BeautifulSoup爬取豆瓣TOP250
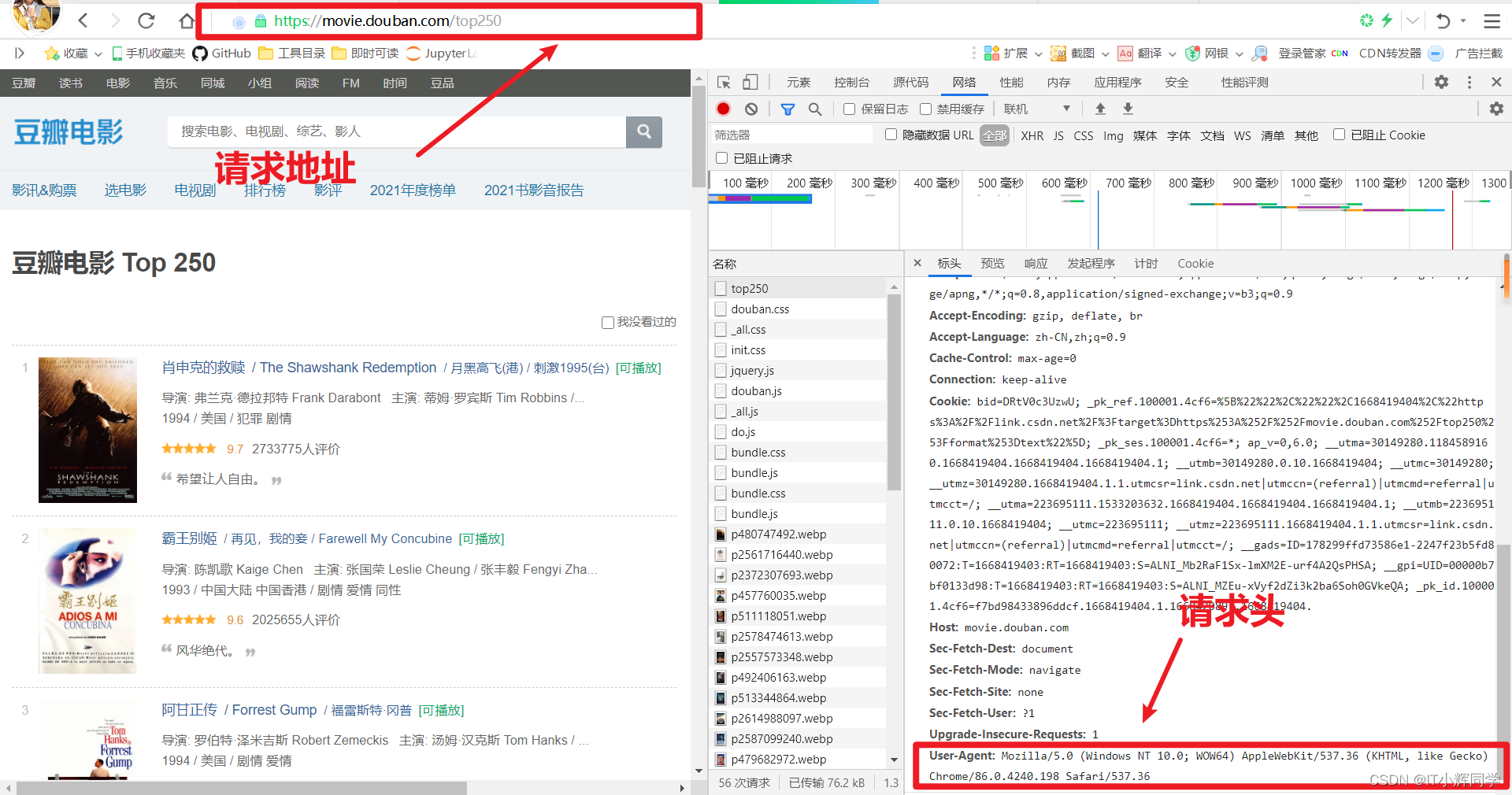
豆瓣爬取地址
https://movie.douban.com/top250?format=text
BeautifulSoup官网地址
https://www.rddoc.com/doc/BeautifulSoup/4.5.3/zh/quick-start/
安装所需函数库
pip install beautifulsoup4
pip install lxml
pip install requests
导入所需函数库
import lxml
import pandas as pd
import requests as rq
from bs4 import BeautifulSoup as bs
测试访问
#访问目标
url="https://movie.douban.com/top250"
#设置请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#进行访问
html=rq.get(url,headers=headers)
# 这是判断可否爬取的成功,等于200既成功
html.encoding=html.apparent_encoding
