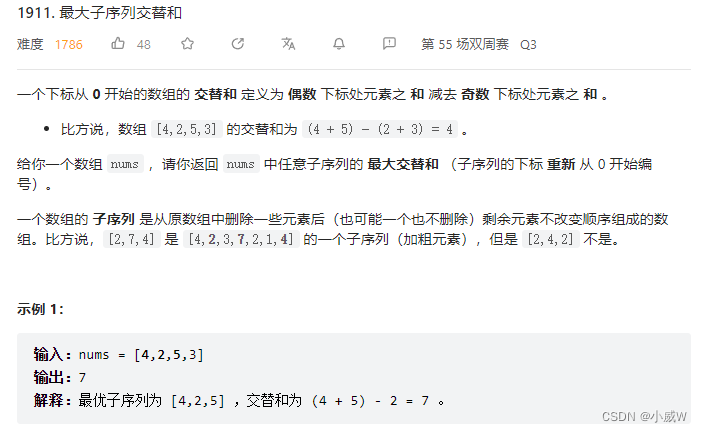
MySQL第四天
- 单行函数
- 内容
- 练习
- 聚合函数
- 内容
- 练习
单行函数
内容



#第七章 单行函数
SELECT
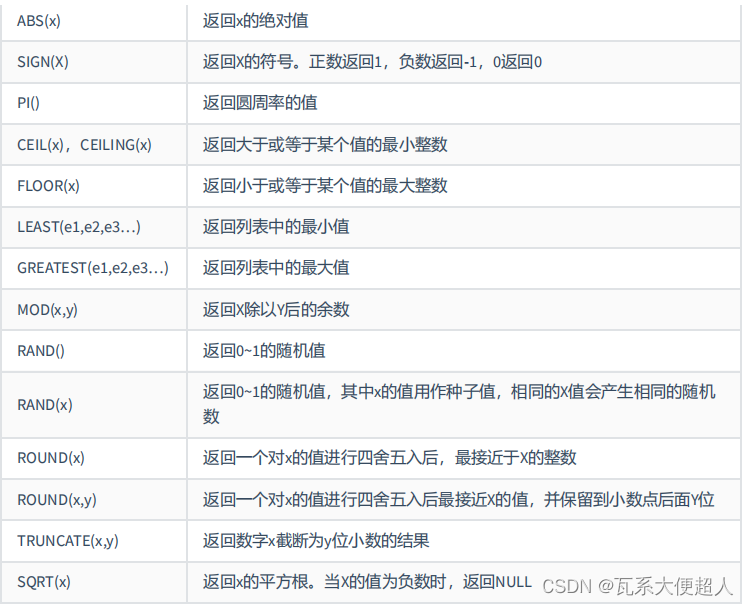
ABS(-123),ABS(32),SIGN(-23),SIGN(43),PI(),CEIL(32.32),CEILING(-43.23),FLOOR(32.32),
FLOOR(-43.23),MOD(12,5)
FROM DUAL;
#取随机数
SELECT RAND(),RAND(),RAND(10),RAND(10),RAND(-1),RAND(-1)
FROM DUAL;
#四舍五入和截断
SELECT
ROUND(12.33),ROUND(12.343,2),ROUND(12.324,-1),TRUNCATE(12.66,1),TRUNCATE(12.66,-1)
FROM DUAL;
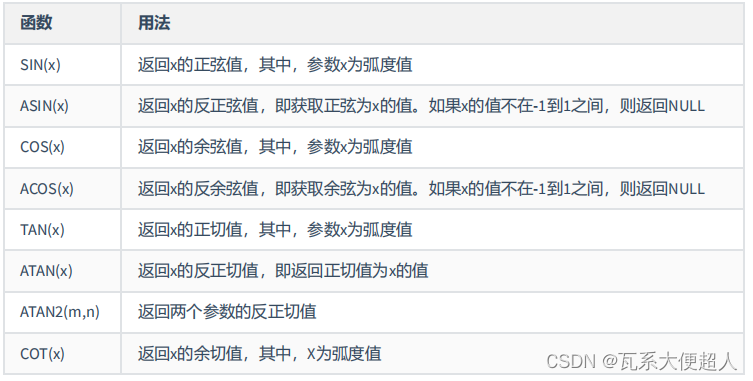
SELECT RADIANS(30),RADIANS(60),RADIANS(90),DEGREES(2*PI()),DEGREES(RADIANS(90))
FROM DUAL;
SELECT
SIN(RADIANS(30)),DEGREES(ASIN(1)),TAN(RADIANS(45)),DEGREES(ATAN(1)),DEGREES(ATAN2(1,1)
)
FROM DUAL;
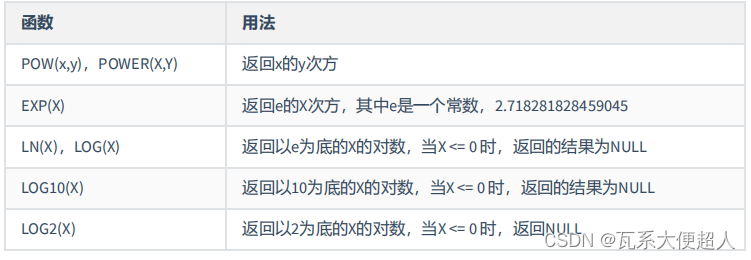
SELECT POW(2,5),POWER(2,4),EXP(2),LN(10),LOG10(10),LOG2(4)
FROM DUAL;
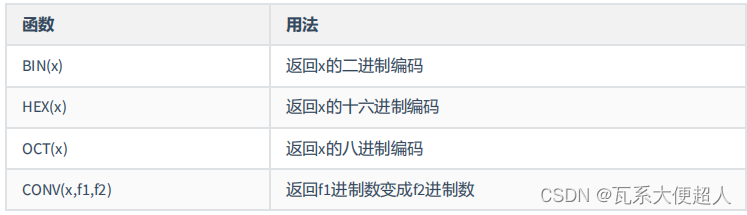
SELECT BIN(10),HEX(10),OCT(10),CONV(10,2,8)
FROM DUAL;
#字符串函数
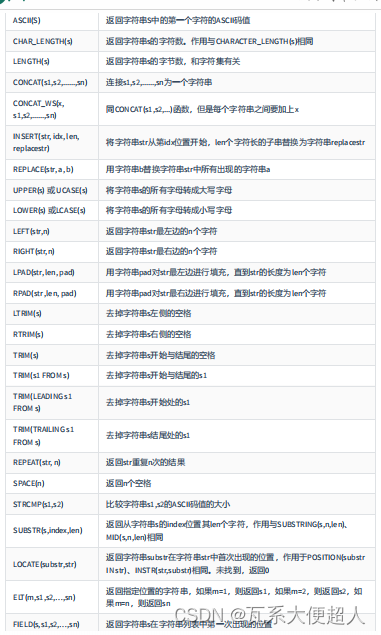
SELECT FIELD('mm','hello','msm','amma'),FIND_IN_SET('mm','hello,mm,amma')
FROM DUAL;
#字符串拼接
