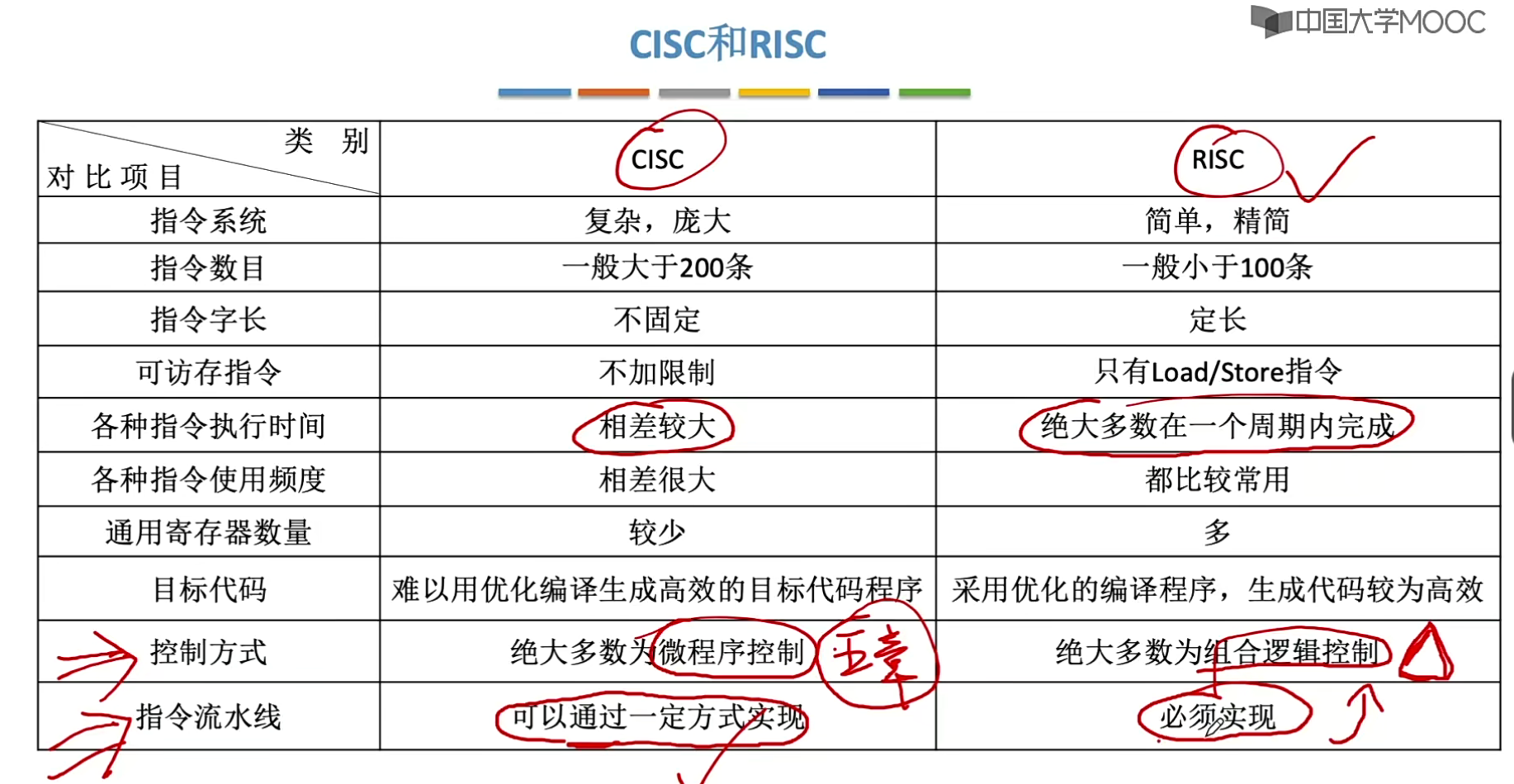
论文背景
虚拟点云生成时,从图像中生成的虚拟点非常密集,在检测过程中引入了大量的冗馀计算量。同时,不准确的深度补全所带来的噪声会显著降低检测精度。
早期利用图像特征扩展LiDAR点的特征的方法,如语义掩膜和二维CNN特征。他们没有增加点数,因此,远处的点仍然稀疏。
相比之下,基于 虚拟/伪 点的方法通过在LiDAR点周围创建额外的点来丰富稀疏点云。
虚拟点补全了远处物体的几何形状 ,然而,从图像生成的虚拟点通常非常密集。这带来了巨大的计算负担和严重的效率问题。
以前的工作通过使用更大的体素尺寸或通过随机向下采样]点来解决密度问题,但是,这样会牺牲来自远处点的 useful cues 线索,导致检测精度下降。
由于在三维空间中很难将噪声与背景区分开,导致 3D 检测的定位精度大大降低,另外,噪声点是非高斯分布,不能用常规的去噪算法滤除 。因此,深度补全可能是不准确的。
论文创新点
论文提出了基于虚拟稀疏卷积(VirConv)算子的 VirConvNet。
首先,LiDAR扫描中附近物体的几何形状通常相对完整。因此,大多数附近物体的虚拟点只会带来很小的性能提升,但会显著增加计算成本。
其次,由不准确的深度补全引入的噪点大多分布在实例边界上。它们在投影到图像平面后可以在2D图像中被识别出来。
1.随机体素丢弃 StVD(Stochastic Voxel Discard)
通过基于 bin 的采样来保留那些最重要的虚点,即丢弃大量附近的体素,同时保留远处的体素。 这样可以大大加快网络计算速度。
2.抗噪声子流形卷积 NRConv (Noise-Resistant Submanifold Convolution)
在三维空间和二维图像空间中对体素的几何特征进行编码,NRConv 在2D空间中的扩展感受野使其能够在2D图像空间中区分实例边界上的噪音模式。因此,噪音的负面影响可以被抑制。
开发了三种多模态检测器来展示 VirConv 的优越性
1.由Voxel-RCNN构建的轻量级 Virconv-L;
2.基于多级和多变换设计的高精度 Virconv-T ;
3.一个基于伪标签框架的半监督 VirConv-S。
论文内容
 (a) VirConv 块由 StVD 层、一些NRConv层和一个3D SpConv层组成。
(a) VirConv 块由 StVD 层、一些NRConv层和一个3D SpConv层组成。
(b)NRConv 将体素投影回图像空间,并在2D和3D空间中编码虚拟点特征。