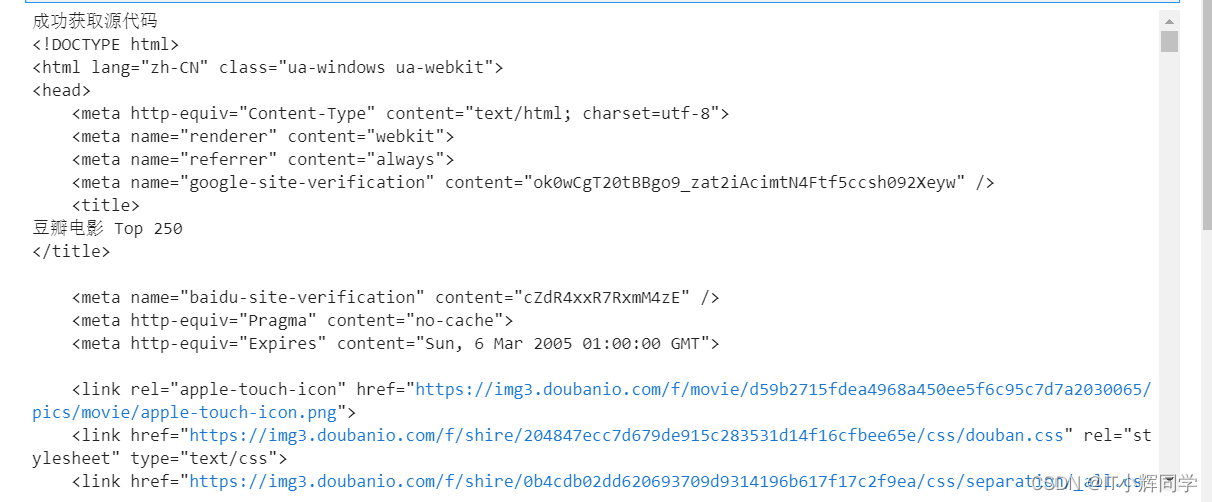
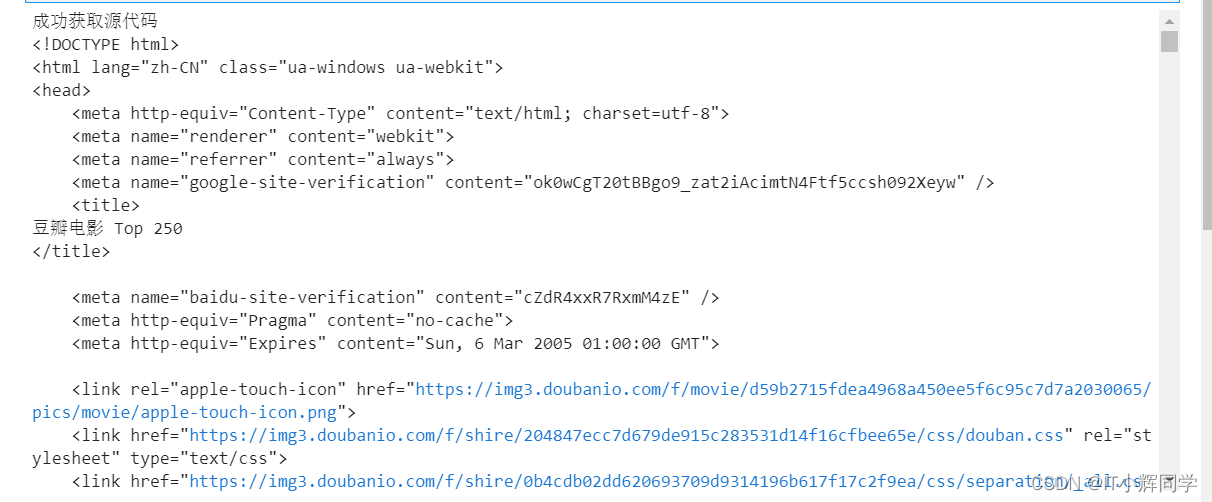
if html.status_code == 200:
print("成功获取源代码")
print(html.text)
else:
print("访问失败")
获取所有的电影名数据
#访问目标
url="https://movie.douban.com/top250"
#设置请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#进行访问
html=rq.get(url,headers=headers)
# 这是判断可否爬取的成功,等于200既成功
html.encoding=html.apparent_encoding
#网页解析
page=bs(html.text,"html.parser")
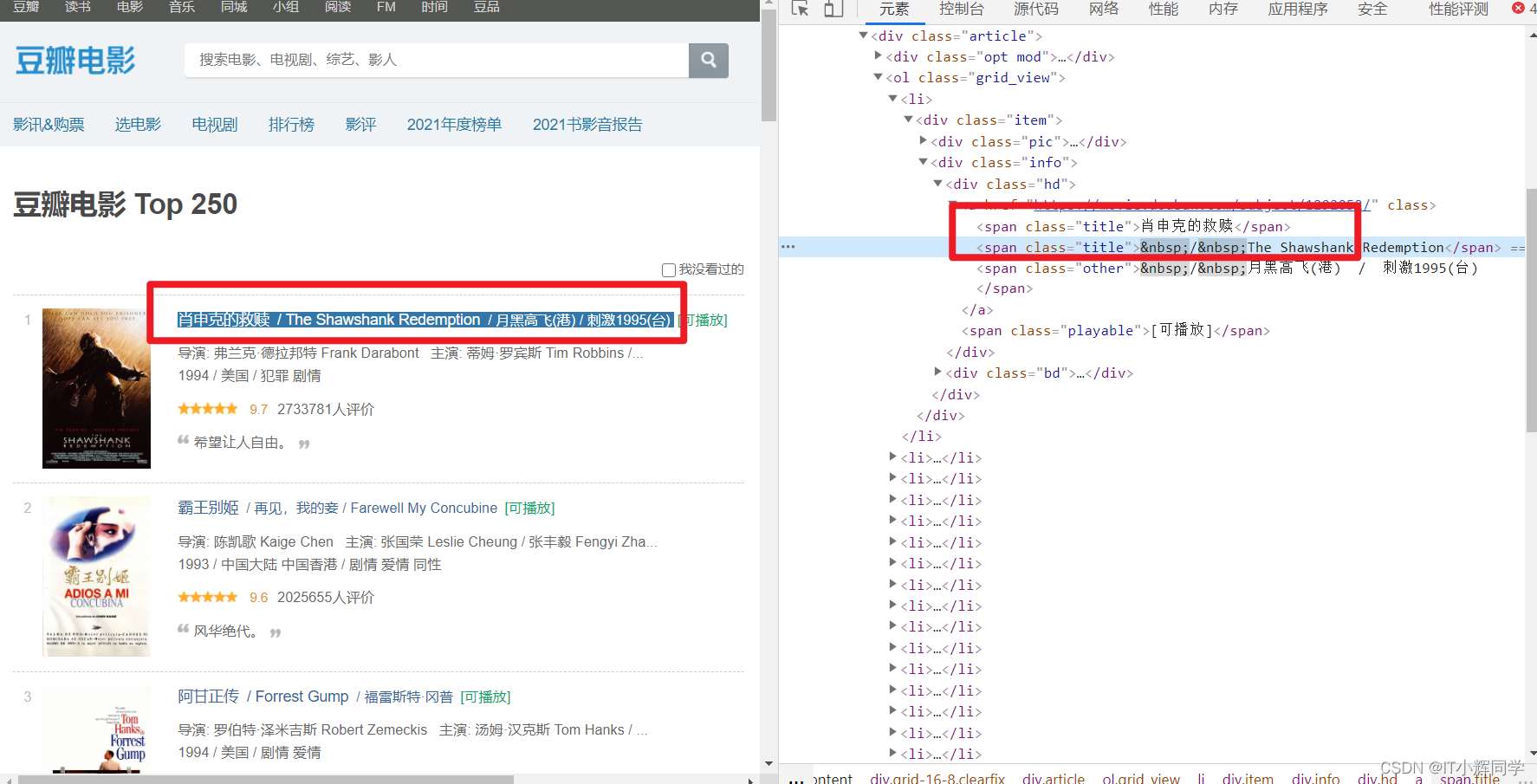
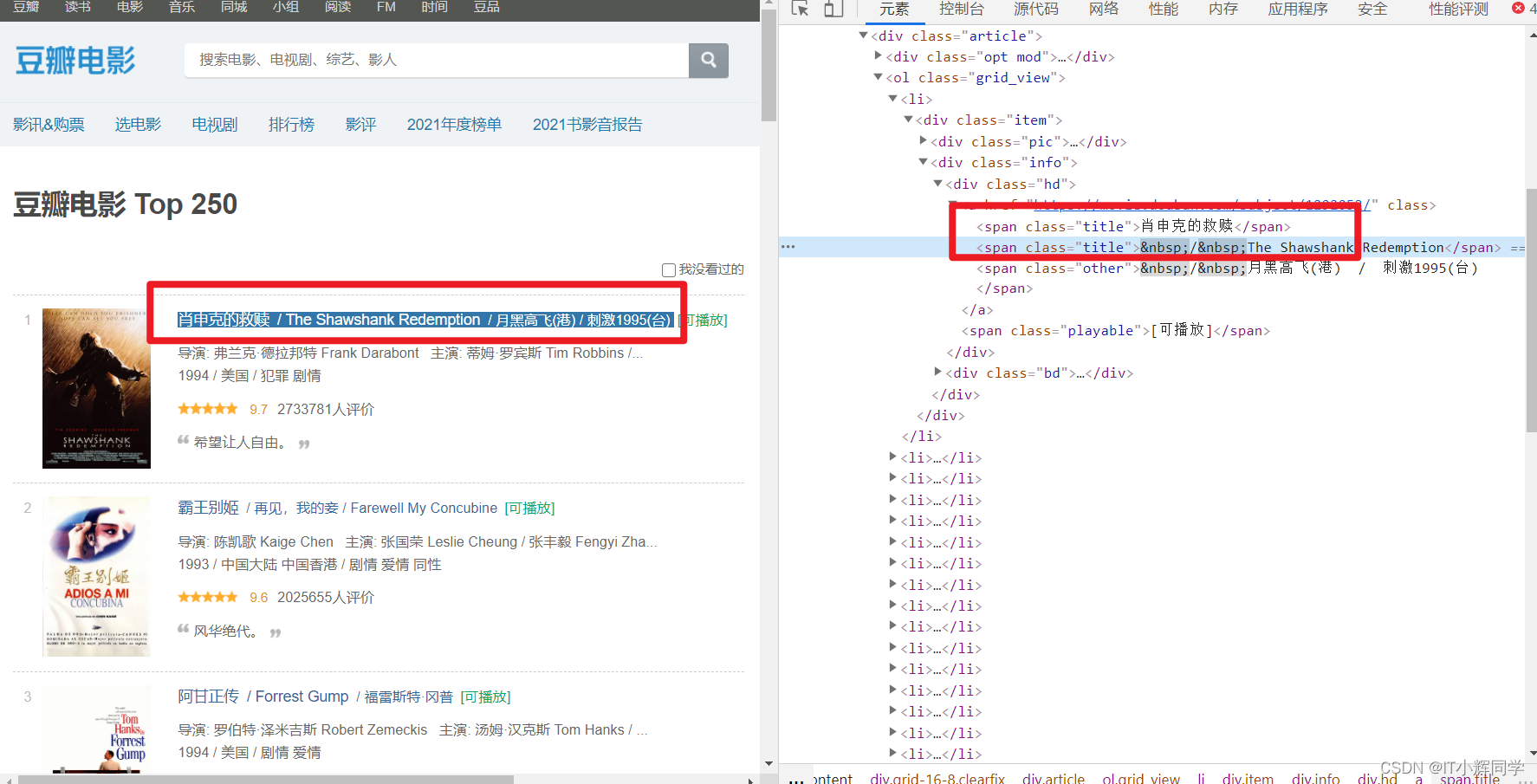
#获取所有的标签名为span,class=title的标签
