在信贷风控中,数据建模好像是“家常便饭”那么普通且重要,而我们最终享用“饭菜”的美味程度,在数据“食材”较完备的情况下,完全取决于我们建模的方法。根据实际业务场景,采用合理且有效的建模思路,可以较大限度保证模型的应用效果。
通常情况下,针对不同的场景需求,我们习惯采用单一算法来建立模型,例如逻辑回归、决策树、K近邻、朴素贝叶斯、支持向量机等,但我们有时会遇到模型性能难以满足预期的结果,无论选择何种模型算法,还是调整模型拟合参数,都不足以进一步提升模型的综合效果。在这种情景下,我们可以尝试下模型组合思路,即采用多个模型算法来建立模型,并将其通过某种方式进行合并,便可以得到一个综合模型,此类模型可以有效提升模型的准确度与区分度等性能,从而在实际场景应用中发挥更好的效果。
模型组合主要包含3种模式,分别为串行组合、并行组合、串并混合,其中串并混合只是将串行与并行的思路结合,在模型决策流程中相对较为复杂,因此实际场景应用较少。对于串行组合与并行组合,在建模过程中相对较为常见,且最终得到的综合模型效果表现较好。本文将对其中的串行组合模型及其应用进行介绍,同时围绕具体的信用评估场景来展开详细分析。对于并行组合模型的应用描述,我们后续以另外一篇文章进行呈现。
1、串行组合模型原理
串行组合模型是将多个模型进行串联叠加,将前一个模型的输出作为后一个模型的输入,在单个模型精度不高的情况下,可以实现多个模型的性能聚合,从而有效提升最终模型的精度。一般情况下,串行组合模型的链条,往往将精度较高的模型置于前边,例如随机森林、神经网络、深度学习等,而类似逻辑回归、K近邻、决策树等算法模型放于后边,这样设置思路可以较大程度优化模型训练的拟合空间。此外,这里需要注意的是,并非多个模型的串行组合性能必定优于单个模型,也不是串行的模型数量越多其效果越好,具体需要结合建模数据分布、场景业务需求、模型提升幅度等情况来决定。
串行组合模型的示意流程如图1所示,现有3个算法模型依次串联,模型1的输入仅为原始样本数据;模型2的输入除了原始样本数据外,还包括模型1的输出结果;模型3的输入同理还包括模型2的输出结果。串行组合最终输出的模型结果为最后位置对应的模型,以本示意图为例,模型3输出为综合模型的决策结果。不同业务场景的模型输出是有区别的,例如常见的二分类模型,则模型1/2/3的输出output体现为模型预测的概率值(0~1)。
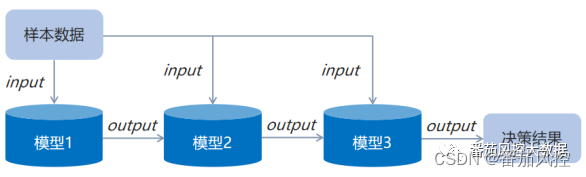
图1 串行组合模型流程
对于串行组合的模型1~模型n,可以采取同种类型的算法,也可以是不同种类的算法。若为同种类型算法,区别主要在于模型的训练参数组合不同,例如各模型均选择GBDT算法,则树的数量、树的深度、学习率等重要参数的取值可以交叉定义;若为不同种类的算法,例如逻辑回归、XGBoost、LightGBM等,此时模型训练参数组合可根据经验自由定义。针对组合模型的特点,由于模型类型与算法参数可选,因此串行模型组合可以分为同类模型串行与异类模型串行。一般情况下,异类模型串行组合在实际业务场景中较为常用,因此接下来我们将围绕异类模型串行组合,来展开实例场景的建模分析。
2、串行模型实现过程
2.1 实例样本描述
结合以上对串行组合模型的理解,接下来我们围绕贷前风控典型的信用评估场景,采用模型串行组合方法来构建信用风险模型,以更具体的描述串行组合模型的应用效果。本文选取的实例样本数据包含10000条样本与9个字段,部分数据样例如图2所示。其中,id为样本主键,credit_apply、call_total、travel_index等7个特征为X变量池,label为目标变量Y,具体特征字典详情如图3所示。
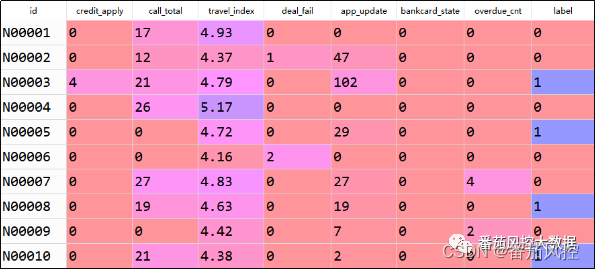
