作品展示:
6*6切割=36图

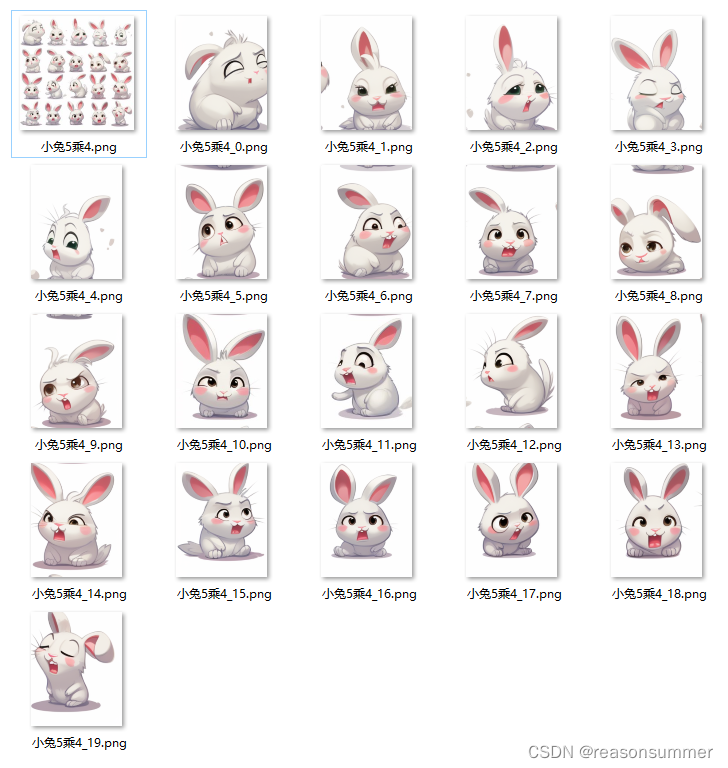
5*4图:20张
问题产生:
之前的代码是:一张图的四个坐标,有4张就要写4行。
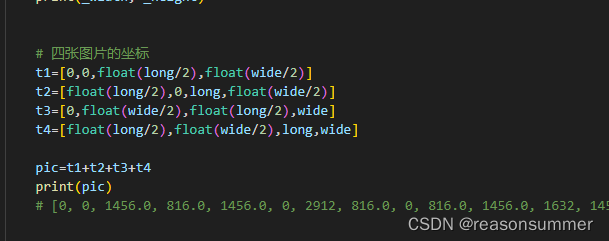
后续发现,Midjounery生成的图片矩阵X Y数量不等,不仅有3*3,还有4*3、5*4的结构,
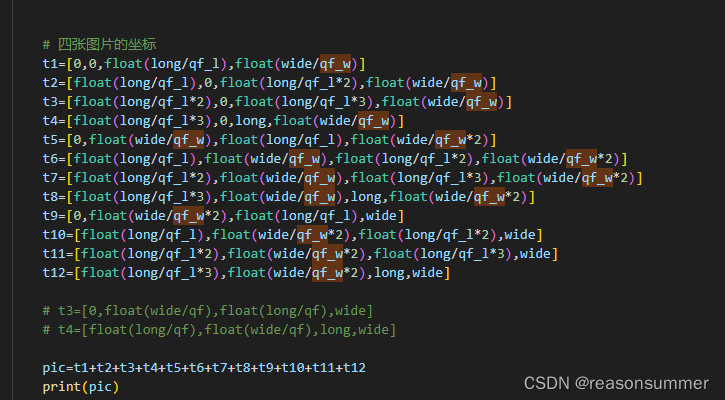
这样写的图片坐标列表,实在太多了,每一张图就要写一个PY文件
产生需求
用一个通用代码py,把Midjounery生成的表情图(数量不等)切割成3*3、5*4、4*3的小图
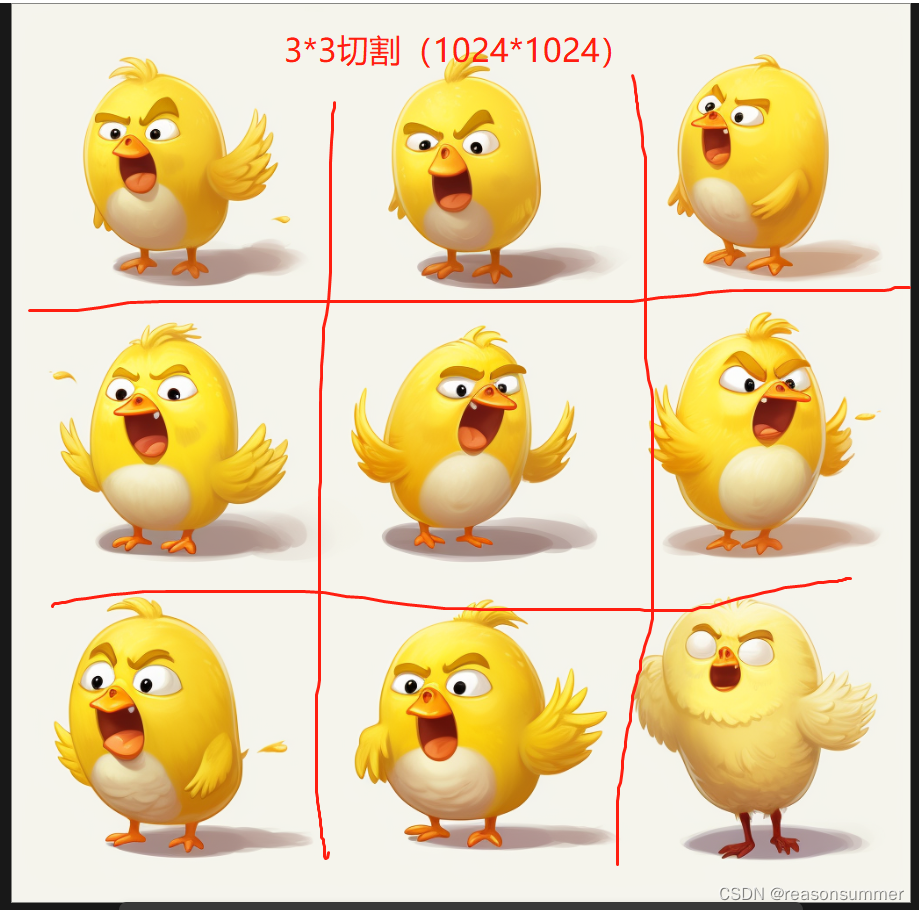