(c) VirConv-L 将 LiDAR 点和虚拟点融合成一个单独的点云,并通过 VirConvNet 对多模态特征进行3D检测编码。
VirconvNet 首先将点转换为体素,然后通过一系列Virconv块以1×、2×、4×、8×下采样步长将体素逐步编码为特征体。
VirConv Block 由三部分组成:
1.STVD层,用于加快网络速度并提高密度鲁棒性;
2.多个 NRConv 层,用于编码特征并降低噪声的影响;
3.一个 3D SpConv 层,用于向下采样特征映射。
用于数据融合的虚拟点
将激光雷达点 和 虚拟点 分别描述为
P
\boldsymbol {P}
P 和
V
\boldsymbol {V}
V。
有两种流行的融合方案:
1.早期融合。它将
P
\boldsymbol {P}
P 和
V
\boldsymbol {V}
V 融合到单个点云
P
∗
\boldsymbol {P^*}
P∗ 中,并使用现有的探测器进行 3D 目标检测。
2.晚期融合。通过不同的 backbone networks 对
P
\boldsymbol {P}
P 和
V
\boldsymbol {V}
V 的特征进行编码,并在BEV平面或局部ROI中融合这两种特征。
这两种融合方法都存在虚拟点密集和噪声的问题。
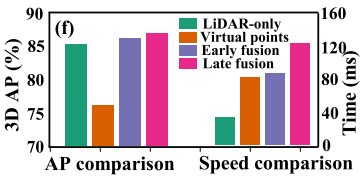
密集问题
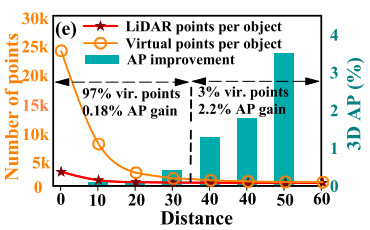
为近景物体引入的大量虚拟点是多余的。具体来说,97%的虚拟点来自近景的对象,仅带来0.18%的性能提升,而3%的虚拟点来自远景的对象,带来2.2%的性能提升。
噪声问题
通过深度补全网络产生的虚拟点通常是有噪声的。噪声主要是由不准确的深度补全引入的,在三维空间中很难区分。 仅使用虚拟点,与仅使用激光雷达的探测器相比,探测性能有所下降。 此外,噪声点是非高斯分布的,传统去噪算法无法滤除噪声。
观察到噪声主要分布在实例边界上,在2D图像中更容易识别。虽然可以用边缘检测来粗略地去除噪声,但这将牺牲有利于物体形状和位置估计的有用边界点。
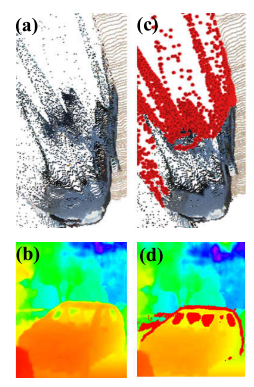
a)三维空间中的虚拟点。 (b)二维空间中的虚点。 ©三维空间中的噪声(红色)。 (d)分布在二维实例边界上的噪声(红色)
随机体素丢弃
1.输入 StVD,通过在训练和推理过程中丢弃虚拟点的输入体素来加快网络的速度;
两种简单的方法可以保留较少的输入体素:(1)随机采样(2)最远点采样(FPS).
