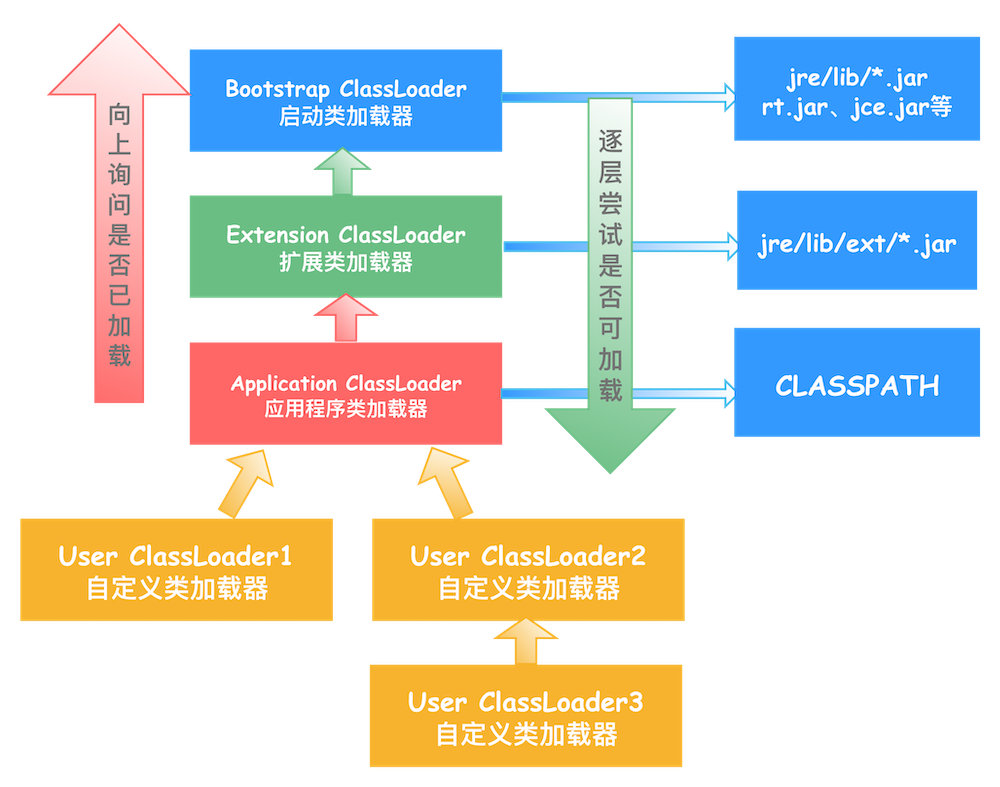
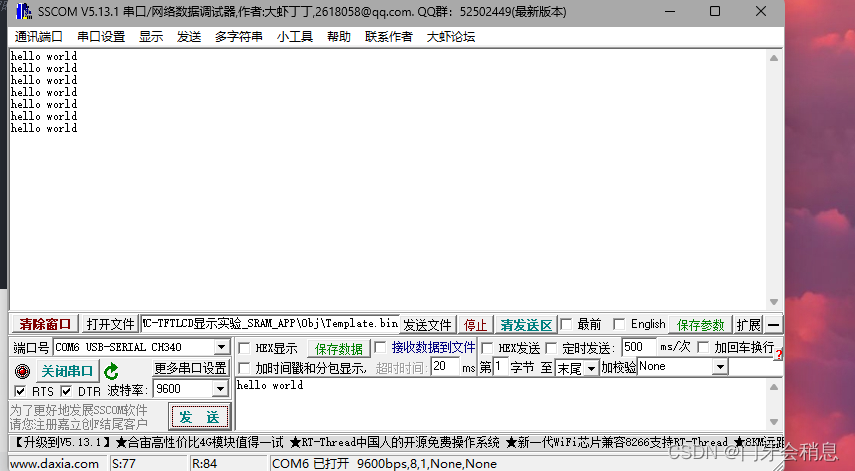
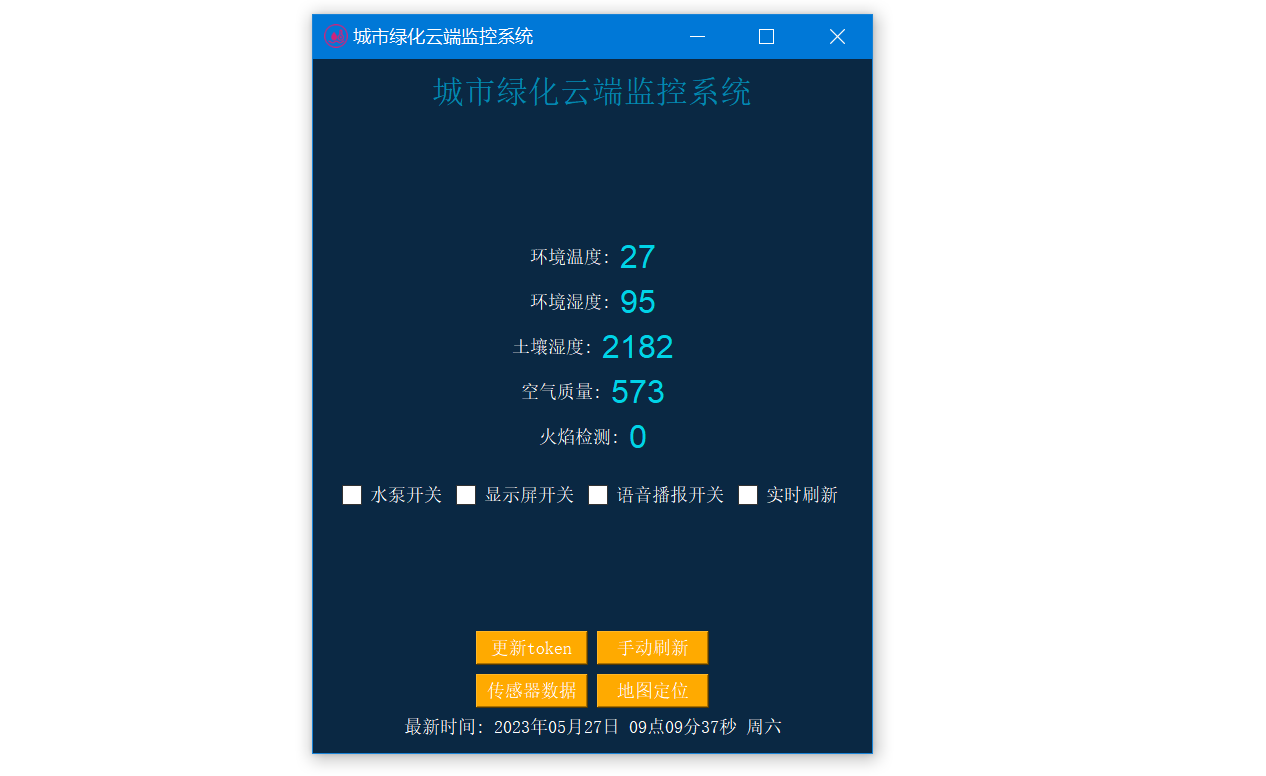
这是一个演示
GitHub地址:https://github.com/jumppppp/go/tree/master/htools/jsfu0k
输出窗口
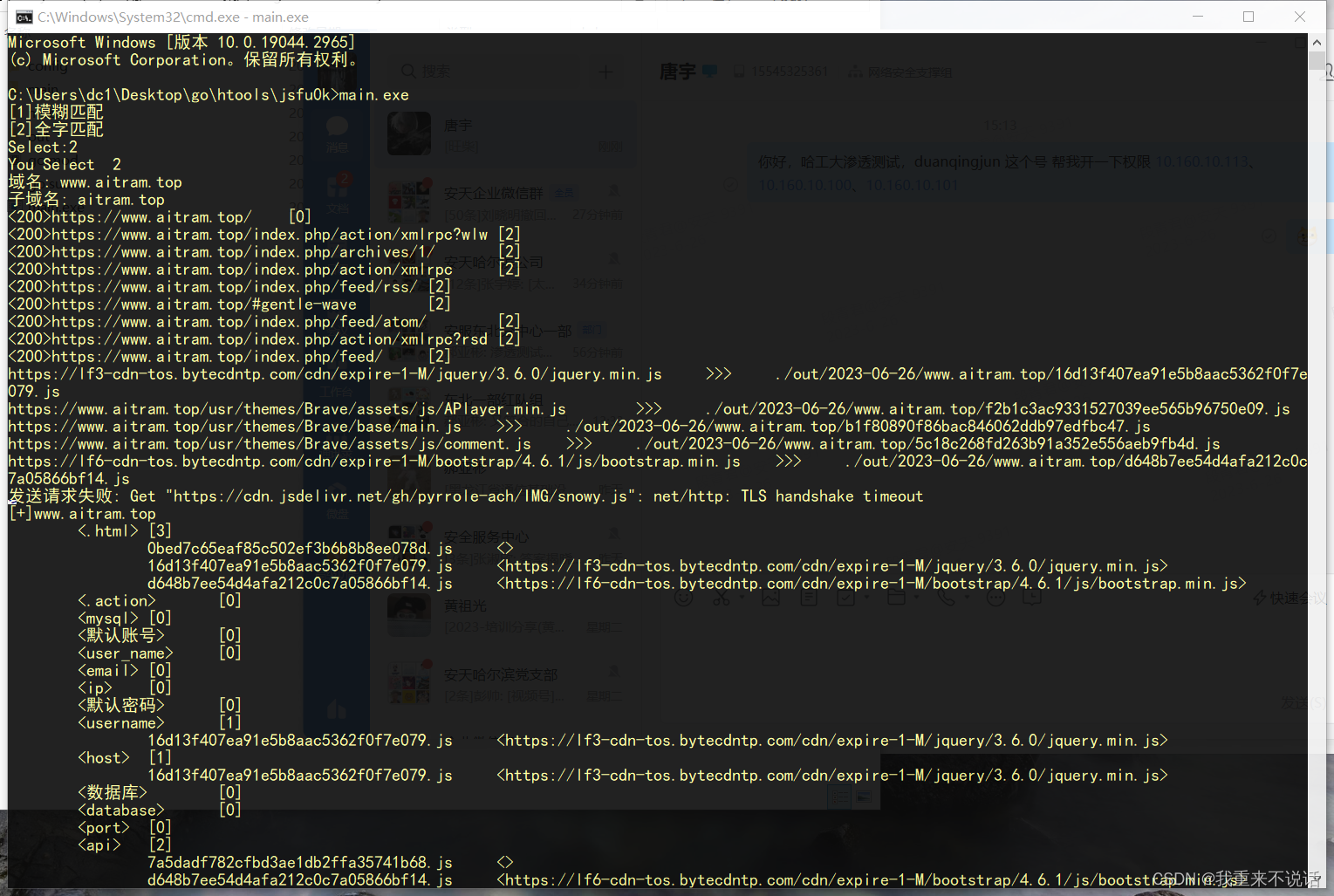
输出的详细文件

以上演示的是全字匹配
这个自动化工具模仿人工在一个网页内进行寻找js中敏感信息
流程:
填写配置(输入批量域名) -》
选择模式 -》
爬取网站内连接 -》
判断后缀 -》
本域名下不同网页继续爬取(爬取深度自定义) -》
整体js链接 -》
保存到本地 -》
根据关键字进行搜索 -》
整理到输出和文档内
main.go
package main
import (
"bufio"
"fmt"
"io"
"jsfu0k/model"
"net/url"
"os"
"strings"
"time"
)
func main() {
fmt.Printf("[1]模糊匹配\n[2]全字匹配\nSelect:")
var keyy int
_,err :=fmt.Scanf("%d\n",&keyy)
if err != nil {
fmt.Println("No=", err)
}
if keyy!=1||keyy!=2{
keyy = 2
}
fmt.Println("You Select ",keyy)
// 读取URL文件
urls, err := readURLsFromFile("./config/urls.txt")
if err != nil {
