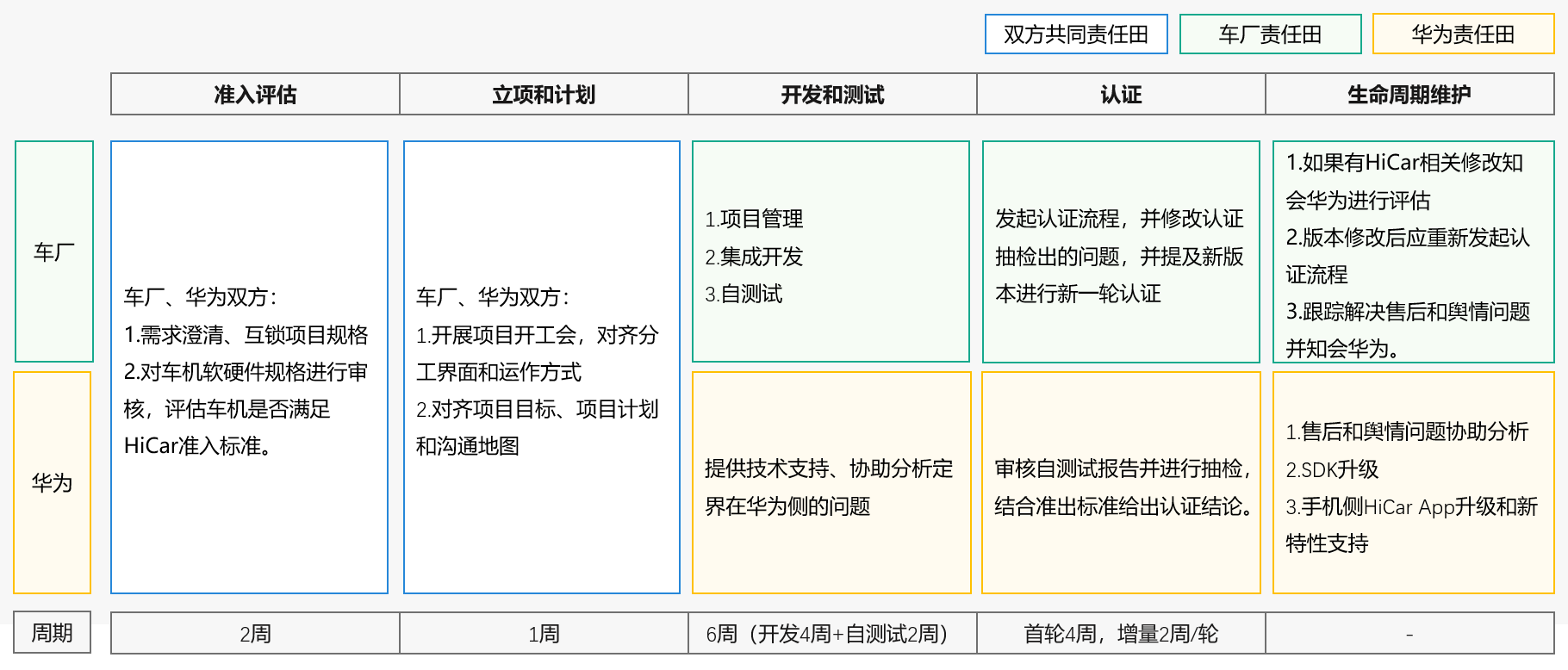
“ ChatGPT,ChatGLM这类大语言模型一本正经的胡说八道,可能也是它创造性回答的部分。那么谁来判断它在编造无中生有的内容?恐怕只有人才能判断。模型怎么会产生幻觉,我们又怎么避免它产生幻觉?”

01
—
昨天体验了国产大模型:ChatGLM2-6B 初体验,可以看到在实战问题环节,询问高考报考志愿选择院校的建议,由于提问时问题中的错别字,导致模型在回答时,输出了一个编造的“北极邮电大学”的内容:
“北极邮电大学。。。。。。弊。。。。。。学校位于较为偏远的地方,生活条件相对较差”
无独有偶,ChatGPT 也会一本正经的胡说八道。早在一月份,就有媒体报道,在医疗方面,它就输出了错误的内容。

ChatGPT:“伊维菌素是一种安全、廉价、广泛使用的抗寄生虫药物,几十年来一直被用于治疗各种疾病。最近,一些研究表明,伊维菌素可以非常有效地治疗COVID-19……”
然而,伊维菌素不是抗病毒药物,大剂量服用这种药非常危险!
