
code link: https://github.com/CrisHY1995/headnerf
相关连接:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/124874717
- 来自中科大张举勇教授课题组提出了 HeadNeRF,一种基于 NeRF 的高效全息人脸头部参数化模型,该工作发表于 CVPR 2022,相关代码已开源。
- HeadNeRF 可以实时地渲染高清图像级别的人脸头部,且支持直接编辑调整渲染结果的多种语义属性,如身份、表情以及颜色外观等。得益于 NeRF 结构的引入,HeadNeRF 也支持直接编辑调整渲染对象的渲染视角,同时不同视角的渲染结果具有优秀的渲染一致性。
https://www.zhihu.com/question/517340666/answer/2556591098?utm_id=0
- 由于不同身份的人物对象,其脸部形状以及五官分布往往是相似的,因此人脸本身是适合嵌入到低维参数化空间,从而进行参数化建模表示的。然而,现有的基于传统几何表示的人脸/人头语义参数化模型常面临表达能力有限以及几何训练数据收集困难的问题。
- 中国科学技术大学GCL实验室提出一种全新的参数化人脸头部表示——HeadNeRF,相关工作已被CVPR 2022接收,相关代码也已开源。
- HeadNeRF直接将NeRF 本身看作一种三维表示。针对渲染任务,NeRF 一定程度上可以等价甚至优于传统的纹理材质网格。且由于 NeRF 是完全基于神经网络的,因此 NeRF 的渲染过程是天然可微的,而其他传统的几何表示,如三维网格,点云,体素等则往往需要各种近似策略来缓解相关表示的渲染不可微问题,与之对应的参数化表示工作往往则需要收集并处理大量的三维扫描数据。相对的,HeadNeRF 的构建过程则只需要使用二维人脸图片即可。效果上,HeadNeRF 可以实时地渲染图像级别的人脸头部,且支持直接编辑调整渲染结果的多种语义属性,如身份、表情以及颜色外观等。得益于 NeRF 结构的引入,HeadNeRF 也支持直接编辑调整渲染对象的渲染视角,同时不同视角的渲染结果具有优秀的渲染一致性。
文章目录
- 相关连接:
- https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/124874717
- https://www.zhihu.com/question/517340666/answer/2556591098?utm_id=0
- 内容概述
- abstract
- introduction
- contributions
- Framework
- Methods
- HeadNeRF的模型表示R:
- 网络结构:
- Latent Codes and Canonical Coordinate
- Datasets and Preprocessing
- loss function
- Photometric Loss (光度损失)
- Perceptual Loss (感知损失)
- Disentangled Loss (分离损失)
- 总体损失
- Evaluations
- Disentangled Control
- pose控制
- 属性编辑
- 感知损失的消融研究
- Ablation Study on 2D Neural Rendering
- FFHQ数据集的重要性
- Comparisons
- 4.4. Application: Expression Transfer
- 5. Limitation and Future Work
- Conclusion
内容概述