测算过程:
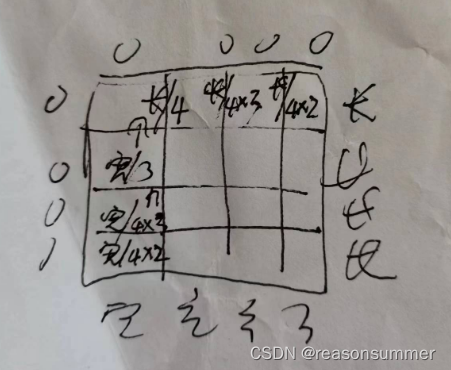

终于发现其中的规律
1、梳理坐标节点(所有节点数字做成列表)
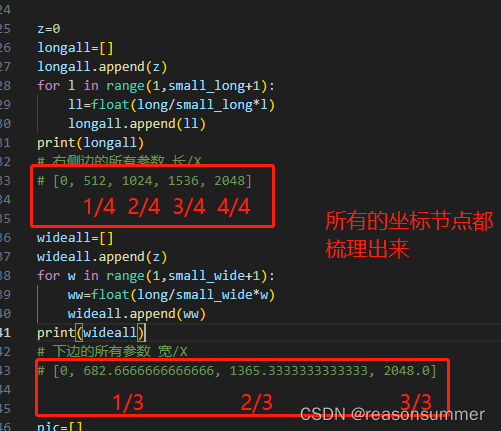
2、寻找坐标数字 变化的规律