SELECT CONCAT(emp.last_name,"work for ",mgr.last_name),"details"
FROM employees emp JOIN employees mgr
ON emp.manager_id = mgr.employee_id;
SELECT CONCAT_WS("-","hello","world","nihao!")
FROM DUAL;
#字符串的索引从1开始
SELECT INSERT("hello",2,3,"aaaaa") #结果为haaaaao
FROM DUAL;
SELECT REPLACE("hello",'ll','mm')#结果为hemmo
FROM DUAL;
SELECT LEFT("hello",2),RIGHT("hello",3) #he #llo
FROM DUAL;
#LPAD:实现右对齐效果
#RPAD:实现左对齐效果
SELECT employee_id,last_name,LPAD(salary,10," ")
FROM employees;
#TRIM用于去除收尾空格或特定字符
SELECT CONCAT("----",TRIM(' h el lo '),"****"),
TRIM('o' FROM 'ooheollo')
FROM DUAL;
#SPACE返回多少个空格
#STRCMP 比较字符
SELECT REPEAT("hello",4),LENGTH(SPACE(5)),STRCMP('abc','abe')
FROM DUAL;
#SUBSTR(s,index,len),返回字符串s中第index个位置的len个字符
#LOCATE(substr,str),返回子串substr在str中的位置
SELECT SUBSTR('hello',2,2),LOCATE('l','hello')
FROM DUAL;
#ELT(m,s1,s2,s3...sn):返回第sm个位置的字符串
SELECT ELT(2,'a','b','c','d')#结果为b
FROM DUAL;
#FIELD(s,s1,s2,…,sn):返回字符串s在字符串列表中第一次出现的位置
SELECT FIELD('mm','gg','jj','dd','mm','mm')
FROM DUAL;#结果为4
#FIND_IN_SET(s1,s2)返回字符串s1在字符串s2中出现的位置。其中,字符串s2是一个以逗号分隔的字符串
SELECT FIND_IN_SET('mm','gg,jj,dd,mm,mm')
