原论文:Adaptive Context Selection for Polyp Segmentation
源码:https://github.com/ReaFly/ACSNet.
直接步入正题~~~
一、基础模块
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class DecoderBlock(nn.Module):
def __init__(self, in_channels, out_channels,
kernel_size=3, stride=1, padding=1):
super(DecoderBlock, self).__init__()
self.conv1 = ConvBlock(in_channels, in_channels // 4, kernel_size=kernel_size,
stride=stride, padding=padding)
self.conv2 = ConvBlock(in_channels // 4, out_channels, kernel_size=kernel_size,
stride=stride, padding=padding)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear')
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.upsample(x)
return x
class SideoutBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super(SideoutBlock, self).__init__()
self.conv1 = ConvBlock(in_channels, in_channels // 4, kernel_size=kernel_size,
stride=stride, padding=padding)
self.dropout = nn.Dropout2d(0.1)
self.conv2 = nn.Conv2d(in_channels // 4, out_channels, 1)
def forward(self, x):
x = self.conv1(x)
x = self.dropout(x)
x = self.conv2(x)
return x二、LCA模块
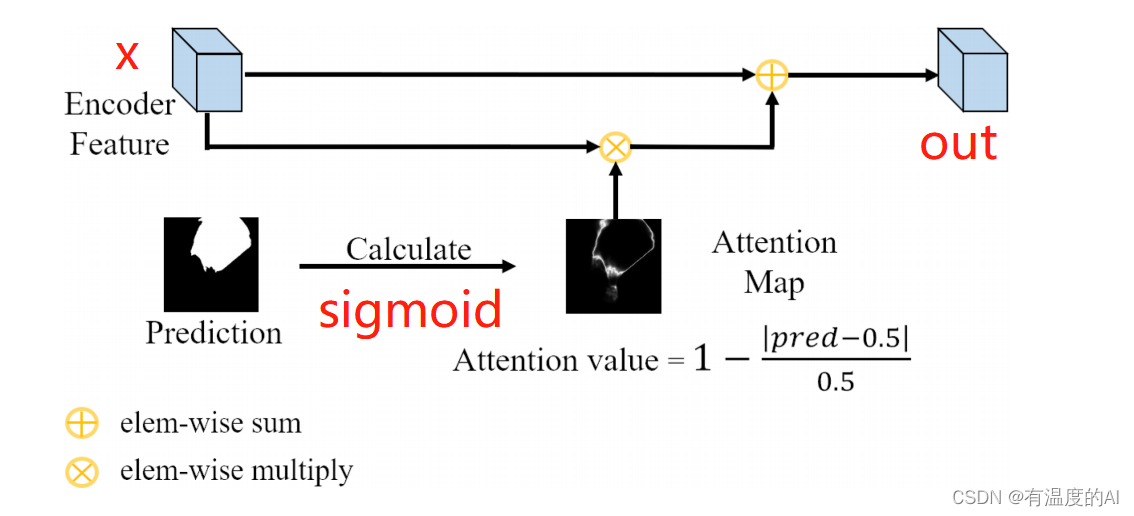
class LCA(nn.Module):
def __init__(self):
super(LCA, self).__init__()
def forward(self, x, pred): #x:256,16,16 pre:1,16,16
residual = x
score = torch.sigmoid(pred)
dist = torch.abs(score - 0.5)
att = 1 - (dist / 0.5)
att_x = x * att #256,16,16
out = att_x + residual #256,16,16
return out三、GCM模块
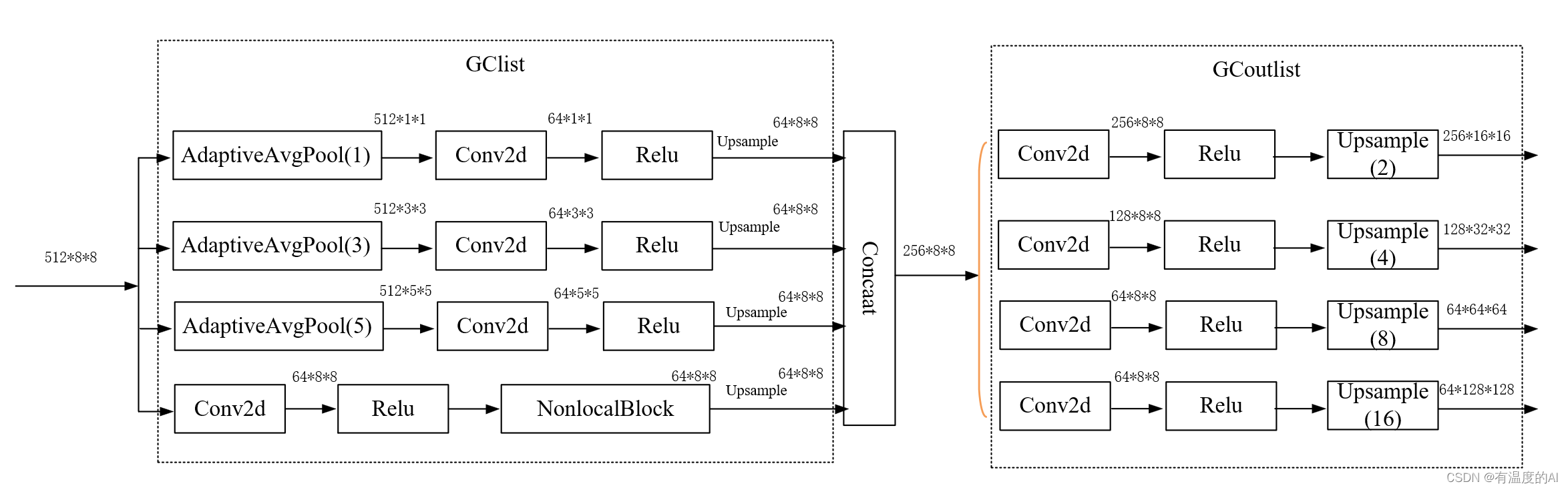
class GCM(nn.Module):
def __init__(self, in_channels, out_channels): #in_channels=512, out_channels=64
super(GCM, self).__init__()
pool_size = [1, 3, 5]
out_channel_list = [256, 128, 64, 64]
upsampe_scale = [2, 4, 8, 16]
GClist = []
GCoutlist = []
for ps in pool_size:
GClist.append(nn.Sequential(
nn.AdaptiveAvgPool2d(ps),
nn.Conv2d(in_channels, out_channels, 1, 1),
nn.ReLU(inplace=True)))
GClist.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, 1),
nn.ReLU(inplace=True),
NonLocalBlock(out_channels)))
self.GCmodule = nn.ModuleList(GClist)
for i in range(4):
GCoutlist.append(nn.Sequential(nn.Conv2d(out_channels * 4, out_channel_list[i], 3, 1, 1),