然而,随机采样通常在不同的距离上保持不平衡的体素,不可避免地牺牲了一些有用的形状线索。此外,由于计算复杂度高,FPS在对大量虚拟点进行下采样时需要大量的额外计算
O
(
n
2
)
O(n^2)
O(n2) 。
 (a)(b) 分别给出所有体素和附近体素随机采样后的体素分布
(a)(b) 分别给出所有体素和附近体素随机采样后的体素分布
(c) 表示所有体素基于bin采样后的体素分布。
基于bin的采样策略
首先将输入体素按照距离的不同划分为
N
b
N^b
Nb 个 Bins(本文采用
N
b
N^b
Nb =10)。对于距离近的 bins (
≤
30
m
\leq 30m
≤30m) ,随机保留固定数目(~
1
K
1K
1K)的体素。 对于远处的 bins,保存所有内部的体素。
丢弃了大约90%的冗余体素(这达到了最佳的精度-效率权衡),它使网络速度提高了大约2倍

2.层 StVD,通过只在训练过程中丢弃每个 VirConv 块的虚拟点体素来提高密度鲁棒性。
在每个 VirConv 块上丢弃体素,以模拟更稀疏的训练样本。论文文采用15%的丢弃率。
层StVD作为一种数据增强策略来辅助增强 3D 检测器的训练。

抗噪声子流形卷积
给定 N 个输入体素,由一个 3D 索引向量 H ∈ R N × 3 \boldsymbol H \in \R^{N \times 3} H∈RN×3 和一个特征向量 X ∈ R N × C i n \boldsymbol X \in \R^{N \times C^{in}} X∈RN×Cin,在3D和2D图像空间中对抗噪几何特征 Y ∈ R N × C o u t \boldsymbol Y \in \R^{N×C^{out}} Y∈RN×Cout 进行编码,这里 C i n , C o u t C^{in},C^{out} Cin,Cout 分别表示输入输出特征通道数。
编码三维空间中的几何特征
对于
X
\boldsymbol X
X 中的每个体素特征
X
i
X_i
Xi,首先通过 3D 子流形卷积核
K
3
D
(
⋅
)
{\cal K}^{3D}(\cdot)
K3D(⋅) 对几何特征进行编码。从
3
×
3
×
3
3×3×3
3×3×3 邻域内的非空体素,根据相应的3D 索引计算出几何特征
X
^
i
∈
R
C
o
u
t
/
2
\hat X_i \in \R^{C^{out}/2}
X^i∈RCout/2:
X
^
i
=
R
{
K
3
D
(
X
i
,
X
i
(
f
1
)
,
.