FROM DUAL;
#NULLIF(value1,value2)比较两个字符串,如果value1与value2相等,则返回NULL,否则返回value1
SELECT employee_id,NULLIF(LENGTH(last_name),LENGTH(first_name))
FROM employees;
#3.日期和时间函数
#3.1获取日期和时间
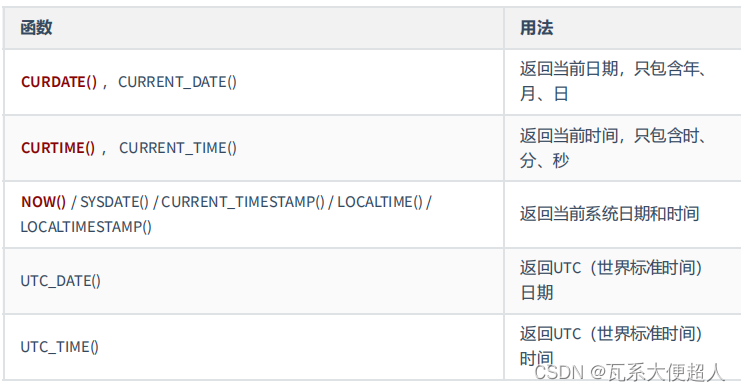
SELECT CURDATE(),CURRENT_DATE(),CURTIME(),NOW(),SYSDATE(),UTC_DATE(),UTC_TIME()
FROM DUAL;
#3.2日期和时间戳的转换
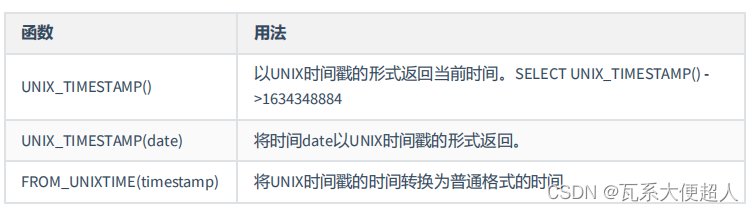
SELECT UNIX_TIMESTAMP(),UNIX_TIMESTAMP('2023-06-28 18:49:00'),
FROM_UNIXTIME(1687949346),FROM_UNIXTIME(1687949340)
FROM DUAL;
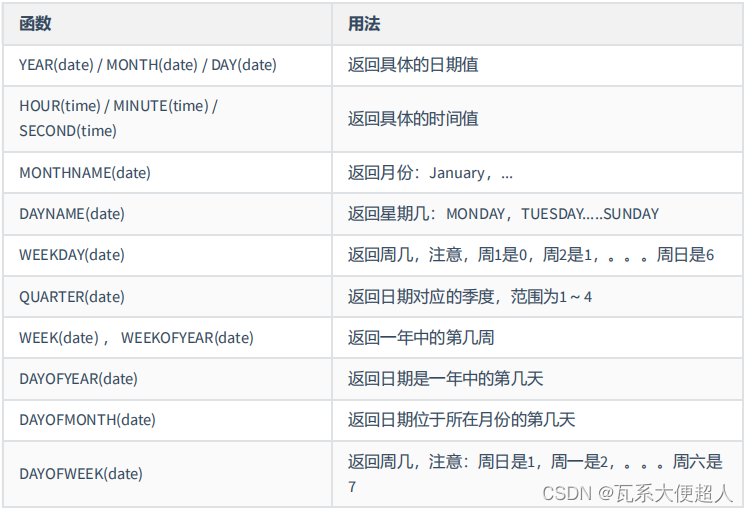
#3.3 获取月份、星期、星期数、天数等函数
SELECT YEAR(CURDATE()),MONTH(CURDATE()),DAY(CURDATE()),
HOUR(CURTIME()),MINUTE(NOW()),SECOND(SYSDATE())
FROM DUAL;
SELECT MONTHNAME('2021-10-26'),DAYNAME('2021-10-26'),WEEKDAY('2021-10-26'),
QUARTER(CURDATE()),WEEK(CURDATE()),DAYOFYEAR(NOW()),
DAYOFMONTH(NOW()),DAYOFWEEK(NOW())
FROM DUAL;
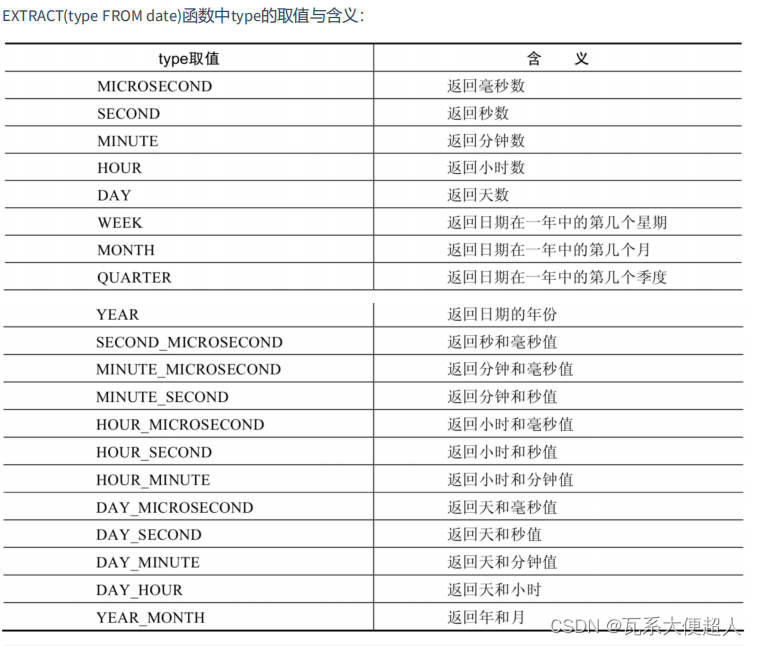
#3.4日期的操作函数
#EXTRACT(type FROM date) 返回指定日期中特定的部分,type指定返回的值
SELECT EXTRACT(SECOND FROM NOW()),EXTRACT(DAY FROM NOW()),EXTRACT(HOUR_MINUTE FROM NOW())
