作为编程世界的传统入门仪式,我们这里也以Hello World来命名我们的第一个项目,其实我们这个项目与Hello World没有半毛钱关系。
在这个程序中,我们使用DepthAI Python API来一步步实现显示OAK相机彩色视频流,并捕捉物体的功能
目录
- 环境要求:
- 创建程序
- Setup 1: 创建文件
- Setup 2: 安装依赖
- Setup 3: 导入需要的包
- Setup 4: 定义 pipeline
- Setup 5:添加ColorCamera节点
- Setup 6:定义移动网络检测网络节点
- Setup 7:将彩色相机预览输出连接到神经网络输入
- Setup 8:创建XLinkOut节点
- Setup 9:初始化DepthAI 设备
- Setup 10:添加辅助对象
- Setup 11:定义两个变量,用于存储数据
- Setup 12:定义辅助函数frameNorm
- Setup 13:开始主程序循环
- 定义变量从队列获取数据
- 从rgb相机接收帧
- 接收神经网络的结果
- 显示结果
- 终止程序
- Setup 14:运行程序
环境要求:
- Python >=3.6
- DepthAI Python API
cv2,blobconverter和numpyPython模块
创建程序
Setup 1: 创建文件
- 创建一个文件夹,新建1-hello-world文件夹
- 用vscode打开该文件夹
- 新建一个hello_world.py 文件
Setup 2: 安装依赖
安装依赖前需要先创建和激活虚拟环境,我这里已经创建了虚拟环境OAKenv,在终端中输入cd…退回到OAKenv的根目录,输入 OAKenv\Scripts\activate激活虚拟环境
安装pip依赖项:
pip install numpy opencv-python depthai blobconverter --user
使用pip命令安装四个Python包:numpy、opencv-python、depthai和blobconverter。这些包的安装是针对当前用户进行的,并且使用了--user参数,表示将这些包安装到当前用户的本地环境中,而不是系统环境。
这四个包的作用如下:
- numpy:是用于进行科学计算和数值操作的Python库。它提供了高性能的多维数组对象和用于处理这些数组的函数。
- opencv-python:是OpenCV(开放源代码计算机视觉库)的Python接口。它提供了丰富的图像处理和计算机视觉功能,如图像读取、处理、分析、特征提取等。
- depthai:是一个用于深度学习和计算机视觉的库,特别用于使用DepthAI硬件加速器进行推理。DepthAI是一个结合了AI摄像头和嵌入式神经网络加速器的技术,可以提供实时的深度感知和智能分析功能。
- blobconverter:是一个用于转换深度学习模型的工具,用于将模型转换为可以在目标设备上运行的二进制格式。它能够将不同框架(如TensorFlow、PyTorch等)训练的模型转换为便于在特定设备上进行推理的格式。
Setup 3: 导入需要的包
导入项目需要的包
import numpy as np #numpy - 处理depthai返回的数据包数据
import cv2 # opencv -显示视频流
import depthai # depthai - 调用depthai 访问相机及其数据包进行图像采集
import blobconverter # blobconverter - 编译并下载MyriadX神经网络Blob
Setup 4: 定义 pipeline
DepthAI的任何动作,无论是神经推理还是彩色相机输出,都需要定义一个管道,包括与我们的需求相对应的节点和连接。
在这里,我们希望看到彩色相机的帧,以及在它们上面运行的简单神经网络。
创建一个空的pipeline对象
# 创建一个空的pipeline对象
pipeline = depthai.Pipeline()
Setup 5:添加ColorCamera节点
现在,我们将添加的第一个节点是ColorCamera。
cam_rgb = pipeline.create(depthai.node.ColorCamera)
cam_rgb.setPreviewSize(300,300)
cam_rgb.setInterleaved(False)
上面这段代码创建一个名为cam_rgb的ColorCamera节点,并设置预览的尺寸为300x300像素,并将图像的存储格式设置为非交错格式。
-
pipeline.create(depthai.node.ColorCamera):使用depthai.node.ColorCamera创建一个ColorCamera节点,作为图像采集的源。pipeline是一个DepthAI的流水线(pipeline)对象。 -
