特征组合也称特征交叉(Feature Crosses),即不同类型或者不同维度特征之间的交叉组合,其主要目的是提高对复杂关系的拟合能力。在特征工程中,通常会把一阶离散特征两两组合,构成高阶组合特征。可以进行组合的特征包括离散特征和连续特征,但是连续特征需要进行一定的处理后才可以进行特征组合。
为了便于理解,可以将特征组合理解为两个离散特征交叉合并,举个例子:特征 A 有 m 个类别,特征 B 有 n 个类别,则特征 A 和特征 B 的组合就是将特征 A、B 中的各个类别两两组合,其维度为 m*n。很明显,特征组合存在隐患——当一个特征的类别非常多的时候会出现组合特征向量维度极高的情况,这个时候还需要用到降维处理。
目录
1.为什么要进行特征组合?
2.特征交叉的种类
2.1 特征交叉:交叉 One-Hot 向量
3.参考文献
1.为什么要进行特征组合?
在图 1 和图 2 中,想象一下:
- 蓝点代表生病的树。
- 橙色点代表健康的树木。
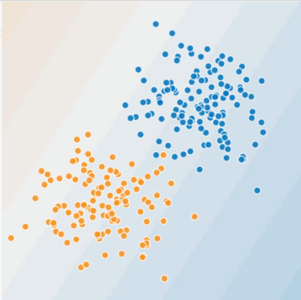
图 1 线性问题举例
对于图 1 而言,我们可以画一条线将病树和健康树分开。很明显,这是一个线性问题。虽然这条线并不完美。其中,少数生病的树可能是 “健康” 的,但是并不妨碍这条线的良好的预测能力。
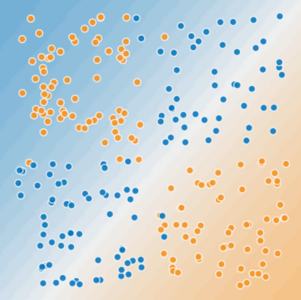
图 2 非线性问题举例
对于图 2,你能画一条直线将病树和健康树整齐地分开吗?显然是不能的。这是一个非线性问题。你画的任何线都不能很好地预测树木的健康状况。
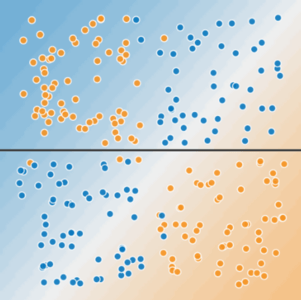
图 3 一条线无法分隔这两个类
要解决图 2 中所示的非线性问题,需要进行特征交叉。特征交叉是一种合成特征,通过将两个或多个输入特征相乘来刻画特征空间中的非线性。如下所示,我们创建一个名为 的交叉特征交
对于新建的交叉特征 ,我们可以像对待任何其他特征一样。线性公式变为:
线性算法可以学习权重 ,和
和
一样。换句话说,虽然
用于编码(刻画)非线性信息,但我们并不需要通过更改线性模型的训练方式来确定
的值。
在真实的世界中,很多问题都是非线性的,我们无法直接通过简单的特征来刻画事物之间的联系,而组合特征恰好为我们提供了一种解法。
2.特征交叉的种类
我们可以创建许多不同类型的特征组合。例如:
[A X B]:通过将两个特征的值相乘形成的特征交叉。[A x B x C x D x E]:五个特征值相乘形成的特征交叉。[A x A]:通过对单个特征进行平方而形成的特征交叉。
由于随机梯度下降,可以有效地训练线性模型。因此,用特征交叉来补充缩放线性模型一直是大规模数据集训练的有效方法。
2.1 特征交叉:交叉 One-Hot 向量
到目前为止,我们重点关注两个单独的浮点特征的交叉。在实践中,机器学习模型很少跨越连续特征。然而,机器学习模型确实经常交叉独热特征向量。将独热特征向量的特征交叉视为逻辑合取。例如,假设我们有两个特征:国家/地区和语言。每个 one-hot 的编码都会生成具有二进制特征的向量,这些特征可以解释为:country=USA, country=France 或 language=English, language=Spanish。然后,如果对这些 one-hot 编码进行特征交叉,将获得可以解释为逻辑连接的二进制特征,例如:
country:usa AND language:spanish
再举一个例子,假设对纬度和经度进行了分箱,生成五元素特征向量。例如,给定的纬度和经度可以表示如下:
binned_latitude = [0, 0, 0, 1, 0] binned_longitude = [0, 1, 0, 0, 0]
假设创建这两个特征向量的特征组合:
binned_latitude X binned_longitude
该特征组合是一个 25 元素的 one-hot 向量(24 个 0 和 1 个 1)。交叉结果中唯一的 1 表示纬度和经度的特定结合,将其作为特征输入模型,模型就可以学习有关该“特定结合”背后的特定关联。假设我们对纬度和经度进行更粗略的分类,如下所示:
binned_latitude(lat) = [ 0 < lat <= 10 10 < lat <= 20 20 < lat <= 30 ] binned_longitude(lon) = [ 0 < lon <= 15 15 < lon <= 30 ]
创建这些粗糙的特征交叉会产生具有以下含义的合成特征:
binned_latitude_X_longitude(lat, lon) = [ 0 < lat <= 10 AND 0 < lon <= 15 0 < lat <= 10 AND 15 < lon <= 30 10 < lat <= 20 AND 0 < lon <= 15 10 < lat <= 20 AND 15 < lon <= 30 20 < lat <= 30 AND 0 < lon <= 15 20 < lat <= 30 AND 15 < lon <= 30 ]
现在假设我们的模型需要根据两个特征来预测狗主人对狗的满意度:
- 行为类型(吠叫、哭泣、依偎等)
- 一天中的时间
如果我们从这两个特征构建一个特征交叉:
[behavior type X time of day]
那么,我们最终将获得比任何一个特征本身都要强得多的预测能力。例如,如果狗在下午 5:00 主人下班回来时(高兴地)哭泣,则很可能是主人满意度的一个很好的积极预测指标。凌晨 3:00 当主人熟睡时哭泣(也许很痛苦)很可能是主人满意度的强烈负面预测因素。
线性学习器可以很好地适应海量数据。在海量数据集上使用特征交叉是学习高度复杂模型的一种有效策略。神经网络 提供了另一种策略。
3.参考文献
链接-https://developers.google.cn/machine-learning/crash-course/feature-crosses/encoding-nonlinearity。