,EXTRACT(QUARTER FROM NOW()) FROM DUAL;
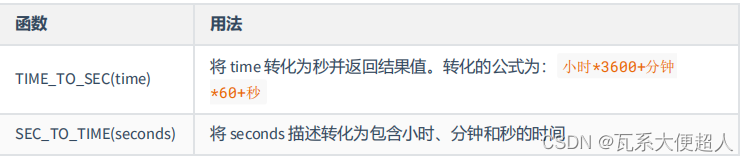
#3.5时间和秒钟转换的函数
SELECT TIME_TO_SEC(CURTIME()),SEC_TO_TIME(68622)
FROM DUAL;
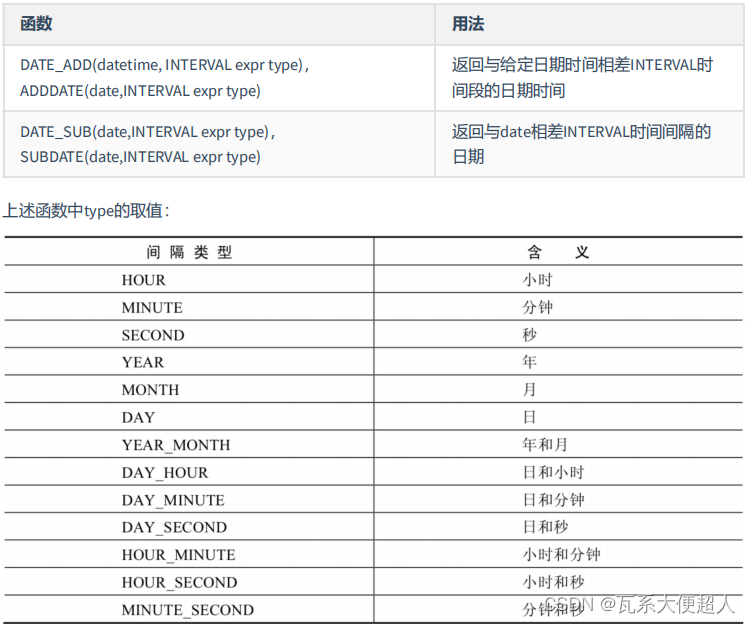
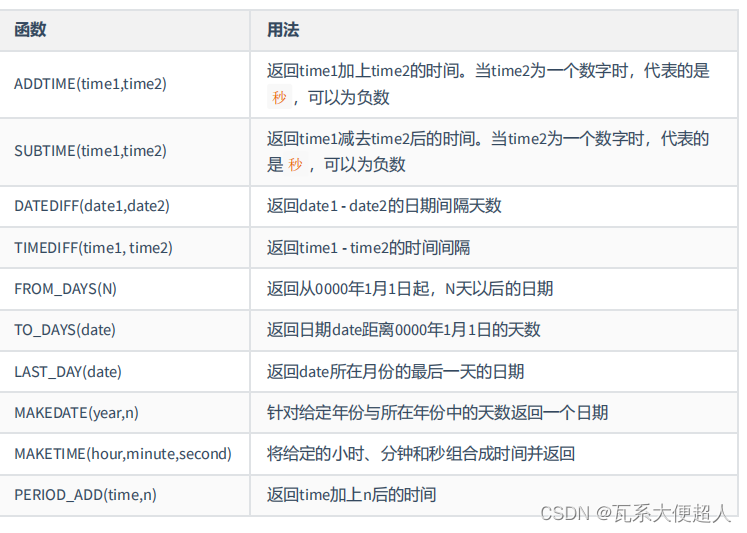
#3.6计算日期和时间的函数
SELECT NOW(),DATE_ADD(NOW(),INTERVAL 1 YEAR),
DATE_ADD(NOW(),INTERVAL -1 YEAR),
DATE_SUB(NOW(),INTERVAL 1 YEAR)
FROM DUAL;
SELECT NOW(),ADDDATE('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col3,
DATE_ADD('2021-10-21 23:32:12',INTERVAL '1_1' MINUTE_SECOND) AS col4,
DATE_ADD(NOW(), INTERVAL -1 YEAR) AS col5, #可以是负数
DATE_ADD(NOW(), INTERVAL '1_1' YEAR_MONTH) AS col6 #需要单引号
FROM DUAL;
SELECT CURTIME(),
ADDTIME(NOW(),20),SUBTIME(NOW(),30),SUBTIME(NOW(),'1:1:3'),DATEDIFF(NOW(),'2021-10-
01'),
TIMEDIFF(NOW(),'2021-10-25 22:10:10'),FROM_DAYS(366),TO_DAYS('0000-12-25'),
LAST_DAY(NOW()),MAKEDATE(YEAR(NOW()),12),MAKETIME(10,21,23),PERIOD_ADD(20200101010101,
10)
FROM DUAL;
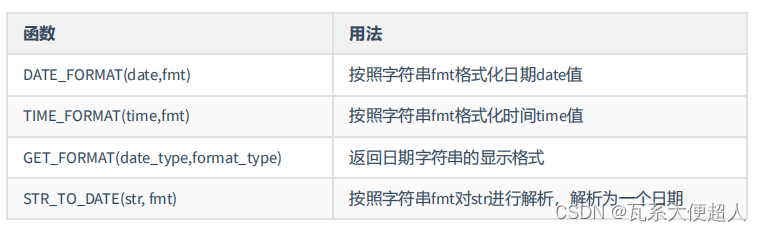
#3.7日期的格式化与解析
#格式化:日期--->字符串
#解析:字符串--->日期
#此时我们谈的是日期的显示格式化和解析
#之前,我们接触过隐式的格式化或解析
SELECT *
FROM employees