fmt.Println("读取URL文件失败:", err)
}
// 获取当前日期作为数据库名称
currentDate := time.Now().Format("2006-01-02")
err = os.Mkdir("./out/"+currentDate, 0755)
if err != nil {
// fmt.Println("No=", err)
}
Ua:=&model.ReqTool_t{}
Ua.UA,err = readUAsFromFile("./config/UA.txt")
if err != nil {
fmt.Println("读取UA文件失败:", err)
}
Keys,err:= readKeysFromFile("./config/Key.txt")
if err != nil {
fmt.Println("读取Key文件失败:", err)
}
// 创建表格
for _, u := range urls {
domain,Cdomain := DomainGet(u)
DirPath:="./out/"+currentDate+"/"+domain
err = os.Mkdir(DirPath, 0755)
if err != nil {
// fmt.Println("No=", err)
}
Ua.DirPath = DirPath
Ua.MaxR = 2
Ua.Domain = domain
Ua.Cdomain = Cdomain
Ua.AllUrls = make(map[string]bool)
Ua.JsUrls = make(map[string]string)
Ua.GoUrls = make(map[string]bool)
Ua.KeyOut = make(map[string]map[string][]string)
Ua.KeyOut[domain]= make(map[string][]string)
for _,key:=range Keys{
Ua.KeyOut[domain][key]= []string{}
}
Ua.CrawlURL(u,0)
Ua.Wg.Wait()
Ua.JS_Init()
Ua.GetJsKey(keyy)
Ua.ShowInfo()
}
fmt.Println("数据库和表格创建成功",urls)
}
// 从文件中读取URL列表
func readURLsFromFile(filename string) ([]string, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
var urls []string
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil && err != io.EOF {
return nil, err
}
line = strings.TrimSpace(line)
if line != "" {
urls = append(urls, line)
}
if err == io.EOF {
break
}
}
return urls, nil
}
// 从文件中读取UA列表
func readUAsFromFile(filename string) ([]string, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
var UAs []string
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil && err != io.EOF {
return nil, err
}
line = strings.TrimSpace(line)
if line != "" {
UAs = append(UAs, line)
}
if err == io.EOF {
break
}
}
return UAs, nil
}
// 从文件中读取Key列表
func readKeysFromFile(filename string) ([]string, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
var Keys []string
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil && err != io.EOF {
return nil, err
}
line = strings.TrimSpace(line)
if line != "" {
Keys = append(Keys, line)
}
if err == io.EOF {
break
}
}
return Keys, nil
}
func DomainGet(u string)(domain string,Cdomain string){
// 解析域名
parsedURL, err := url.Parse(u)
if err != nil {
fmt.Println("解析域名失败:", err)
return
}
// 获取主机名
hostname := parsedURL.Hostname()
// 分割主机名
parts := strings.Split(hostname, ".")
// 分解子域名和顶级域名
Cdomain = strings.Join(parts[len(parts)-2:], ".")