abstract
在本文中,我们提出了一种新的基于nerf的参数化头部模型HeadNeRF,它将神经辐射场集成到头部的参数表示中。
它可以在GPU上实时渲染高保真的头部图像,支持直接控制生成的图像的渲染姿态和各种语义属性。
与现有的相关参数化模型不同,HeadNeRF采用神经辐射场代替传统的三维纹理网格作为新的三维代理,使得HeadNeRF能够生成高保真图像。
克服的困难:原始NeRF的渲染过程计算量大,阻碍了参数NeRF模型的构建。
针对这一问题,我们采用了将2D神经渲染与NeRF渲染过程相结合的策略,并设计了新的损失项。
取得的效果:
因此HeadNeRF的渲染速度可以明显加快,一帧的渲染时间从5s减少到25ms。
设计良好的损失项也提高了渲染精度,HeadNeRF可以表示和合成人类头部的细微细节,如牙齿之间的缝隙,皱纹和胡子。
introduction
HeadNeRF继承了NeRF的优秀特性,可以生成高保真度的头部图像,并保持显著的多视图一致性。此外,NeRF本身支持自由改变渲染所用的摄像机视角,因此HeadNeRF自然支持渲染图像的姿势编辑。
baseline: (对比的对象)
而传统的3D表示,如网格、点云、体素等,则需要设计各种近似方法[19,23,27,28,32]来缓解其渲染过程中的不可微问题。
与对比对象的优势:
因此,与以往需要捕获和处理大量高质量3D扫描数据的方法相比,HeadNeRF的构造只需要二维图像作为输入。
我们收集并处理了三个大规模的人头图像数据集,并设计了新的损失项来解开这个参数表示。HeadNeRF通过良好设计的网络结构和损失函数,可以从语义上分离渲染图像的身份、表达和外观。
进一步将NeRF的体绘制与2D神经绘制相结合,实现实时绘制。 效果是:它可以在不牺牲渲染质量的情况下超过40fps (每秒50帧)。
HeadNeRF的应用:包括从单一面部图像进行新颖的视图合成、语义编辑面部属性,甚至将一个人的表情转移到另一个人的面部再现。
contributions
- 我们提出了第一个基于nerf的参数化人头模型,该模型可以直接有效地控制渲染姿态、身份、表情和外观。