WHERE hire_date = '1993-01-13';
#格式化:
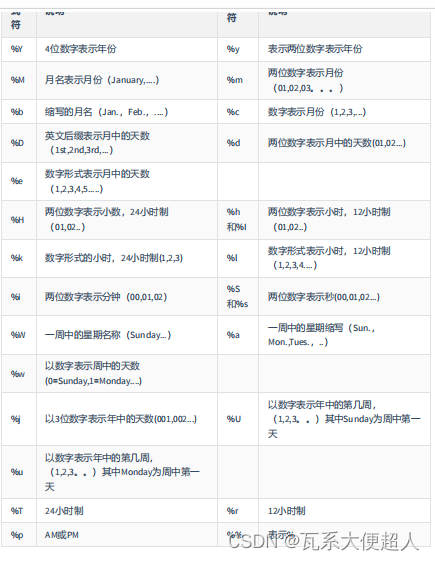
SELECT DATE_FORMAT(CURDATE(),'%Y-%M-%D'),
DATE_FORMAT(NOW(),'%Y-%m-%d'),TIME_FORMAT(CURTIME(),'%H:%i:S')
,DATE_FORMAT (NOW(),'%Y-%M-%D %h:%i:%S %W %w %T %r')
FROM DUAL;
#解析:格式化的逆过程
SELECT STR_TO_DATE('2023-June-28th 09:22:15 Wednesday 3 ','%Y-%M-%D %h:%i:%S %W %w')
FROM DUAL;
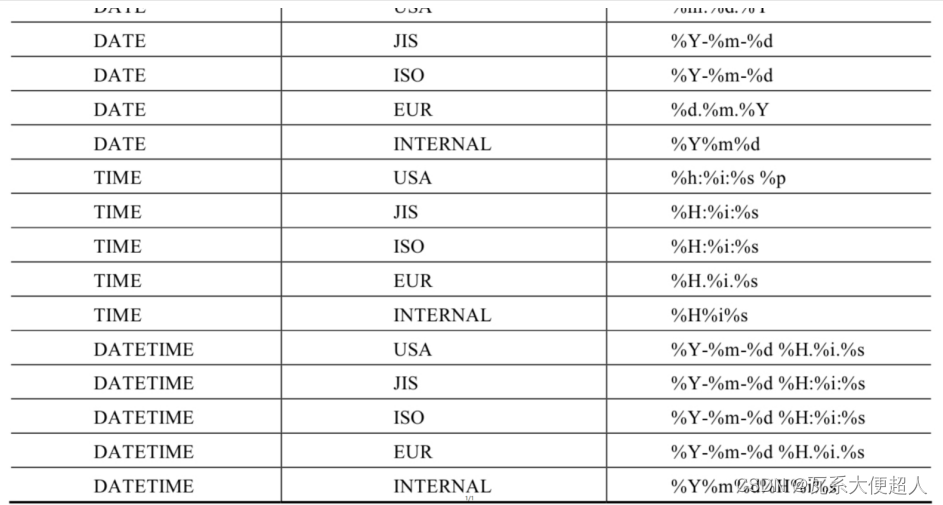
SELECT GET_FORMAT(DATE,'USA')
FROM DUAL;
SELECT DATE_FORMAT(CURDATE(),GET_FORMAT(DATE,'USA'))
FROM DUAL;
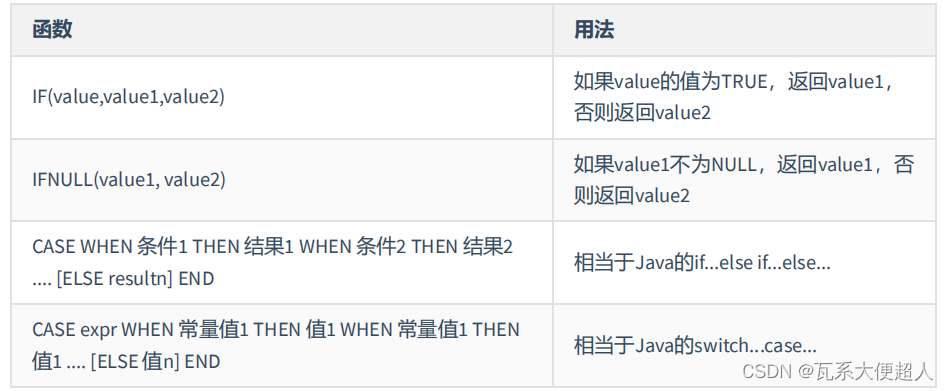
#4.流程控制函数
#IF(VALUE,VALUE1,VALUE2)
SELECT last_name,salary,IF(salary >= 6000,'高工资','低工资') 'details'
FROM employees;
SELECT last_name,commission_pct,IF(commission_pct IS NOT NULL,commission_pct,0) 'details',
salary * 12 * (1 + IF(commission_pct IS NOT NULL,commission_pct,0)) 'annual_sal'
FROM employees;
#4.2 IFNULL(VALUE1,VALUE2):看做是IF(VALUE,VALUE1,VALUE2)的特殊情况
SELECT last_name,commission_pct,IFNULL(commission_pct,0) 'details'
FROM employees;
#4.3 CASE WHEN .. THEN ... WHEN ...THEN ... ELSE... END
#类似于java的if ...else...