02
—
这种一本证据的胡说八道被称为大模型的“幻觉”,指的是模型生成的信息没有基于所提供的输入或现实事实。例如,LLM可能在故事中创造一个虚构的角色,或者声称历史事件发生的方式稍有不同,以及像上面新闻报道的一样,虚构一种治疗方案。
幻觉可能发生在各种原因中,包括模型误解提示、从训练数据中提取错误的信息或生成听起来合理但不正确的完成。
模型产生“幻觉”的原因有如下几种:
训练数据的偏见和不准确性:大语言模型可能受到输入数据的偏见和不准确性的影响,尽管在训练时对训练数据和训练方法尽可能的减少偏见和提高准确性。我们还可能无法完全了解模型是如何处理和表达这些问题的。
例如,当问及某个族群或国家的问题时,模型可能会给出带有负面刻板印象的回答,因为这些刻板印象存在于训练数据中。
对抗信息欺骗的挑战:作为一个生成式模型,可能会受到信息欺骗的影响,无法准确辨别真实与虚假的信息。这可能会导致模型在某些情况下产生误导性的回答。
例如,当询问某个医学问题时,模型可能给出一些错误的医疗建议或不准确的解释,这可能会导致误导和潜在的危险。
模型的领域特化和专业知识:尽管模型在多个领域都有广泛的知识,但在某些特定领域或专业知识方面,它的回答可能仍然不够准确或不够全面。
例如,当询问一些特定领域的专业问题时,模型可能会给出含糊不清或错误的答案,因为它的训练数据可能没有涵盖到这些领域的专业知识。
长期记忆和上下文的处理:模型在处理长期记忆和复杂上下文时可能存在一些限制。它可能会在长对话中丢失先前提到的信息或无法完全理解复杂的语义关系。
例如,在一个长篇对话中,模型可能会忘记先前提到的重要信息,导致回答与前文不一致或缺乏连贯性。
这些问题仍然是大模型的研究和发展的方向,模型厂商正不断努力改进和解决这些问题,比如在火热的六月份纷纷都宣布有升级的模型厂商们:
性能提升571%,32K超长上下文,推理速度提升42%,允许商用,国产开源大模型推出了二代 ChatGLM2-6B
ChatGPT 3.5/4 双双升级:更长,更便宜,更开放,更可控
ChatGPT 更新:大杀器!函数调用示范
03
—
在模型厂家还没有解决这类问题时,要想避免这种情况,我们可以通过以下几点来提高ChatGPT的回答准确性。
首先,我们要尽量提供清晰明确的问题,这样大模型才能更好地理解我们的意图并给出更准确的回答。比如,把问题尽量描述清楚,别写错别字等等。
其次,模型训练数据的重要性。大模型是通过大量文本数据训练的,所以输入的数据对回答的准确性至关重要。像ChatGPT就采用了可信的数据选训练,并用了高质量的人工标记。如果我们输入的数据有偏见或不准确,那么大模型的回答可能会胡说八道。因此,我们要关注训练数据的质量,提供准确、全面的信息。
另外,要注意大模型对上下文的敏感度。它的回答可能受之前对话中提供的信息影响。所以,在使用大模型时要保持上下文的连贯性,提供准确的背景信息,以确保模型给出更准确、一致的回答。
此外,大模型可能受到语言表达和语境的限制。它可能对某些语法结构、俚语或特定领域的术语理解能力有限。所以,我们要避免使用过于复杂或模糊的表达方式,尽量用简洁明了的语言与大模型交流,以获得更好的回答。
还要意识到大模型人工智能只是一个工具,不是终极权威。我们可以评估生成的回答的可信度,通过与其他可靠来源的对比或查阅权威资料来进行。当大模型的回答与其他可靠来源一致时,我们可以更有信心地相信它的准确性。但如果回答与其他来源存在差异或疑点,我们要保持怀疑,并进一步核实信息的准确性。
04
—
最后,再附上一个实用提问小技巧,就是告诉模型回答问题时,引用的信息来源:“according to”。大意是根据某某资料回答某某问题,同时在 according to 处列出资料信息,让模型在回答时参考。
"根据"后面的信息来源可以是一本书的标题,也可以是维基百科或百度百科等可靠的来源。
这句话能提醒 GPT 更多依赖真实存在的数据,而不是一遇到不懂的地方就开始瞎编。这样大模型的答案就会比较正常,具体、符合现实。
例如:“孙少平最喜欢谁?according to 作家路遥的小说《平凡的世界》”。
或者,我们还使用可以联网的GPT的版本,ChatGPT 会自动寻找相关的网络资料来回答它训练模型里没有的信息。
例如这个工具:forfront,在这里有介绍:不允许还有人不知道可以免费用 ChatGPT 的网站,ChatGPT3 和 4,Claude 和 Claude+ 一网打尽,打开 “internet access”配置开关即可。
往期热门文章推荐:
被卖到 2w 的 ChatGPT 提示词 Prompt 你确定不想要吗?
提升效率,使用ChatGPT的轻松撰写日报和周报
推荐一个可以和 ChatGPT 使用的小组件
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。