cam_rgb.setPreviewSize(300, 300):设置cam_rgb节点的预览大小为300x300像素。这意味着从相机采集的图像会被调整为300x300大小以进行显示或进一步处理。 -
cam_rgb.setInterleaved(False):将图像的存储格式设置为非交错(non-interleaved)格式。交错格式指的是图像数据存储时将不同颜色通道的像素交错排列,而非交错格式则将每个颜色通道的像素按顺序存储。
这段代码的目的是配置cam_rgb节点,以便从相机采集RGB图像,并在后续处理中使用。
Setup 6:定义移动网络检测网络节点
接下来,定义一个具有mobilenetssd网络的MobileNetDetectionNetwork节点。此示例的blob文件将使用blobconverter工具自动编译和下载。blobconverter.from_zoo()函数返回模型的Path,因此我们可以直接将其放入detection_nn.setBlobPath()函数中。有了这个节点,nn的输出将在设备端进行解析,我们将收到一个现成的检测对象。为了使其正常工作,我们还需要设置置信阈值来过滤不正确的结果
detection_nn = pipeline.create(depthai.node.MobileNetDetectionNetwork)
# Set path of the blob (NN model). We will use blobconverter to convert&download the model
# detection_nn.setBlobPath("/path/to/model.blob")
detection_nn.setBlobPath(blobconverter.from_zoo(name='mobilenet-ssd', shaves=6))
detection_nn.setConfidenceThreshold(0.5)
上面这段代码创建一个名为detection_nn的MobileNetDetectionNetwork节点,并配置它用于目标检测的设置。
pipeline.create(depthai.node.MobileNetDetectionNetwork):使用depthai.node.MobileNetDetectionNetwork创建一个MobileNetDetectionNetwork节点,用于目标检测。detection_nn.setBlobPath(blobconverter.from_zoo(name='mobilenet-ssd', shaves=6)):设置模型文件路径。这里使用了blobconverter.from_zoo()函数来从预训练模型库中下载并转换模型。name='mobilenet-ssd'表示选择了MobileNet-SSD模型,shaves=6表示选择了使用6个shave核心进行模型推理。detection_nn.setConfidenceThreshold(0.5):设置目标检测的置信度阈值为0.5。这意味着只有置信度大于0.5的目标才会被认为是有效的。
这段代码的目的是配置detection_nn节点,使其使用MobileNet-SSD目标检测模型,并设置置信度阈值为0.5。在后续的流水线运行中,该节点将使用模型对从相机采集的图像进行目标检测。
Setup 7:将彩色相机预览输出连接到神经网络输入
cam_rgb.preview.link(detection_nn.input)
这行代码将cam_rgb节点的预览输出链接到detection_nn节点的输入。
cam_rgb.preview表示cam_rgb节点的预览输出端口,通过这个端口可以获取到从相机采集的图像预览数据。.link(detection_nn.input)表示将cam_rgb.preview与detection_nn节点的输入端口进行链接,将图像数据传递给detection_nn节点进行目标检测。
这行代码的目的是建立数据流通路,将从相机采集的图像预览数据传递给detection_nn节点进行目标检测,并在后续流水线运行中触发节点的处理。
Setup 8:创建XLinkOut节点
现在,我们需要接收彩色相机帧和神经网络推理结果——因为这些结果是在设备上产生的,所以需要将它们传输到我们的机器(主机,这里是我的计算机)。设备和主机之间的通信由XLink处理,在这里,由于我们希望从设备到主机接收数据,我们将使用XLinkOut节点
xout_rgb = pipeline.create(depthai.node.XLinkOut)
xout_rgb.setStreamName("rgb")
cam_rgb.preview.link(xout_rgb.input)
xout_nn = pipeline.create(depthai.node.XLinkOut)
xout_nn.setStreamName("nn")
detection_nn.out.link(xout_nn.input)
这段代码创建了两个XLinkOut节点,并将节点连接到相应的输入和输出。