SELECT last_name,salary,CASE WHEN salary >= 15000 THEN '白骨精'
WHEN salary >= 12000 THEN '潜力股'
WHEN salary >= 8000 THEN '小屌丝'
ELSE '草根' END 'details'
FROM employees;
SELECT last_name,salary,CASE WHEN salary >= 15000 THEN '白骨精'
WHEN salary >= 12000 THEN '潜力股'
WHEN salary >= 8000 THEN '小屌丝'
END 'details'
FROM employees;
#4.4 CASE...WHEN...THEN...WHEN...THEN...ELSE...END
#类似于java的switch case
/*
练习1:查询部门号为 10,20, 30 的员工信息,
若部门号为 10, 则打印其工资的 1.1 倍,
20 号部门, 则打印其工资的 1.2 倍,
30 号部门打印其工资的 1.3 倍数。
其他部门,打印其工资的1.4倍
*/
SELECT employee_id,last_name,department_id,salary,CASE department_id WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
ELSE salary * 1.4 END 'details'
FROM employees;
/*
练习2:查询部门号为 10,20, 30 的员工信息,
若部门号为 10, 则打印其工资的 1.1 倍,
20 号部门, 则打印其工资的 1.2 倍,
30 号部门打印其工资的 1.3 倍数。
*/
SELECT employee_id,last_name,department_id,salary,CASE department_id WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
ELSE salary * 1.4 END 'details'
FROM employees
WHERE department_id IN (10,20,30);
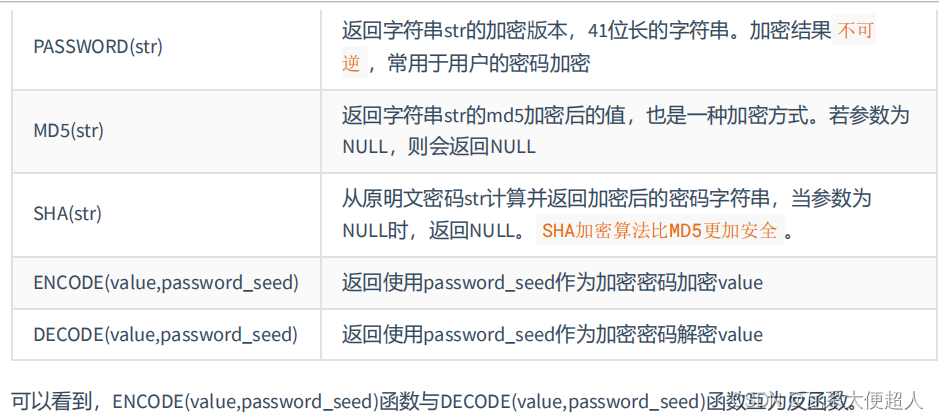
#5.加密与解密的函数
SELECT MD5('mysql'),SHA('mysql'),MD5(MD5('mysql'))
FROM DUAL;
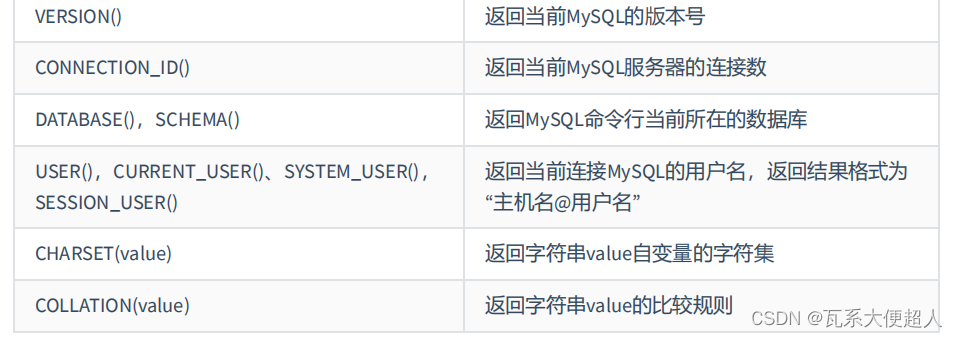
#6.MySQL信息函数
SELECT VERSION(),CONNECTION_ID(),DATABASE(),SCHEMA(),
USER(),CURRENT_USER(),CHARSET('尚硅谷'),COLLATION('尚硅谷')
FROM DUAL;
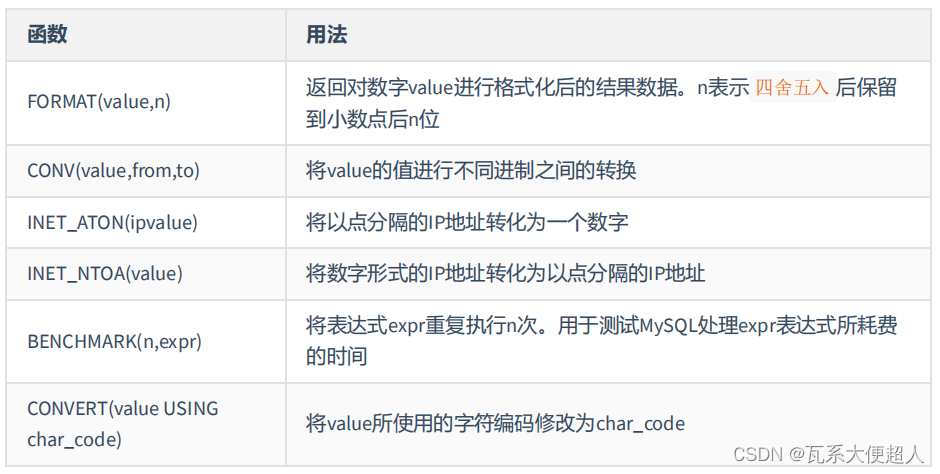
#7.其他函数
#如果n的值小于或者等于0,则只保留整数部分
SELECT FORMAT(123.125,2),FORMAT(123.125,0),FORMAT(123.125,-2)
FROM DUAL;
SELECT CONV(16, 10, 2), CONV(8888,10,16), CONV(NULL, 10, 2)
FROM DUAL;
## 以“192.168.1.100”为例,计算方式为192乘以256的3次方,加上168乘以256的2次方,加上1乘以256,再加上100
SELECT INET_ATON('192.168.1.100'),INET_NTOA(3232235876)
FROM DUAL
#BENCHMARK()用于测试表达式的执行效率
SELECT BENCHMARK(1000000,MD5('mysql'))
FROM DUAL;