图2 样本数据样例
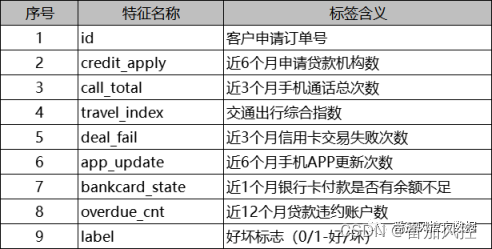
图3 样本特征字典
根据以上样本数据,现构建一个贷前信用风险评估模型,即通过credit_apply、call_total、travel_index等7个特征变量对目标变量label进行拟合训练。其中,特征变量池的简单描述性统计分布eda结果如图4所示,目标变量label的二分类取值分布如图5所示。
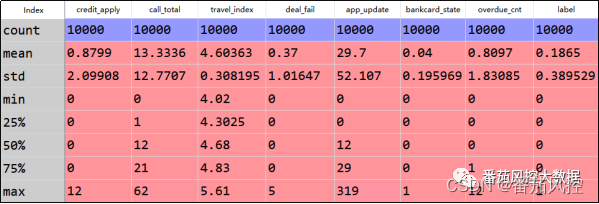
图4 特征变量eda分布

图5 目标label取值分布
2.2 特征性能分析
对于以上样本数据,我们从特征相关性、特征预测性这2个维度来简单分析下各字段的性能。其中,特征相关性采用perarson系数来量化分析,以了解各字段之间的相关性能,从而避免模型拟合出现过度的共线性现象,在python语言环境中仅需要通过语句data.drop(columns=[‘id’,‘label’]).corr(method=‘pearson’)实现,具体系数分布结果如图6所示。
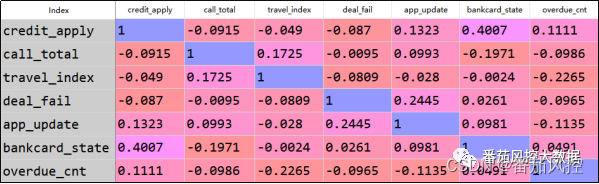
图6 特征相关性系数
由以上特征相关性系数结果可知,各变量之间的相关系数均表现较小,最大值也不超过0.5,因此特征变量之间的相关性较弱,有利于模型的训练拟合。接下来看特征的预测性,这里采用常见的信息值IV来评估,具体采用无监督的等距方式来完成,实现过程详见知识星球代码详情,输出结果如图8所示。
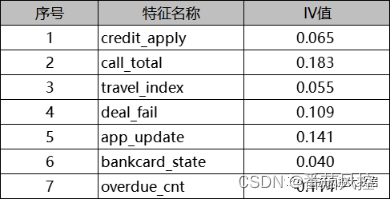
图8 特征IV值分布
通过特征IV值的分布结果可知,各字段的信息值均大于0.02,对目标的预测能力整体表现尚可,因此可用于模型拟合的变量范围。
2.3 单一模型效果
为了更客观的介绍串行组合模型的效果,我们选用4个常见的机器学习分类算法来建立信用风险评估模型,分别为逻辑回归LR、XGBoost、LightGBM、随机森林RF。在实现模型串行组合之前,我们有必要采用各个分类算法来依次构建模型,并对各模型的区分效果进行评估,这样为后续串行组合模型的性能对比作参照对象。
针对逻辑回归、XGBoost、LightGBM、随机森林,模型训练与模型评估的具体实现过程详见知识星球代码详情。为了保持模型参数相对统一,除了大部分参数取默认值外,对于本例决策树类的算法模型(XGBoost、LightGBM、随机森林),重要参数树的数量n_estimators=20、树的深度max_depth=5、学习率learning_rate=0.1均定义为相同值。
通过以上各单一模型的训练拟合与性能评估过程,得到各模型的量化指标表现,这里选取Accuracy、AUC、KS指标来进行对比分析,具体分布结果如图13所示。
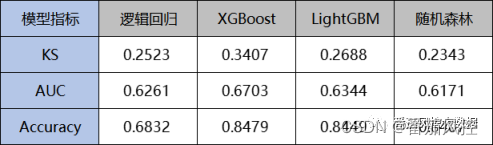
图13 子模型性能对比
2.4 串行模型实现
为了验证串行那个组合模型的性能优势,下面我们按照逻辑回归、XGBoost、LightGBM、随机森林的顺序来串联模型。对于各阶段的模型训练环节,由于逻辑回归模型排在首位,训练数据仅为原始样本数据,而后续各模型的输入数据除了原始数据外,还包括上一个模型输出的预测结果数据,具体体现为对目标变量正例值1的预测概率。
本实例异类串行组合模型的示意流程如图14所示,各模型的训练参数与前边单一模型均保持相同。按照LR、LR+XGB、LR+XGB+LGBM、LR+XGB+LGBM+RF的模型叠加串联,具体实现过程详见知识星球代码详情。
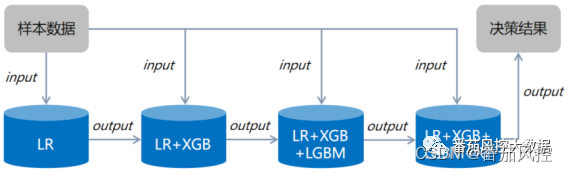
图14 串行组合模型实例