nn.ReLU(inplace=True),
nn.Upsample(scale_factor=upsampe_scale[i], mode='bilinear')))
self.GCoutmodel = nn.ModuleList(GCoutlist)
def forward(self, x): # 输入x: 512,8,8
xsize = x.size()[2:]
global_context = []
for i in range(len(self.GCmodule) - 1): #range(3)
global_context.append(F.interpolate(self.GCmodule[i](x), xsize, mode='bilinear', align_corners=True))
global_context.append(self.GCmodule[-1](x))
global_context = torch.cat(global_context, dim=1)
output = []
for i in range(len(self.GCoutmodel)): #range(4)
output.append(self.GCoutmodel[i](global_context))
return output四、NonLocalBlock模块
class NonLocalBlock(nn.Module):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True): #in_channels=64
super(NonLocalBlock, self).__init__()
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
self.g = nn.Conv2d(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
nn.Conv2d(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(self.in_channels)
)
# nn.init.constant_(tensor, val):基于输入参数(val)初始化输入张量tensor,即tensor的值均初始化为val。
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = nn.Conv2d(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = nn.Conv2d(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = nn.Conv2d(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, nn.MaxPool2d(kernel_size=(2, 2)))
self.phi = nn.Sequential(self.phi, nn.MaxPool2d(kernel_size=(2, 2)))
def forward(self, x): #bs,64,8,8
batch_size = x.size(0)
# bs,64,8,8->bs,32,4,4->bs,32,16
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1) #bs,16,32
# bs,64,8,8->bs,32,8,8->bs,32,64
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1) #bs,64,32
# bs,64,8,8->bs,32,4,4->bs,32,16
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x) #bs,64,16
f_div_C = F.softmax(f, dim=-1) #bs,64,16
y = torch.matmul(f_div_C, g_x) #bs,64,32
y = y.permute(0, 2, 1).contiguous() #bs,32,64
y = y.view(batch_size, self.inter_channels, *x.size()[2:]) #bs,32,8,8
W_y = self.W(y) #bs,64,8,8
z = W_y + x #bs,64,8,8
return z五、SE模块

