
参考文章:
详解内存对齐_Sunshine-松的博客-CSDN博客
带你深入理解内存对齐最底层原理 - 知乎
内存管理(六):一文搞懂malloc、free实现原理 - 知乎