代码:
# 参考网址:https://blog.csdn.net/weixin_42182534/article/details/125773141?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E6%88%AA%E5%8F%96%E5%9B%BE%E7%89%87%E7%9A%84%E4%B8%80%E9%83%A8%E5%88%86&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-125773141.nonecase&spm=1018.2226.3001.4187
'''
功能:把midjounery 3*3方形矩阵,5*4矩阵、3*5矩阵切割 通用公式)
作者:阿夏
时间:2023年6月26日 19:51
'''
from PIL import Image
import os
import os.path
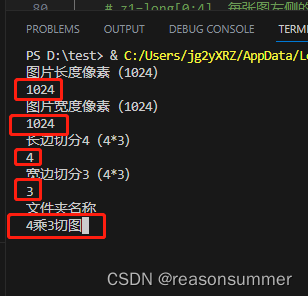
long=int(input('图片长度像素(1024)\n'))
wide=int(input('图片宽度像素(1024)\n'))
small_long=int(input('长边切分4(4*3)\n'))
small_wide=int(input('宽边切分3(4*3)\n'))
# 目前图片都是2*2,3*3排列
# 1:1图比例是2048
# 16:9图片比例 2912:1632
wj=input('文件夹名称\n')
z=0
longall=[]
longall.append(z)
for l in range(1,small_long+1):
ll=float(long/small_long*l)
longall.append(ll)
print(longall)
# 右侧边的所有参数 长/X
# [0, 512, 1024, 1536, 2048]
wideall=[]
wideall.append(z)
for w in range(1,small_wide+1):
ww=float(long/small_wide*w)
wideall.append(ww)
print(wideall)
# 下边的所有参数 宽/X
# [0, 682.6666666666666, 1365.3333333333333, 2048.0]
pic=[]
for x in range(0,small_wide):
for y in range(0,small_long):
z1=longall[y]
z2=wideall[x]
z3=longall[y+1]
z4=wideall[x+1]
pic.append(z1)
pic.append(z2)
pic.append(z3)
pic.append(z4)
print(len(pic))