-
xout_rgb = pipeline.create(depthai.node.XLinkOut):创建一个XLinkOut节点,命名为xout_rgb,用于输出相机采集的图像数据。 -
xout_rgb.setStreamName("rgb"):设置xout_rgb节点的输出流名称为"rgb"。 -
cam_rgb.preview.link(xout_rgb.input):将cam_rgb节点的预览输出链接到xout_rgb节点的输入,以实现将图像数据传递给xout_rgb节点进行输出。 -
xout_nn = pipeline.create(depthai.node.XLinkOut):创建另一个XLinkOut节点,命名为xout_nn,用于输出目标检测的结果数据。 -
xout_nn.setStreamName("nn"):设置xout_nn节点的输出流名称为"nn"。 -
detection_nn.out.link(xout_nn.input):将detection_nn节点的输出链接到xout_nn节点的输入,以实现将目标检测结果数据传递给xout_nn节点进行输出。
这段代码的目的是创建两个XLinkOut节点,其中一个用于输出相机采集的图像数据,另一个用于输出目标检测的结果数据。通过链接节点之间的输入和输出,可以将数据流传递给对应的节点,并在流水线运行中实时输出结果。
Setup 9:初始化DepthAI 设备
定义了管道后,我们现在可以用管道初始化设备并启动它
with depthai.Device(pipeline) as device:
这里需要注意:默认情况下,DepthAI作为USB3设备访问。如果你想通过USB2进行通信,可以使用以下代码初始化DepthAI
device = depthai.Device(pipeline, usb2Mode=True)
从这里开始,管道将在设备上运行,产生我们要求的结果。让我们能够捕获它们
Setup 10:添加辅助对象
由于XLinkOut节点已经在管道中定义,我们现在将定义一个主机端输出队列来访问生成的结果
q_rgb = device.getOutputQueue("rgb")
q_nn = device.getOutputQueue("nn")
这段代码从设备中获取两个输出队列,分别对应图像数据和目标检测结果数据。
-
q_rgb = device.getOutputQueue("rgb"):从设备中获取名为"rgb"的输出队列,用于接收相机采集的图像数据。这样,通过获取输出队列,可以从设备中获取实际的图像数据。 -
q_nn = device.getOutputQueue("nn"):从设备中获取名为"nn"的输出队列,用于接收目标检测的结果数据。这样,通过获取输出队列,可以从设备中获取实际的目标检测结果数据。
通过获取输出队列,可以在Pipeline运行期间实时获取图像数据和目标检测结果数据,以便进行进一步的处理和使用。
Setup 11:定义两个变量,用于存储数据
frame = None
detections = []
初始化了两个变量:
frame = None:frame是一个用于存储图像帧数据的变量,初始值为None。这个变量可以被赋予实际的图像数据,用于后续的处理或显示。detections = []:detections是一个空列表,用于存储目标检测结果。目标检测算法的输出结果通常是一组检测到的目标的框的坐标、类别标签和置信度等信息。这个空列表可以用于存储这些检测结果,以供后续使用。
Setup 12:定义辅助函数frameNorm
将边界框坐标从归一化的范围转换为实际的像素位置
由于神经网络的实现细节,推理结果中的边界框坐标表示为介于0和1之间的浮点数范围内 - 相对于帧的宽度/高度(例如,如果图像的宽度为200像素,并且神经网络nn返回的x_min坐标等于0.2,则意味着实际(归一化)的x_min坐标为40像素)。
所以需要定义一个辅助函数frameNorm,它将把这些在<0…1>范围的值转换为实际的像素位置。
def frame_norm(frame,bbox):
normVals = np.full(len(bbox),frame.shape[0])
normVals[::2] = frame.shape[1]
return (np.clip(np.array(bbox),0,1)*normVals).astype(int)
这段代码定义了一个名为frameNorm的函数,它接受两个参数:frame和bbox。它的作用是将边界框坐标从归一化的范围转换为实际的像素位置。
首先,函数创建了一个具有与bbox长度相同的数组normVals,其初始值为帧的高度(frame.shape[0])。数组中的偶数索引位置对应边界框的宽度值,奇数索引位置对应边界框的高度值。
接下来,通过将normVals[::2]值设置为frame.shape[1],将宽度值设置为frame的宽度。