domain = strings.Join(parts[:len(parts)-2], ".")+"."+Cdomain
// 输出结果
fmt.Println("域名:", domain)
fmt.Println("子域名:", Cdomain)
return
}
req.go
package model
import (
"crypto/md5"
"fmt"
"io"
"io/ioutil"
"math/rand"
"net/http"
"net/url"
"os"
"path/filepath"
"regexp"
"strings"
"sync"
"time"
)
type ReqTool_t struct{
UA []string
Domain string
Cdomain string
DirPath string
JsUrls map[string]string //url >> name
AllUrls map[string]bool
GoUrls map[string]bool
MaxR int
KeyOut map[string]map[string][]string // domain >> key >>{path1,path2}
mutex sync.Mutex
Wg sync.WaitGroup
}
// 提取链接的正则表达式
var linkRegex = regexp.MustCompile(`(?i)(?:href|src)=["']([^"']+)["']`)
func (this * ReqTool_t)CrawlURL(url string,MaxR int) {
if MaxR > this.MaxR {
return
}
// 加锁
this.mutex.Lock()
defer this.mutex.Unlock()
// 检查是否已经访问过该链接
if this.GoUrls[url] {
return
}
// 标记该链接已访问
this.GoUrls[url] = true
// 创建一个 HTTP 客户端
client := &http.Client{}
// 创建一个 HTTP 请求
req, err := http.NewRequest("GET", url, nil)
if err != nil {
fmt.Println("创建请求失败:", err)
return
}
// 设置随机数种子
rand.Seed(time.Now().UnixNano())
rUA := rand.Intn(len(this.UA))
// 设置 User-Agent 头
req.Header.Set("User-Agent", this.UA[rUA])
rSleep := rand.Intn(5)+1
delay := time.Duration(rSleep) * time.Second
// 发送请求前进行延迟
time.Sleep(delay)
// 发送 HTTP 请求
resp, err := client.Do(req)
if err != nil {
fmt.Println("发送请求失败:", err)
return
}
defer resp.Body.Close()
// 读取响应内容
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("读取响应内容失败:", err)
return
}
// 获取响应状态码
statusCode := resp.StatusCode
fmt.Printf("<%d>%s\t[%d]\n", statusCode,url,MaxR)
if statusCode == 200{
MaxR +=1
bodyString := string(body)
// 使用正则表达式提取链接
linksMap:= extractUniqueLinks(bodyString, resp.Request.URL)
// 启动子协程前增加等待计数
for key, value := range linksMap {
this.AllUrls[key] = value
}
// 输出链接
for key,_ := range linksMap {
if key!=url{
isGoflag := this.isGo(key)
if isGoflag{
this.Wg.Add(1)
go func(url string) {
// 在子协程执行完毕后减少等待计数
defer this.Wg.Done()
// 递归调用CrawlURL
this.CrawlURL(url, MaxR+1)
}(key)
} else if strings.Contains(key, ".js") {
this.JsUrls[key] = ""
}
}
}
}
}
func (this * ReqTool_t)JS_Init(){
// 创建一个 HTTP 客户端
client := &http.Client{}
// 创建一个 HTTP 请求
for key,value:=range this.JsUrls{
value = MD5(key)
this.JsUrls[key]=value
req, err := http.NewRequest("GET", key, nil)
if err != nil {
fmt.Println("创建请求失败:", err)
return
}
rSleep := rand.Intn(5)+1
delay := time.Duration(rSleep) * time.Second
// 发送请求前进行延迟
time.Sleep(delay)
// 发送 HTTP 请求
resp, err := client.Do(req)
if err != nil {
fmt.Println("发送请求失败:", err)
return
}
// 读取响应内容
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("读取响应内容失败:", err)
return
}
resp.Body.Close()
name:=this.DirPath+"/"+value+".js"
var NewBody string
NewBody = fmt.Sprintf("\n\t\t[%s]\t\t\n\t\t<%s>\t\t\n\n",key,name)+string(body)
err = ioutil.WriteFile(name, []byte(NewBody), 0644)
if err != nil {
fmt.Println("写入文件失败:", err)
return
}
fmt.Printf("%s\t>>>\t%s\n",key,name)
}
}
func MD5(str string) string {
h := md5.New()
io.WriteString(h, str)
return fmt.Sprintf("%x", h.Sum(nil))
}
func (this * ReqTool_t)ShowInfo(){
for domain,keys := range this.KeyOut{
fmt.Printf("[+]%s\n",domain)
for key,values := range keys{
fmt.Printf("\t<%s>\t[%d]\n",key,len(values))
for _,v:=range values{
path:=this.findJSurl(v)
fmt.Printf("\t\t%s\t<%s>\n",v,path)
}
}
}
}