.
.
,
X
i
(
f
j
)
)
}
(1)
\tag 1\hat X_i= {\cal {R}}\{ {\cal {K}}^{3D}(X_i,X_i^{(f_1)},...,X_i^{(f_j)})\}
X^i=R{K3D(Xi,Xi(f1),...,Xi(fj))}(1)其中
X
i
,
X
i
(
f
1
)
,
.
.
.
,
X
i
(
f
j
)
X_i,X_i^{(f_1)},...,X_i^{(f_j)}
Xi,Xi(f1),...,Xi(fj) 表示由
H
\boldsymbol H
H 生成的邻居特征,
R
\cal R
R 表示非线性激活函数。
在二维图像空间中编码噪声感知特征
由于噪声主要分布在2D实例边界上,论文将卷积感受野扩展到2D图像空间,并使用2D邻域体素对噪声感知特征进行编码。
首先根据体素化参数将 3D 索引转换(转换表示为
G
(
⋅
)
{\cal G}(\cdot)
G(⋅))为一组网格点。
由于目前最先进的检测器也采用了旋转、缩放等变换增广(记为
T
(
⋅
)
\cal T(\cdot)
T(⋅)),因此网格点通常与对应图像不对齐。因此,我们根据数据增广参数将网格点反向转换为原始坐标系。
然后根据 LiDAR-Camera 的标定参数(投影表示为
P
(
⋅
)
\cal P(\cdot)
P(⋅)),将网格点投影到二维图像面上。
总体投影概括为: H ^ = P ( T − 1 ( G ( H ) ) ) (2) \tag 2 {\boldsymbol {\hat H}} ={\cal P}({\cal T^{-1}}({\cal G}(\boldsymbol H))) H^=P(T−1(G(H)))(2) H ^ ∈ R N × 2 {\boldsymbol {\hat H}} \in \R^{N \times 2} H^∈RN×2 表示 2D 索引向量。对于每个体素特征 X i ∈ R N × 2 X_i \in \R^{N \times 2} Xi∈RN×2, 基于相应的2D索引,从3×3邻域内的非空体素中提取计算噪声感知特征 X i ~ ∈ R C o u t × 2 \tilde{X_i} \in \R^{C^{out} \times 2} Xi~∈RCout×2: X i ~ = R { K 2 D ( X i , X ~ i ( f 1 ) , . . . , X ~ i ( f k ) ) } (3) \tag 3 \tilde{X_i}={\cal R}\{ {\cal K}^{2D} (X_i,\tilde X_i^{(f_1)},...,\tilde X_i^{(f_k)}) \} Xi~=R{K2D(Xi,X~i(f1),...,X~i(fk))}(3) X ~ i ( f 1 ) , . . . , X ~ i ( f k ) \tilde X_i^{(f_1)},...,\tilde X_i^{(f_k)} X~i(f1),...,X~i(fk) 表示 H ^ \boldsymbol {\hat H} H^ 生成的领域体素特征, K 2 D ( ⋅ ) {\cal K}^{2D}(\cdot) K2D(⋅) 表示 2D 子流形卷积核,执行 max-pooling,在每个体素中保留一个特征来执行 2D 卷积。
完成 3D 和 2D 特征编码后,采用一个简单的级联来隐式学习一个抗噪声特征。 将 X i X_i Xi 和 X ~ i \tilde X_i X~i 级联,得到抗噪特征向量 Y ∈ R N × C C o u t \boldsymbol Y \in R^{N \times C^{Cout}} Y∈RN×CCout: Y = [ [ X ^ i , X ~ i ] T , . . . , [ X ^ N , X ~ N ] T ] T (4) \tag 4 \boldsymbol {Y}=\big\lbrack[\hat X_i,\tilde X_i]^T,...,[\hat X_N,\tilde X_N]^T \big \rbrack ^T Y=[[X^i,X~i]T,...,[X^N,X~N]T]T(4)