#CONVERT():可以实现字符集的转换
SELECT CHARSET('atguigu'),CHARSET(CONVERT('atguigu' USING 'gbk'))
FROM DUAL;
练习
#第08章 练习
#1.where子句可否使用组函数进行过滤?
#NO!
#2.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees;
#3.查询各job_id的员工工资的最大值,最小值,平均值,总和
SELECT job_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees
GROUP BY job_id;
#4.选择具有各个job_id的员工人数
SELECT job_id, COUNT(*)
FROM employees
GROUP BY job_id;
# 5.查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary)-MIN(salary) 'DIFFERENCE'
FROM employees;
# 6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
SELECT manager_id,MIN(salary)
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary) >= 6000;
#第七题多看看
# 7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
SELECT ,COUNT(*),AVG(salary)
FROM departments d LEFT JOIN employees e
ON d.department_id = e.department_id
GROUP BY department_name,location_id
ORDER BY AVG(salary) DESC;
SELECT * FROM employees;
# 8.查询每个工种、每个部门的部门名、工种名和最低工资
SELECT job_id,department_name,MIN(salary)
FROM employees e JOIN departments d
ON e.department_id = d.department_id
GROUP BY job_id,e.department_id;
聚合函数
内容
#第八章 聚合函数
#1.常见的几个聚合函数
#1.1 AVG / SUM:只适用于数值类型的字段(或变量)
SELECT AVG(salary) , SUM(salary),AVG(salary)*107
FROM employees;
#如下的操作没有意义
SELECT SUM(last_name),AVG(last_name),SUM(hire_date)
FROM employees;
#1.2 MAX / MIN:适用于数值类型、字符串类型、日期时间类型的字段(或变量)
SELECT MAX(salary),MIN(salary)
FROM employees;
SELECT MAX(last_name),MIN(last_name),MAX(hire_date),MIN(hire_date)
FROM employees;
#1.3 COUNT:
#① 作用:计算指定字段在查询结果中出现的个数(不包含NULL值的)
SELECT COUNT(employee_id),COUNT(salary),COUNT(2*salary),COUNT(1),COUNT(2),COUNT(*)
FROM employees;
SELECT * FROM employees;
#如果计算表中有多少条记录,如何实现?
#方式1:COUNT(*)
#方式2:COUNT(1)
#方式3: COUNT(具体字段):不一定对!