class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)六、ASM模块

class ASM(nn.Module):
def __init__(self, in_channels, all_channels):
super(ASM, self).__init__()
self.non_local = NonLocalBlock(in_channels)
self.selayer = SELayer(all_channels)
def forward(self, lc, fuse, gc):
fuse = self.non_local(fuse)
fuse = torch.cat([lc, fuse, gc], dim=1)
fuse = self.selayer(fuse)
return fuse七、ACSNet网络结构
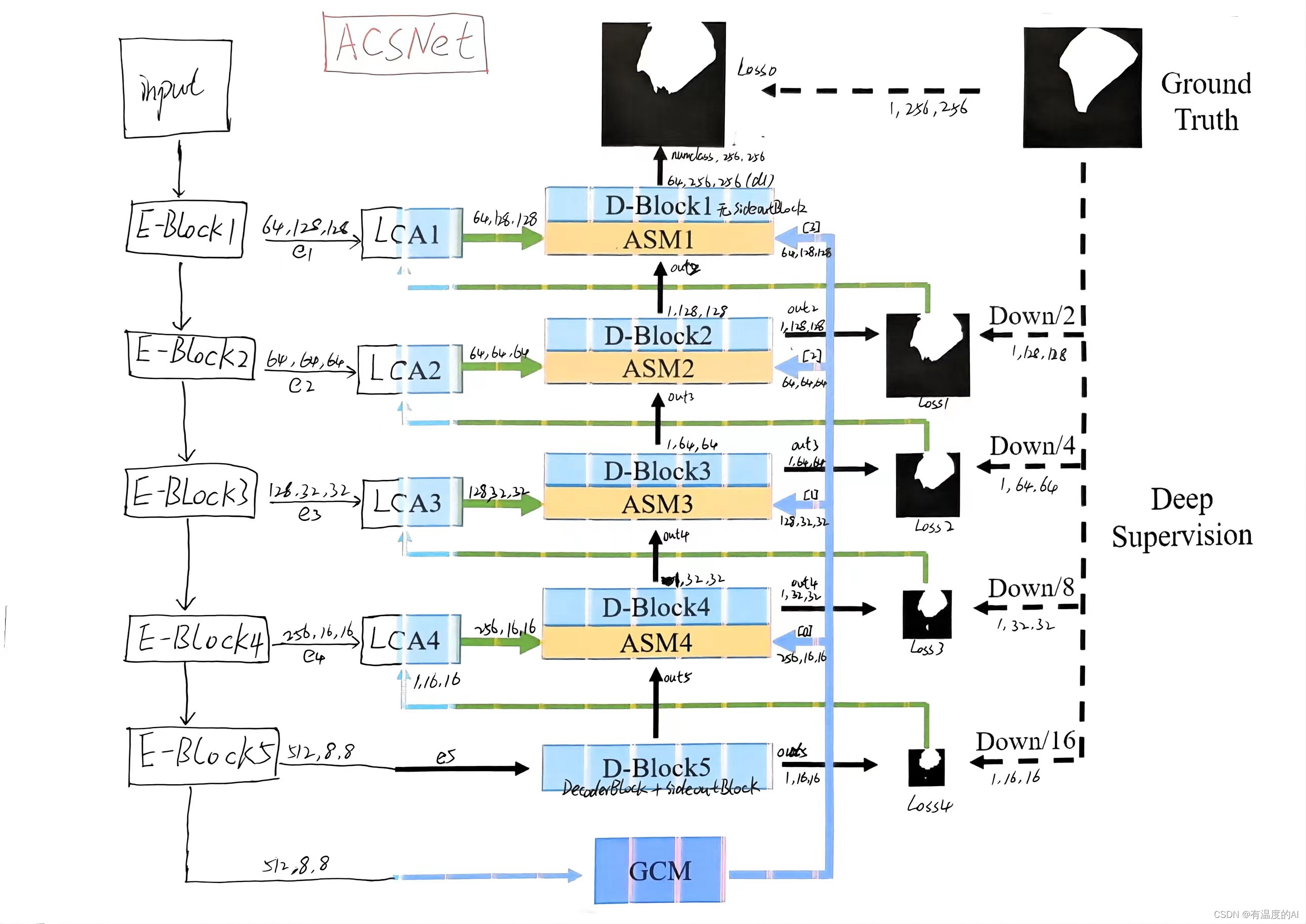
class ACSNet(nn.Module):
def __init__(self, num_classes):
super(ACSNet, self).__init__()
self.resnet = resnet34(pretrained=False)
# Encoder
self.encoder1_conv = self.resnet.conv1
self.encoder1_bn = self.resnet.bn1
self.encoder1_relu = self.resnet.relu
self.maxpool = self.resnet.maxpool
self.encoder2 = self.resnet.layer1
self.encoder3 = self.resnet.layer2
self.encoder4 = self.resnet.layer3
self.encoder5 = self.resnet.layer4
# Decoder
self.decoder5 = DecoderBlock(in_channels=512, out_channels=512)
self.decoder4 = DecoderBlock(in_channels=1024, out_channels=256)
self.decoder3 = DecoderBlock(in_channels=512, out_channels=128)
self.decoder2 = DecoderBlock(in_channels=256, out_channels=64)
self.decoder1 = DecoderBlock(in_channels=192, out_channels=64)
self.outconv = nn.Sequential(ConvBlock(64, 32, kernel_size=3, stride=1, padding=1),
nn.Dropout2d(0.1),
nn.Conv2d(32, num_classes, 1))
# Sideout
self.sideout2 = SideoutBlock(64, 1)
self.sideout3 = SideoutBlock(128, 1)
self.sideout4 = SideoutBlock(256, 1)
self.sideout5 = SideoutBlock(512, 1)
# local context attention module
self.lca1 = LCA()
self.lca2 = LCA()
self.lca3 = LCA()
self.lca4 = LCA()
# global context module
self.gcm = GCM(512, 64)
# adaptive selection module
self.asm4 = ASM(512, 1024)
self.asm3 = ASM(256, 512)
self.asm2 = ASM(128, 256)
self.asm1 = ASM(64, 192)
def forward(self, x):
# x: 3,256,256
e1 = self.encoder1_conv(x) # 64,128,128
e1 = self.encoder1_bn(e1)
e1 = self.encoder1_relu(e1)
e1_pool = self.maxpool(e1) # 64,64,64
e2 = self.encoder2(e1_pool) # 64,64,64
e3 = self.encoder3(e2) # 128,32,32
e4 = self.encoder4(e3) # 256,16,16
e5 = self.encoder5(e4) # 512,8,8