- 我们提出了一种有效的训练策略,从一般的二维图像数据集中训练模型,训练后的模型可以生成高保真的渲染图像
- 我们用HeadNeRF设计并实现了几个新的应用程序,结果验证了它的有效性。我们相信HeadNeRF可以开发出更多有趣的应用
Framework
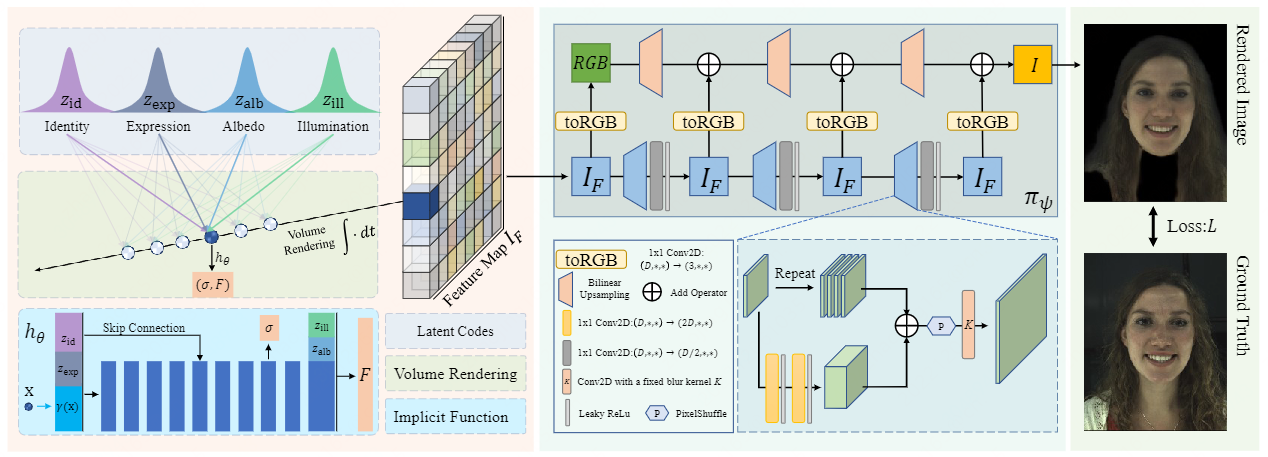
- 在给定语义潜码和摄像机参数的情况下,利用基于mlp的隐式函数hθ预测一条射线采样的三维点x的密度σ(x)和特征向量F (x)
- 执行体绘制生成低分辨率特征图 I F I_F IF
- 特征图 I F I_F IF 进一步通过我们精心设计的2D神经渲染模块 π ψ π_ψ πψ
Methods
HeadNeRF的模型表示R:
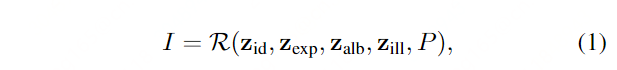
其中:其中P为用于渲染的摄像机参数,包括外部矩阵和内部矩阵。Z *表示四个独立因素的潜在代码:身份zid,表情zexp,面部反照率 zalb和场景的照明zill。
网络结构:
基于mlp的NeRF隐函数hθ表示为:
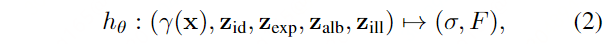
与[16,38,63]一样,我们没有直接预测x的RGB,而是预测了三维采样点x的高维特征向量F (x)∈r256
hθ以γ(x)、zid、zexp的级联为输入,输出x的密度σ和一个中间特征,后者与zalb、zilli进一步预测F (x)。
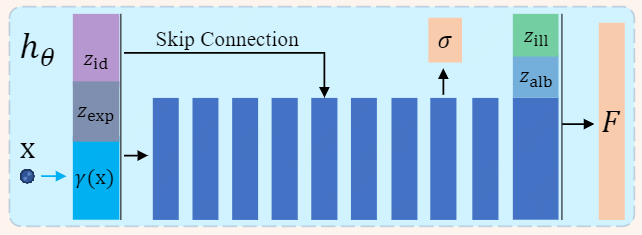
因此,密度场的预测主要受身份码和表达式码的影响。
特征图
I
F
I_F
IF 的计算,就是一个体绘制的过程。
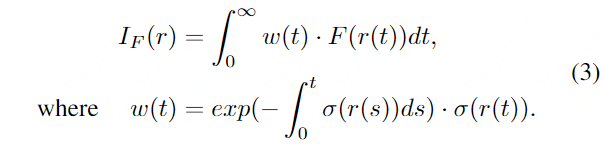
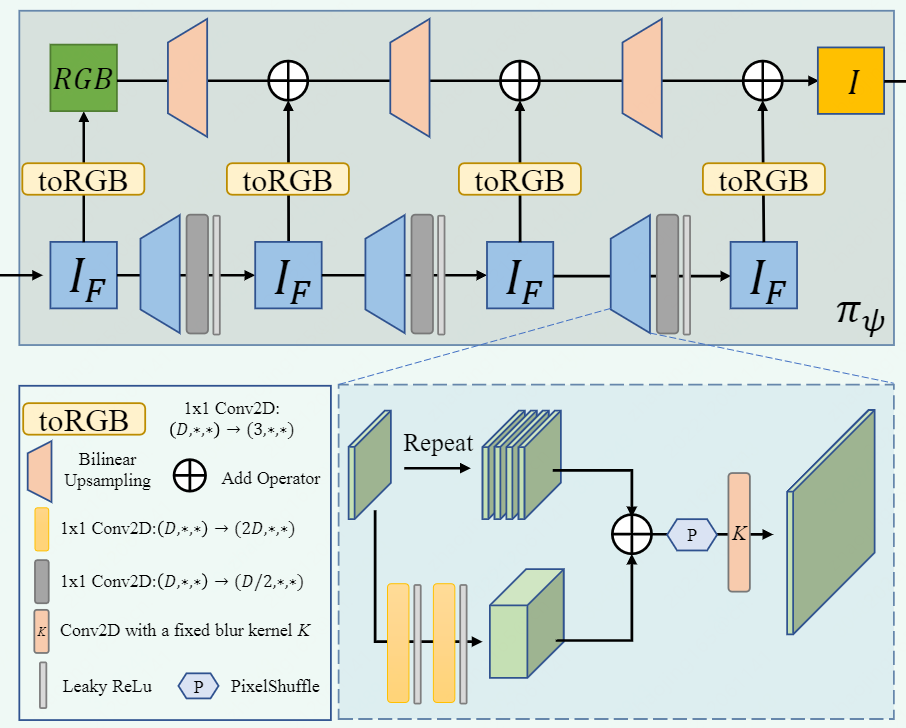
2D 神经渲染模块
- 主要由1x1 Conv2D和泄漏的ReLU[33]激活层组成,以缓解可能出现的多视图不一致工件[16]。
- 与StyleNeRF[16]中使用的策略类似,通过一系列上采样层,IF的分辨率逐渐提高。上采样过程可以表述为:

- 其中,Rd→R4d是可学习的2层βζ,ζ表示可学习的权重,K是固定模糊核[62]。
- 像GIRAFFE[38]一样,我们将每个特征张量映射到一个RGB图像,并将所有RGB的和作为最终的预测图像。不同的是,我们使用1x1卷积而不是3x3卷积来避免可能的多视图不一致[16]。
Latent Codes and Canonical Coordinate
- 为了有效地训练HeadNeRF,我们利用3DMM来初始化我们训练数据集的每一幅图像的潜代码 。 我们将HeadNeRF的潜在代码的维度设置为与3DMM[51]中相应代码的维度相同,并基于3DMM模型通过求解逆渲染优化[10,54]来初始化它们。
- 为了稳定HeadNeRF的训练,我们需要在训练之前将每个图像的底层几何图形与类似的中心对齐。对于每幅图像,我们求解上述3DMM参数优化得到其相应的全局刚体变换T∈R4×4,该变换将3DMM几何从3DMM正则坐标转换到相机坐标。
Datasets and Preprocessing
- FaceSEIP Dataset.
- FaceScape Dataset.
- FFHQ Dataset.
loss function
可学习变量包括每张图像的潜码和体绘制和神经绘制的共享网络参数。
Photometric Loss (光度损失)
对于每一幅图像,要求头部区域的渲染结果与对应的实像一致,此损失项表示为:
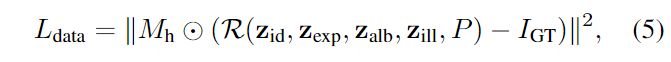
- Mh is the head mask
- Hadamard*(哈达玛积)乘积。 (对应位置想成)
Perceptual Loss (感知损失)
与普通NeRF相比,HeadNeRF可以通过一个推断直接预测渲染图像中所有像素的颜色。因此,我们采用等式(6)中的感知损失[20]来进一步改善渲染结果的图像细节。
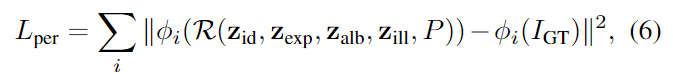
- 其中φi(∗) 表示VGG16[46]网络中第i层的激活。 ???
- Lper可以显著改善渲染结果的细节
Disentangled Loss (分离损失)
-
为了实现对渲染结果的语义解纠缠控制,我们让同一被试的所有图像共享相同的身份潜伏码,让同一被试的相同表情在不同光照条件下、不同拍摄相机下的图像共享相同的表情潜伏码。
-
为了达到解纠缠表达的目的,表达相似的不同主体应当有相似的表达码。由于3DMM的引入,第3.3节的初始化方法生成的初始表达式代码满足了这一要求。因此,我们要求可学习的表达式代码不能远离初始表达式代码。
-
由于3DMM主要对面部区域进行建模,没有头发、牙齿等,所以我们对这些非表情属性放宽了限制。
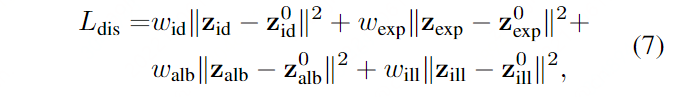
其中z *是可学习潜码,z0 *是来自3DMM模型的初始潜码
总体损失
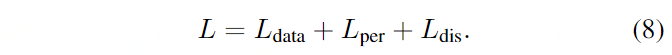
Evaluations
Disentangled Control
pose控制
对于给定的潜码组合(zid, zexp, zalb, zill),我们可以直接调整相机参数来连续改变渲染视图或编辑相机的位置和FoV(视场)。这些渲染结果具有良好的多视图一致性,说明我们设计良好的2D神经渲染模块有效地保留了原始NeRF隐式编码的几何结构