然后,将bbox数组剪裁到范围[0, 1]之间,并将其乘以normVals数组,以将归一化的坐标值缩放到实际的像素位置。最后,使用astype将结果转换为整数类型。
最终,函数返回转换后的bbox,即实际的像素位置坐标。
Setup 13:开始主程序循环
准备好上面的一切后,我们就可以开始主程序循环了
while True:
定义变量从队列获取数据
在这个循环中,首先要做的是从nn节点和彩色相机获取最新结果
in_rgb = q_rgb.tryGet()
in_nn = q_nn.tryGet()
这段代码中,in_rgb = q_rgb.tryGet()和in_nn = q_nn.tryGet()是从队列q_rgb和q_nn中尝试获取数据。
q_rgb.tryGet()将尝试从q_rgb队列中获取数据,并将获取到的数据赋值给in_rgb变量。如果队列中没有可用的数据,它将返回None。
同样地,q_nn.tryGet()将尝试从q_nn队列中获取数据,并将获取到的数据赋值给in_nn变量。如果队列中没有可用的数据,它也将返回None。
无论是来自rgb相机还是神经网络nn,都将以1D阵列的形式提供,因此它们都需要转换才能用于显示(我们已经定义了所需的转换之一-frameNorm函数)
从rgb相机接收帧
首先,从rgb相机接收帧,我们使用getCvFrame命令
if in_rgb is not None:
frame = in_rgb.getCvFrame()
在上面的代码中,我们首先检查in_rgb是否为空。如果不为空,我们通过getCvFrame()方法获取从RGB相机传输过来的一帧图像,并将其赋值给变量frame。这样我们就可以使用frame变量在后续进行图像处理或显示。
接收神经网络的结果
其次,我们接收神经网络的结果。默认MobileNetSSD结果有7个字段,每个字段分别为image_id、label、confidence、x_min、y_min、x_max、y_max,通过访问检测阵列,我们接收到允许我们访问这些字段的检测对象
if in_nn is not None:
detections = in_nn.detections
在上面的代码中,我们首先检查in_nn是否为空。如果不为空,我们获取in_nn中的检测结果,并将其赋值给变量detections。这些检测结果可能包括物体类别、位置、置信度等信息,可以用于后续的应用或显示。
in_nn.detections代表从神经网络模型in_nn中获取的检测结果。这个结果可能是一个列表、数组或其他数据结构,包含了在输入图像中检测到的物体的信息。
具体的结构和内容取决于所使用的神经网络模型和应用场景。通常,每个检测结果可能包含物体类别、边界框位置、置信度等信息。可以根据具体情况对这些信息进行解析和处理,以满足特定的需求。
显示结果
到目前为止,我们已经从DepthAI设备获取了所有的结果,唯一剩下的就是将它们实际显示出来。
if frame is not None:
for detection in detections:
bbox = frame_norm(frame,(detection.xmin,detection.ymin,detection.xmax,detection.ymax))
cv2.rectangle(frame,(bbox[0],bbox[1]),(bbox[2],bbox[3]),(255,0,0),2)
cv2.imshow("preview",frame)
上述代码判断frame是否存在,如果存在帧(frame is not None),则使用OpenCV库将检测结果显示在图像上。对于每个检测结果,可以使用检测框的坐标信息(detection.xmin,detection.ymin,detection.xmax,detection.ymax)将矩形框绘制在帧上。然后,使用cv2.rectangle函数绘制矩形框,并设置颜色为(255, 0, 0)、线条宽度为2。最后,使用cv2.imshow函数显示帧并命名为"preview"。
在这里可以看到我们之前定义的frame_norm函数用于归一化边界框坐标的用法。我们使用cv2.rectangle在RGB帧上绘制一个矩形框,作为物体的指示器,然后使用cv2.imshow显示帧。
终止程序
使用cv2.waitKey方法来终止程序,它等待用户按下一个键——在这里,我们希望在用户按下q键时跳出循环
if cv2.waitKey(1) == ord('q'):
break
Setup 14:运行程序
在终端中输入如下指令运行程序
python hello_world.py

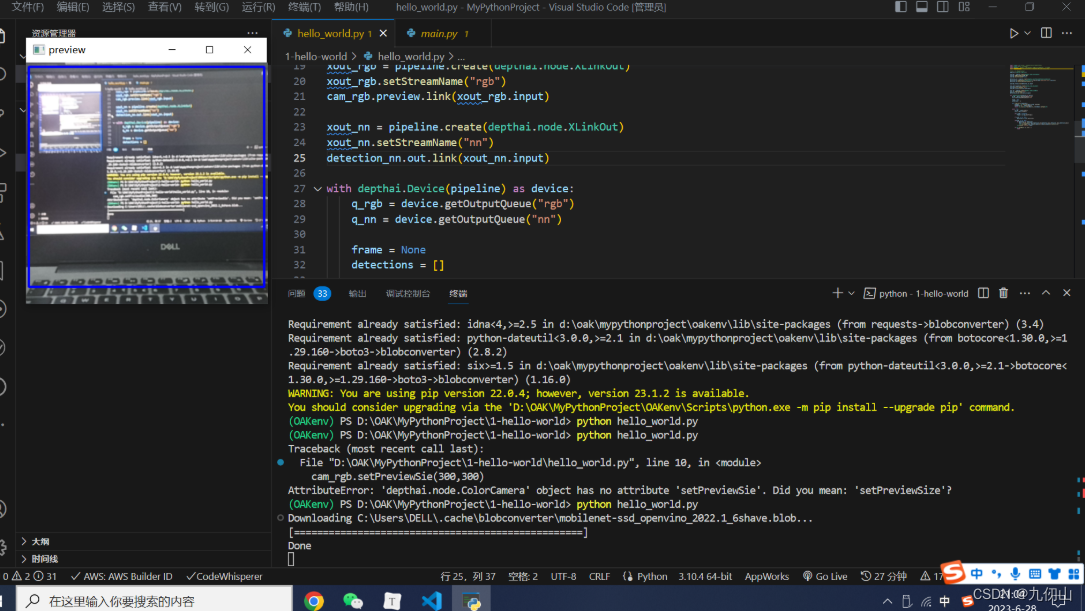
到这里,我们的第一个OAK程序已经成功运行了。


![[数据分析与可视化] 基于matplotlib-scalebar库绘制比例尺](https://img-blog.csdnimg.cn/img_convert/e881b13a2a8148725a86e93c10834dbc.png)