global_contexts = self.gcm(e5)
# print(global_contexts[0].shape) [1, 256, 16, 16]
# print(global_contexts[1].shape) [1, 128, 32, 32]
# print(global_contexts[2].shape) [1, 64, 64, 64]
# print(global_contexts[3].shape) [1, 64, 128, 128]
d5 = self.decoder5(e5) # 512,8,8->512,16,16
out5 = self.sideout5(d5) # 1,16,16
lc4 = self.lca4(e4, out5) # 256,16,16
gc4 = global_contexts[0]
comb4 = self.asm4(lc4, d5, gc4) # 1024, 16, 16
d4 = self.decoder4(comb4) # 256, 32, 32
out4 = self.sideout4(d4) # 1, 32, 32
lc3 = self.lca3(e3, out4) # 128, 32, 32
gc3 = global_contexts[1]
comb3 = self.asm3(lc3, d4, gc3) # 512,32,32
d3 = self.decoder3(comb3) # 128,64,64
out3 = self.sideout3(d3) # 1,64,64
lc2 = self.lca2(e2, out3) # 64,64,64
gc2 = global_contexts[2]
comb2 = self.asm2(lc2, d3, gc2) # 256, 64, 64
d2 = self.decoder2(comb2) # 64,128,128
out2 = self.sideout2(d2) # 1,128,128
lc1 = self.lca1(e1, out2) # 64,128,128
gc1 = global_contexts[3]
comb1 = self.asm1(lc1, d2, gc1) # 192,128,128
d1 = self.decoder1(comb1) # 64,256,256
out1 = self.outconv(d1) # num_classes,256,256
# return out1
return torch.sigmoid(out1), torch.sigmoid(out2), torch.sigmoid(out3), \
torch.sigmoid(out4), torch.sigmoid(out5)
if __name__ == '__main__':
input_tensor = torch.randn((1, 3, 256, 256))
model = ACSNet(num_classes=4)
# out1 = model(input_tensor)
# print(out1.shape)
o1,o2,o3,o4,o5 = model(input_tensor)
print(o1.shape,o2.shape,o3.shape,o4.shape,o5.shape)八、损失函数(Deep Supervision Loss)
def DeepSupervisionLoss(pred, gt):
d0, d1, d2, d3, d4 = pred[0:]
criterion = BceDiceLoss()
loss0 = criterion(d0, gt) #256,256
gt = F.interpolate(gt, scale_factor=0.5, mode='bilinear', align_corners=True)
loss1 = criterion(d1, gt) #128,128
gt = F.interpolate(gt, scale_factor=0.5, mode='bilinear', align_corners=True)
loss2 = criterion(d2, gt) #64,64
gt = F.interpolate(gt, scale_factor=0.5, mode='bilinear', align_corners=True)
loss3 = criterion(d3, gt) #32,32
gt = F.interpolate(gt, scale_factor=0.5, mode='bilinear', align_corners=True)
loss4 = criterion(d4, gt) #16,16
return loss0 + loss1 + loss2 + loss3 + loss4