属性编辑
如图所示,在编辑特定的属性时,HeadNeRF可以保持剩余的语义属性,验证了HeadNeRF有效地分离了不同的面部属性。

感知损失的消融研究
知觉丧失的消融研究。感知损失有效地增强了生成结果的精细级细节(红色区域有褶皱,绿色区域有胡须)。

Ablation Study on 2D Neural Rendering
如图8所示,HeadNeRF-vanilla的结果趋于模糊,这可能是由于其训练效率不高造成的。相比之下,由于神经渲染模块所赋予的有效性和效率,HeadNeRF可以在获得更好的渲染结果的同时使用更少的训练时间。HeadNeRF-vanilla渲染一帧图像需要约5秒的时间,而HeadNeRF可以实时渲染结果。

由于2D神经渲染模块所赋予的有效性和效率,HeadNeRF可以使用更少的训练时间,同时获得更好的渲染结果
FFHQ数据集的重要性
为了验证FFHQ数据集的重要性,我们训练了两个参数模型进行比较,其中一个只训练了FaceSEIP数据集,另一个训练了FaceSEIP和FFHQ数据集。
优化后潜码的渲染结果如图9所示。可以发现,FFHQ数据集的引入显著地促进了HeadNeRF的泛化能力。
 利用FFHQ数据集进行消融研究。FFHQ数据集的引入显著提高了HeadNeRF的泛化能力。基于HeadNeRF,我们可以只以一张图像作为输入,修改优化结果的指定属性,如调整渲染姿势,改变渲染结果的身份、表情和外观。
利用FFHQ数据集进行消融研究。FFHQ数据集的引入显著提高了HeadNeRF的泛化能力。基于HeadNeRF,我们可以只以一张图像作为输入,修改优化结果的指定属性,如调整渲染姿势,改变渲染结果的身份、表情和外观。
- 我们在模型训练中使用的数据集是互补的,有效地提高了HeadNeRF的表示能力。
Comparisons

HeadNeRF可以有效地生成高保真图像,同时保持优秀的多视图一致性
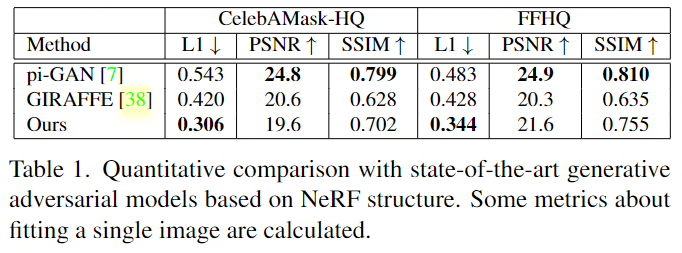
pi-GAN的拟合结果在视觉上确实是最优的。然而,如果对拟合结果的渲染姿态进行编辑和改变,往往会使渲染结果变得模糊和损坏。

4.4. Application: Expression Transfer
由于HeadNeRF具有较强的表示能力,可以对渲染结果的各种属性进行分离,可以用于小说视图合成、样式混合等许多应用。在这一部分中,我们利用HeadNeRF来执行表达式传输,即将参考视频中的面部表情转移到目标图像中的人。为此,我们只需要从参考视频和目标图像中提取所有图像的潜码,用参考视频中的表情潜码替换目标图像的表情潜码。最后,利用经过训练的HeadNeRF生成所需的人脸图像序列,其中目标图像中的字符被驱动从参考视频中做出表情。定性结果如图12所示。

5. Limitation and Future Work
HeadNeRF仍然存在一些局限性。虽然加入了FFHQ数据集中的图像来增强HeadNeRF的表示能力,但目前的训练数据集仍然不足以覆盖各种情况。对于与我们训练数据相差很大的图像,HeadNeRF只能返回相似的拟合任务结果。如图13所示,由于我们的训练数据很少涉及到带头饰的图像,所以在HeadNeRF的拟合结果中很难渲染头饰的内容。未来,我们考虑使用大量的野外人脸图像数据,以自监督的方式进一步增强HeadNeRF的表示能力。
在我们的多视图数据集(FaceSEIP)中,目前的训练数据集只包含四种照明类型,不足以覆盖照明类型。
Conclusion
在本文中,我们提出了一种新的基于nerf的参数头模型HeadNeRF,该模型将神经辐射场与参数头表示相结合。得益于我们精心设计的网络模块和损耗项,HeadNeRF可以在现代gpu上实时渲染高保真的头部图像,并支持直接控制渲染图像的姿势,独立编辑生成的图像的身份、表情和外观。大量的实验结果表明,HeadNeRF优于最先进的相关模型。我们相信HeadNeRF已经向现实的数字人类迈出了重要的一步。
![[附源码]计算机毕业设计JAVA中达小区物业管理系统](https://img-blog.csdnimg.cn/7fbe4f764ddb471d8fb9128812b2faa0.png)







![[附源码]Python计算机毕业设计SSM基于自组网的空地一体化信息系统(程序+LW)](https://img-blog.csdnimg.cn/6100a11d381b477d8b3a6a9cefbe6cef.png)

![[附源码]Python计算机毕业设计SSM计算机软考系统的设计与实现(程序+LW)](https://img-blog.csdnimg.cn/aa760a4acee94c688f778cc040ce09b8.png)