titles=page.find_all("span",class_="title")
#此处避免文章过于累赘,只输出前五条
print(titles[:5])
[<span class="title">肖申克的救赎</span>, <span class="title"> / The Shawshank Redemption</span>, <span class="title">霸王别姬</span>, <span class="title">阿甘正传</span>, <span class="title"> / Forrest Gump</span>]
对于数据进行二次解析
#定义标题列表
title_list=[]
for title in titles:
#获取电影名加入列表
title_list.append(title.text)
#输出前五条
title_list[:5]
['肖申克的救赎',
'\xa0/\xa0The Shawshank Redemption',
'霸王别姬',
'阿甘正传',
'\xa0/\xa0Forrest Gump']
对于数据进行剔除,只保留电影名(原数据包含导演,演员)
#访问目标
url="https://movie.douban.com/top250"
#设置请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#进行访问
html=rq.get(url,headers=headers)
# 这是判断可否爬取的成功,等于200既成功
html.encoding=html.apparent_encoding
#网页解析
page=bs(html.text,"html.parser")
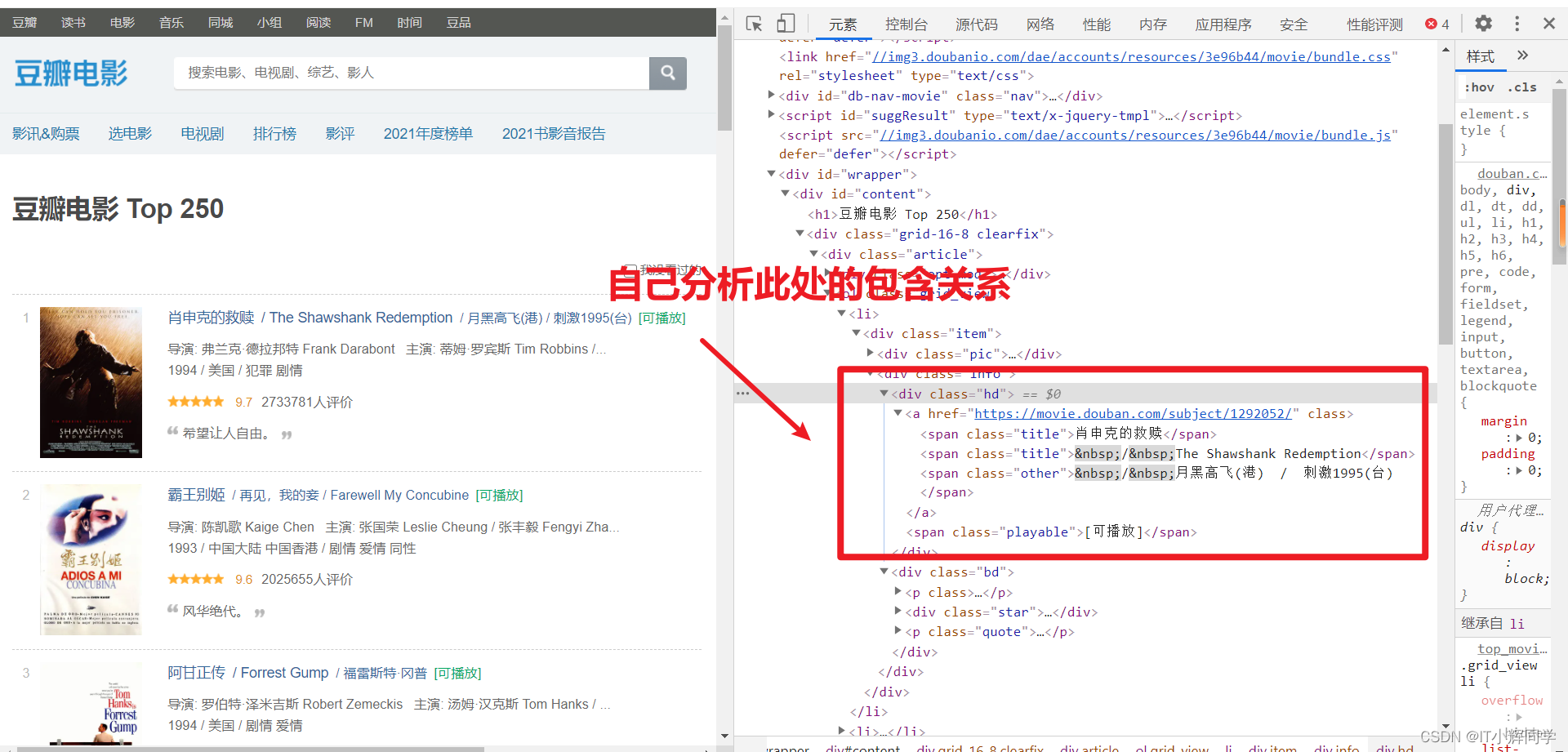
#获取所有的标签名为div,class=hd的标签
divs=page.find_all("div",class_="hd")
print(divs[:1])
[<div class="hd">
<a class="" href="https://movie.douban.com/subject/1292052/">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>]
title_list=[]
for tag in divs:
title=tag.find('span').string
title_list.append(title)
print(title_list)