NRCONV通过将感受野扩展到二维图像空间来隐式区分噪声模式,抑制噪声的影响而不丢失形状线索
VirConv 检测框架
Voxel-RCNN[1] 中构造了Virconv-L、Virconv-T和Virconv-S,分别用于快速、准确和半光滑的三维物体检测。
Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wen gang Zhou, Yanyong Zhang, and Houqiang Li. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, 2021. 2, 4, 5, 6, 7, 8
VirConv-L: 将 LiDAR 点表示为
P
=
p
,
p
=
[
x
,
y
,
z
,
α
]
\boldsymbol P={p},p=[x,y,z,\alpha]
P=p,p=[x,y,z,α],其中
x
,
y
,
z
x,y,z
x,y,z 表示坐标,
α
\alpha
α 表示强度。将虚拟点表示为
V
=
v
,
v
=
[
x
,
y
,
z
]
\boldsymbol V={v},v=[x,y,z]
V=v,v=[x,y,z]。把它们融合成一个点云
P
∗
=
p
∗
,
p
∗
=
[
x
,
y
,
z
,
α
,
β
]
\boldsymbol P^*={p^*},p^*=[x,y,z,\alpha,\beta]
P∗=p∗,p∗=[x,y,z,α,β],
β
\beta
β 是指示点来自哪里的指示器。虚拟点的强度用零填充。 通过VirConvNet将融合点编码成特征体进行 3D 检测。
 VirConv-T: 两个高计算量的检测器融合到一个有效流中。
VirConv-T: 两个高计算量的检测器融合到一个有效流中。
首先用不同的旋转和反射来变换
P
\boldsymbol P
P 和
V
\boldsymbol V
V。 然后采用VoxelNet和VirconvNet分别对
P
\boldsymbol P
P 和
V
\boldsymbol V
V 的特征进行编码。不同变换之间的卷积权值是共享的。 然后,由区域建议网络(RPN)生成ROI,并由第一次变换下的 backbone 特征(简单级联融合的
P
\boldsymbol P
P 和
V
\boldsymbol V
V 的 ROI 特征)进行细化。 改进后的ROI由其他变换下的 backbone 特征进一步改进。 通过激光雷达点和虚拟点共享 boxes 投票对不同细化阶段的ROIs进行融合。 最后对融合后的ROIS进行非最大值抑制(NMS)以获得检测结果。
VirConv-S: 首先,使用标记的训练数据对模型进行预训练。 然后,利用这个预先训练的模型在一个更大规模的无注释数据集上生成伪标签。 采用一个高分阈值(经验上为0.9),过滤掉低质量标签。 最后,使用实标签和伪标签对Virconv-T模型进行训练。
论文总结
提出了一种新的 VirConv 算子,用于基于虚拟点的多模态三维目标检测。 VirConv通过新设计的随机体素丢弃和抗噪声子流形卷积机制解决了虚拟点的密度和噪声问题。 在VirConv 的基础上,我们分别提出了 VirConv-L、VirConv-T 和 VirConv-S 用于高效、准确和半光滑的三维检测。