# # 4*3图为例hang
# 第1行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[0]
# z3=longall[1] [2] [3] [4]
# z4=wideall[1]
# 第2行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[1]
# z3=longall[1] [2] [3] [4]
# z4=wideall[2]
# 第3行四张
# z1=longall[0] [1] [2] [3]
# z2=wideall[2]
# z3=longall[1] [2] [3] [4]
# z4=wideall[3]
# 总结:
# z1=long[0:4] 每张图左侧的坐标会变 ,索引数字不断从0,1/4,2/4,3/4
# z2=宽数量 宽的索引,不断增加
# z3=long[0+1:4+1] 每张图右侧 索引数+1 从1/4,2/4,3/4,4/4(=长)
# z4=宽+1 宽的索引+1
# 定义文件所在文件夹
image_dir = r'C:\Users\jg2yXRZ\OneDrive\桌面\{}'.format(wj)
for parent, dir_name, file_names in os.walk(image_dir): # 遍历每一张图片
for filename in file_names:
print(filename)
pic_name = os.path.join(parent, filename)
image = Image.open(pic_name)
_width, _height = image.size
print(_width, _height)
qfall=4
# 每张图有4个坐标
n=0
for p in range(int(len(pic)/4)):
pp=pic[p*4:p*4+4]
print(pp)
# 定义裁剪范围(left, upper, right, lower)1024
# # box = image.crop((0,0,123,123))
box = image.crop((pp[0],pp[1],pp[2],pp[3]))
name = filename[:-4]+'_'+str(n) +'.png'
print(name)
# # # ,pp[3],pp[4],pp[5],pp[6],pp[7],pp[8],pp[9]))
# # name = filename[:-4]+'_'+str(p) +'.png'
box.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\{}\{}'.format(wj,name))
n+=1
# print('Done!')
终端输入:
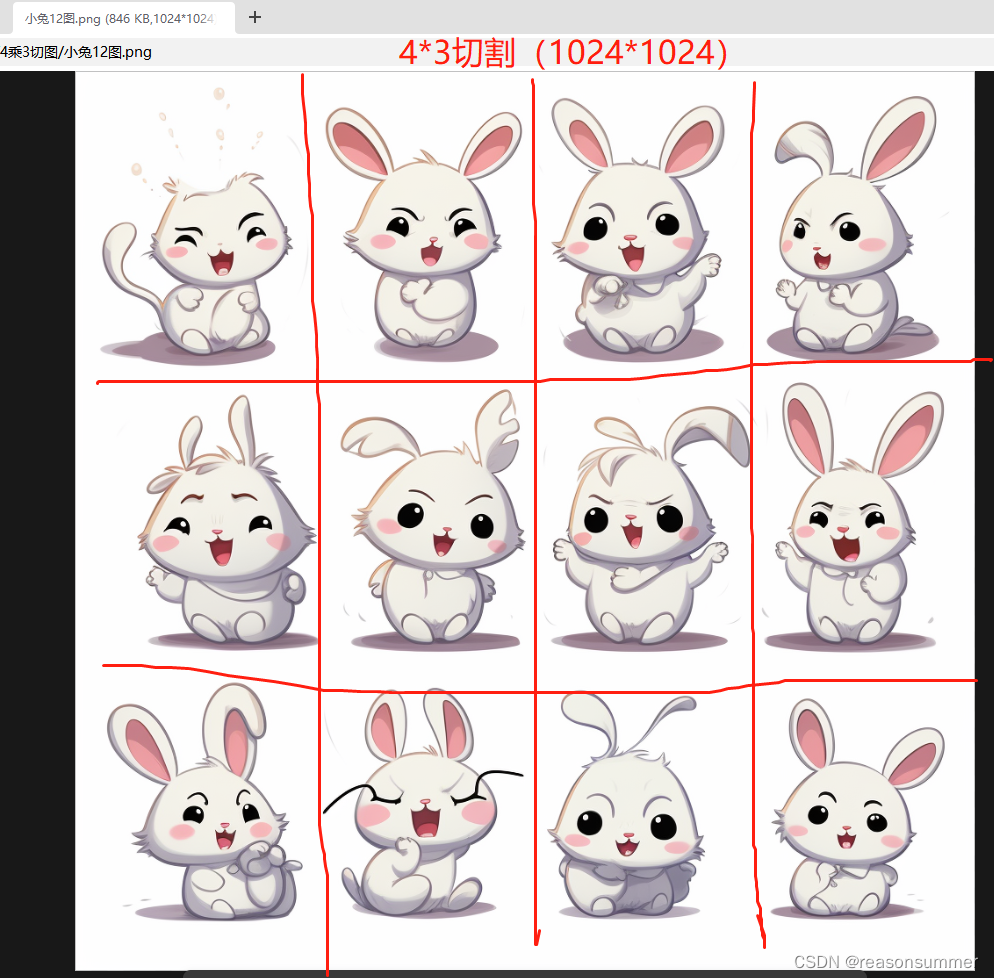
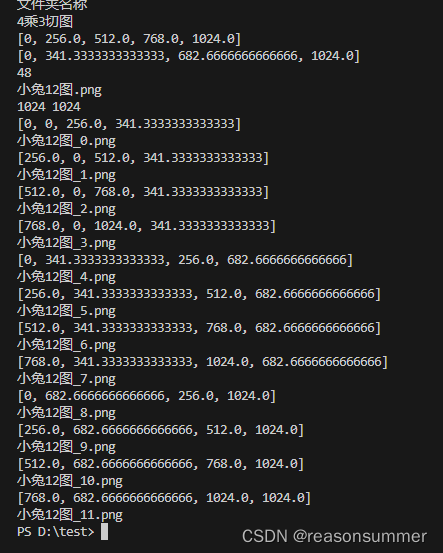
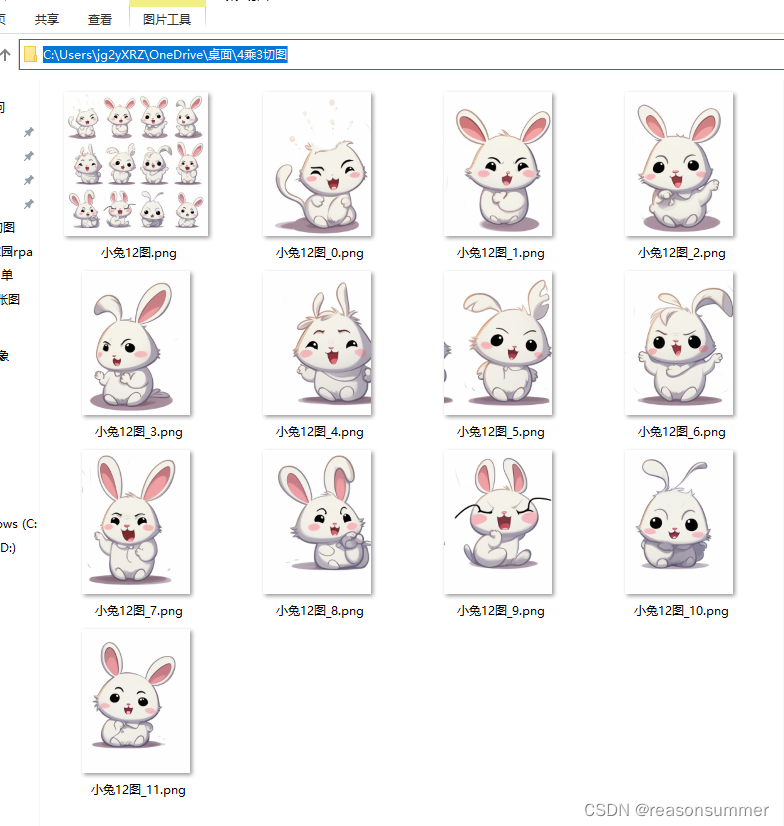
1、以4*3小兔图片为例

终端输入
1、以6*6男孩表情包图片为例
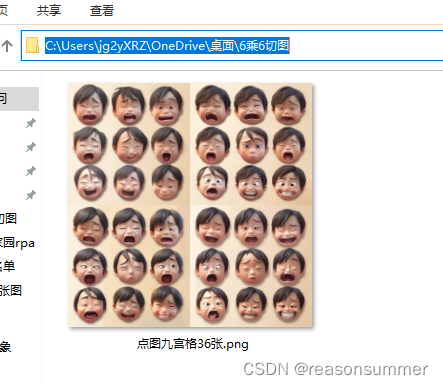


终端输入


等分切割,不能保证每张小图都在正中位置,智能大致切割
因此表情图最好能够不粘连的,矩阵结构清晰的。
来两张PDF