func (this * ReqTool_t)findJSurl(name string)(string){
for url,value:= range this.JsUrls{
if value+".js" == name{
return url
}
}
return ""
}
func (this * ReqTool_t)GetJsKey(Mod int){
filey, err := os.OpenFile("./out/res.txt", os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
fmt.Println("打开文件失败:", err)
return
}
defer filey.Close()
_, err = filey.WriteString(fmt.Sprintf("\n\t\t====%s====\t\t\n\n",this.Domain))
if err != nil {
fmt.Println("写入文件失败:", err)
return
}
for key,_ := range this.KeyOut[this.Domain]{
files, err := ioutil.ReadDir(this.DirPath)
if err != nil {
fmt.Println("No=",err)
}
// 遍历并打印文件名
for _, file := range files {
if !file.IsDir() {
content, err := ioutil.ReadFile(filepath.Join(this.DirPath, file.Name()))
if err != nil {
fmt.Printf("Failed to read file: %s\n", file.Name())
continue
}
// fmt.Printf("File: %s\n", file.Name())
// fmt.Printf("Content: %s\n", content)
var OutList []string
switch Mod {
case 1:
OutList = SelectKey(key,string(content))
case 2:
OutList = FullSelectKey(key,string(content))
default:
}
if len(OutList) != 0{
this.KeyOut[this.Domain][key] = append(this.KeyOut[this.Domain][key],file.Name())
for _,info:=range OutList{
text1 := fmt.Sprintf("<%s>\t~%s~\t[%s]\n",key,info,this.DirPath+"/"+file.Name())
_, err = filey.WriteString(text1)
if err != nil {
fmt.Println("写入文件失败:", err)
return
}
}
}
}
}
}
}
func SelectKey(key string,content string)(outList []string){
lowerStr := strings.ToLower(content)
search := strings.ToLower(key)
start := 0
for {
pos := strings.Index(lowerStr[start:], search)
if pos == -1 {
break
}
pos += start
subStart := max(0, pos-20)
subEnd := min(len(content), pos+20+len(search))
start = pos + len(search)
outList = append(outList,content[subStart:subEnd])
}
return
}
func FullSelectKey(key string,content string)(outList []string){
// 创建一个正则表达式来进行全词匹配
re := regexp.MustCompile(`\b` + regexp.QuoteMeta(key) + `\b`)
// 将句子和搜索词都转换为小写进行不区分大小写的搜索
lowerStr := strings.ToLower(content)
// 找到所有的匹配项
matches := re.FindAllStringIndex(lowerStr, -1)
// 遍历每一个匹配项并输出它们
for _, match := range matches {
subStart := max(0, match[0]-20)
subEnd := min(len(content), match[1]+20)
outList = append(outList,content[subStart:subEnd])
}
return
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
// 提取并去重链接函数
func extractUniqueLinks(text string, baseURL *url.URL) map[string]bool {
matches := linkRegex.FindAllStringSubmatch(text, -1)
linksMap := make(map[string]bool)
for _, match := range matches {
absURL, err := joinURL(baseURL, match[1])
if err != nil {
// fmt.Println("拼接URL失败:", err,baseURL,match[1])
continue
}
if strings.HasPrefix(absURL, "http://") || strings.HasPrefix(absURL, "https://"){
linksMap[absURL] = true
}
}
return linksMap
}
// 拼接URL函数
func joinURL(baseURL *url.URL, link string) (string, error) {
linkURL, err := url.PathUnescape(link)
if err != nil {
return "", err
}
parsedLinkURL, err := url.Parse(linkURL)
if err != nil {
return "", err
}
absURL := baseURL.ResolveReference(parsedLinkURL).String()
return absURL, nil
}
// 检查链接是否符合子域名规则
func (this * ReqTool_t)isGo(url string) bool {
a1 := strings.Contains(url, this.Domain)
a0 := []string {".gif",".png",".jpg",".js",".ico",".css",".jepg",".swf"}
a2 := true
for _,Ni:=range a0{
if strings.Contains(url,Ni){
a2 = false
}
}
if a2 && a1{
return true
}else{
return false
}
}
本项目还在开发过程中,正在探测可能存在的bug,如有问题可以联系我