按照以上异类模型串行组合的实现过程,对于LR、LR+XGB、LR+XGB+LGBM、LR+XGB+LGBM+RF这4个模型训练环节,相应的模型性能指标结果如图18所示。由图可直观的了解到,随着串行子模型的叠加融合,综合模型的KS、AUC、Accuracy指标效果逐渐提升,有效证明了串行组合思想对模型效果提升的作用。同时,最终组合模型LR+XGB+LGBM+RF的性能指标,要优于各个单一模型的效果(图13),进一步说明了串行组合模型的有效性。
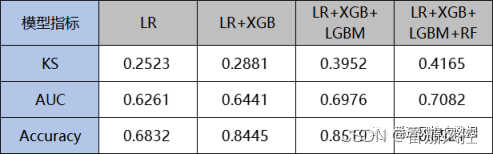
图18串行模型性能分布
3、串行模型性能调优
以上串行组合模型的实现,我们是按照LR+XGB+LGBM+RF的顺序来递进完成的,虽然综合效果与单一模型相比有较明显的提升,但仍有一定程度的提升空间。在上文对串行组合模型原理的介绍中,我们提到通常情况下类似随机森林等精度较高的模型优先排在前边位置,而逻辑回归等传统模型可考虑放在后边。为了验证串行子模型顺序对综合模型效果的影响,我们将逻辑回归LR调整至末位,而将XGBoost模型置于首位,调整顺序后的串行组合为XGB+LGBM+RF+LR,接下来按照这个流程来建立模型,具体实现过程与前边串联组合LR+XGB+LGBM+RF同理,相关代码详见本文附件材料。这里来看下经调优后模型训练过程各环节的模型性能情况,具体指标结果如图19所示。
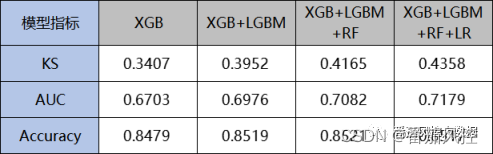
图19 串行模型调优性能
由以上结果可以看出,当逻辑回归LR模型调整至最后位置后形成串行组合XGB+LGBM+RF+LR,模型的最终性能评价指标KS与AUC,与前文调优前的串行组合LR+XGB+LGBM+RF结果(图18)相比均有所提高,其中KS从0.4165提升至0.4358,AUC从0.7082提升至0.7179,Accuracy则基本保持稳定(0.8521与0.8517),整体提升效果是显而易见的。因此,在串行组合模型的类型与数量保持一定情况下,模型的顺序也会影响最终综合模型的效果,合理的配置模型位置,有利于模型性能的优化。
综合以上内容,我们首先介绍了串行组合模型的原理思想与划分类型,然后以常用的异类串行组合模型为例,围绕贷前信用风险评估的二分类场景,以及具体的实例样本数据,建立了串行组合模型,对比分析了串行组合模型相对单一子模型的效果提升。此外,通过串行组合的模型顺序调整,验证了不同模型串行位置对最终模型性能的影响。因此,串行组合模型对于实际场景的数据建模有很好的参考意义与应用价值。
为了便于大家对串行组合模型有进一步理解与熟悉,本文额外附带了与以上内容同步且更为详细的Python代码与样本数据,供大家参考学习,详情请移至知识星球查看相关内容。
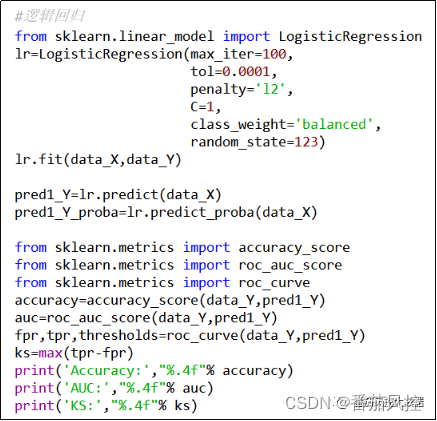
逻辑回归模型训练与评估
随机森林模型训练与评估
LR+XGB+LGBM+RF模型串联
…
~原创文章
![[附源码]计算机毕业设计JAVA中达小区物业管理系统](https://img-blog.csdnimg.cn/7fbe4f764ddb471d8fb9128812b2faa0.png)







![[附源码]Python计算机毕业设计SSM基于自组网的空地一体化信息系统(程序+LW)](https://img-blog.csdnimg.cn/6100a11d381b477d8b3a6a9cefbe6cef.png)

![[附源码]Python计算机毕业设计SSM计算机软考系统的设计与实现(程序+LW)](https://img-blog.csdnimg.cn/aa760a4acee94c688f778cc040ce09b8.png)