#②:注意:计算指定字段出现的个数时,是不计算NULL值的。
SELECT COUNT(commission_pct)
FROM employees;
#相当于
SELECT commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
#③ AVG = SUM / COUNT
SELECT AVG(salary),SUM(salary)/COUNT(salary),
AVG(commission_pct),SUM(commission_pct)/COUNT(commission_pct),
SUM(commission_pct)/107
FROM employees;
#需求:查询公司中平均奖金率
SELECT AVG(commission_pct)
FROM employees;
#正确的:
SELECT SUM(commission_pct) / COUNT(IFNULL(commission_pct,0)),AVG(IFNULL(commission_pct,0))
FROM employees;
#如果需要统计表中的记录数,使用COUNT(*),COUNT(1),COUNT(具体字段)哪个效率更高呢?
#如果使用的是MyISAM 存储引擎,则三者的效率相同,都是O(1)
#如果使用的是InnoDB 存储引擎,则三者效率:COUNT(*) = COUNT(1) > COUNT(字段)
#其他:求方差、标准差、中位数
#2.GROUP BY 的使用
#需求:查询各个部门的平均工资,最高工资
SELECT department_id, AVG(salary),SUM(salary)
FROM employees
GROUP BY department_id
#需求:查询各个job_id的平均工资
SELECT job_id,AVG(salary)
FROM employees
GROUP BY job_id;
#需求:查询各个department_id,job_id的平均工资
#方式1:
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
#方式2:
SELECT job_id,department_id,AVG(salary)
FROM employees
GROUP BY department_id,job_id;
#错误的!
SELECT deparment_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id;
#结论1:SELECT中出现的非组函数的字段必须声明在GROUP BY中。
# 反之,GROUP BY中声明的字段可以不出现在SELECT中。
#结论2:GROUP BY 声明在FROM后面、也得在WHERE后面、ORDER BY 前面、 LIMIT 前面
#结论3:MySQL中GROUP BY使用WITH ROLLUP
#WITH ROLLUP除了分组计算之后还会计算总的平均值
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id WITH ROLLUP;
#需求:查询各个部门的平均工资,按照平均工资升序排列
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id
ORDER BY avg_sal ASC;
#5.7版本会报错,8.0版本不会报错
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id WITH ROLLUP
ORDER BY avg_sal ASC;
#3.HAVING的使用(作用:用来过滤数据的)
#练习:查询各个部门中最高工资比10000高的部门信息
#错误的写法:
SELECT department_id,MAX(salary)
FROM employees
WHERE MAX(salary)>10000
GROUP BY department_id;
#要求1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则,报错
#要求2:HAVING必须声明在GROUP BY的后面。
#正确的写法:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
#要求3:开发中,我们使用HAVING的前提是SQL中使用了GROUP BY。
#练习:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
#方式1:推荐,执行效率高于方式2
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
#方式2:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
#结论:当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
# 当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE或HAVING中都可以。但是,建议声明在WHERE中。
/*
WHERE与HAVING的对比:
1.从适用范围上来讲,HAVING的适用范围更广。
2.如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING
*/
#4.SQL底层执行原理
#4.1 SELECT 语句的完整结构
/*
#SQL92语法:
SELECT ...,....,...(存在聚合函数)
FROM...,...,...
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY...,...
HAVING 包含聚合函数的过滤条件
ORDER BY...,...(ASC / DESC)
LIMIT ...,...
#SQL99语法:
SELECT...,....,...(存在聚合函数)
FROM...(LEFT / RIGHT )JOIN... ON 多表的连接条件
(LEFT / RIGHT)JOIN... ON ...
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,...
HAVING 包含聚合函数的过滤条件
ORDER BY ...,...(ASC / DESC)
LIMIT ...,...
*/
#4.2 SQL语句的执行过程:
#FROM...,...-> ON -> (LEFT/RIGHT JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT ->
# ORDER BY -> LIMIT
练习
#第08章 练习
#1.where子句可否使用组函数进行过滤?
#NO!
#2.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees;
#3.查询各job_id的员工工资的最大值,最小值,平均值,总和
SELECT job_id,MAX(salary),MIN(salary),AVG(salary),SUM(salary)
FROM employees
GROUP BY job_id;
#4.选择具有各个job_id的员工人数
SELECT job_id, COUNT(*)
FROM employees
GROUP BY job_id;
# 5.查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary)-MIN(salary) 'DIFFERENCE'
FROM employees;
# 6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
SELECT manager_id,MIN(salary)
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary) >= 6000;
#第七题多看看
# 7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
SELECT d.department_name,d.location_id,COUNT(employee_id),AVG(salary)
FROM departments d LEFT JOIN employees e
ON d.department_id = e.department_id
GROUP BY department_name,location_id
ORDER BY AVG(salary) DESC;
SELECT * FROM employees;
# 8.查询每个工种、每个部门的部门名、工种名和最低工资
SELECT d.department_name,e.job_id,MIN(salary)
FROM departments d LEFT JOIN employees e
ON d.department_id = e.department_id
GROUP BY d.department_id,e.job_id;