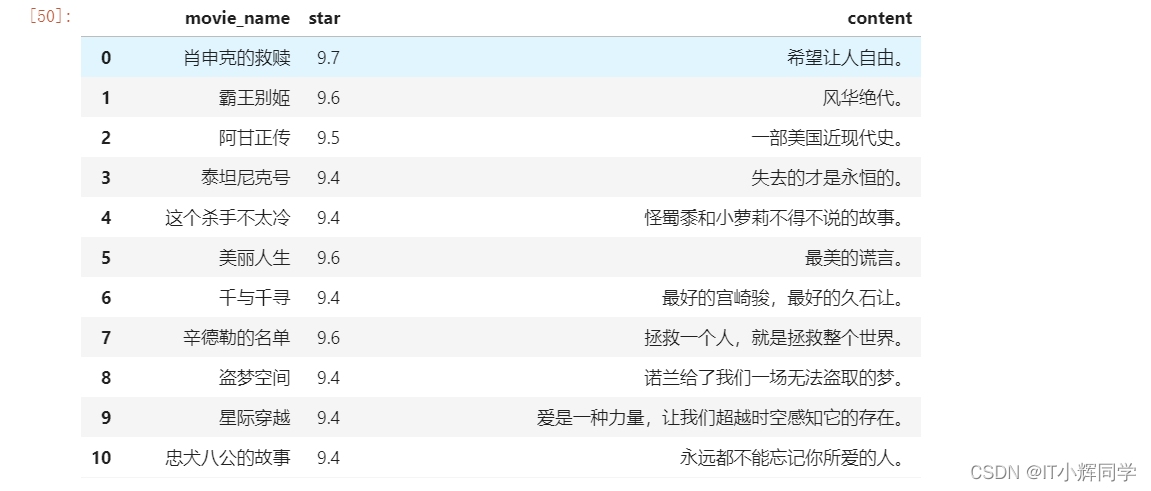
['肖申克的救赎', '霸王别姬', '阿甘正传', '泰坦尼克号', '这个杀手不太冷', '美丽人生', '千与千寻', '辛德勒的名单', '盗梦空间', '星际穿越', '忠犬八公的故事', '楚门的世界', '海上钢琴师', '三傻大闹宝莱坞', '机器人总动员', '放牛班的春天', '无间道', '疯狂动物城', '大话西游之大圣娶亲', '控方证人', '熔炉', '教父', '当幸福来敲门', '触不可及', '怦然心动']
完整代码展示(获取评分,电影名,评论)
#访问目标
url="https://movie.douban.com/top250"
#设置请求头
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
#进行访问
html=rq.get(url,headers=headers)
# 这是判断可否爬取的成功,等于200既成功
html.encoding=html.apparent_encoding
#网页解析
page=bs(html.text,"html.parser")
#获取所有的标签名为div,class=hd的标签
divs=page.find_all("div",class_="hd")
#获取原始评分数据
stars=page.find_all("span",class_="rating_num")
#获取原始电影简介数据
contens=page.find_all("span",class_="inq")
#定义电影名列表
title_list=[]
#定义评分列表
star_list=[]
#定义电影简介列表
conten_list=[]
for tag in divs:
#获取电影名
title=tag.find('span').string
#存入列表
title_list.append(title)
for star in stars:
#将评分数据存入列表
star_list.append(star.text)
for conten in contens:
#将评分数据存入列表
conten_list.append(conten.text)
#使用pandas读取数据展示
data = {'movie_name':title_list,'star':star_list,"content":conten_list}
pd_data=pd.DataFrame(data)
pd_data