前言
验证码(CAPTCHA)的全称为全自动区分计算机和人类的公开图灵测试(Completely Automated Public Turing testtotellComputersand Humans Apart)从其全称可以看出,验证码用 于测试用户是否为真实人类。一个典型的验证码由扭曲的文本组成,此时计算机程序难以解析,但
人类仍然可以( 希望如此 )阅读。许多网站使用验证码来防御与其网站交互的机器人程序。比如许多银行网站强制每次登录时都需要输入验证码,这就令人十分痛苦。本章将介绍如何自动化处理验证码问题,首先使用光学字符识别(Optical Character Recognition , OCR),然后使用一个验证码处理 API。
7.1注册账号
在前一章处理表单时,我们使用手工创建的账号登录网站,而忽略了自动化创建账号这一部分, 这是因为
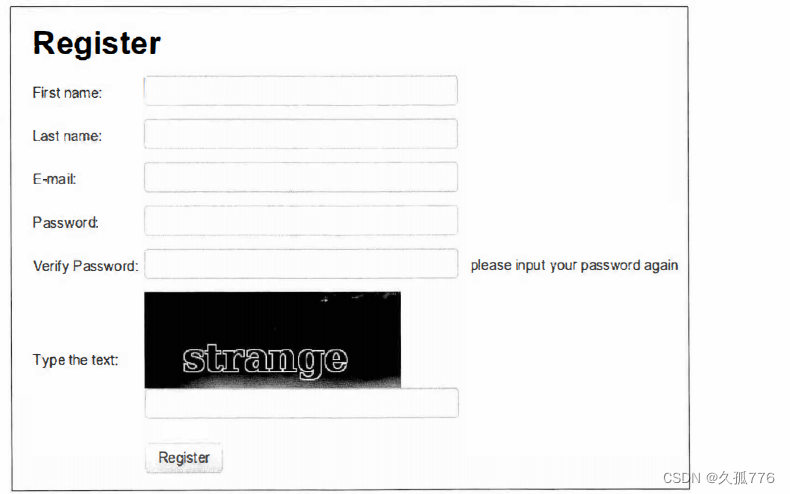
注册表单需要输入验证码。注册页面为 http://example.webscraping.com/user/register, 如下图所示
请注意,每次加载表单时都会显示不同的验证码图像。为了了解表单需要哪些参数,我们可以 复用上一章编写的parse_form( )函数。
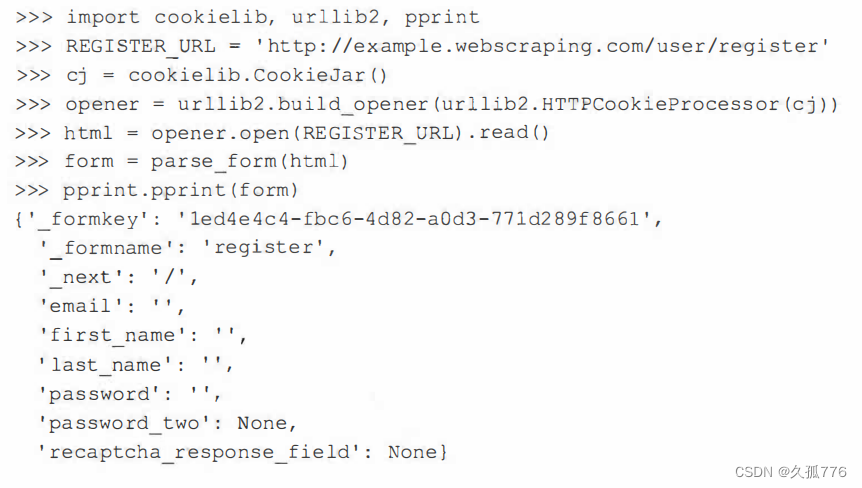
前面的代码中,除recaptcha_response_field之外的其他域都很容易处理,在本例中这个域要求我们从图像中抽取出strange字符串。
7.1 .1 加载验证码图像
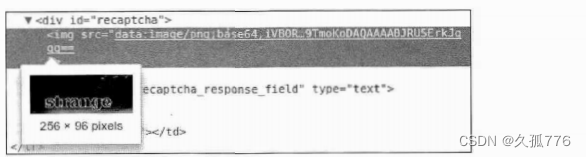
在分析验证码图像之前,首先需要从表单中获取该图像。通过 Firebug 可以看到,图像数据是嵌入在网页中的,而不是从其他 URL 加载过来的,如下图所示
为了在Python中处理该图像,我们将会用到 Pillow 包,可以使用如下命令通过 pip 安装该包。
pip install pillow
其他安装 Pillow 的方法可以参考 http://pillow.readthedocs.
org/installation.html
Pillow 提供了一个便捷的Image类,其中包含了很多用于处理验证码 图像的高级方法。下面的函数使用注册页的HTML作为输入参数,返回包含验证码图像的工mage对象。
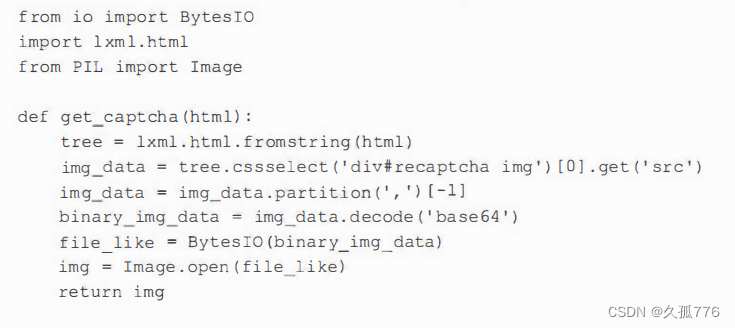
开始几行使用 lxml 从表单中获取图像数据。图像数据的前缀定义了数据类型。在本例中,这是一张进行了 Base64 编码的 PNG 图像,这种格式会使用ASCII编码表示二进制数据。我们可以通过在第一个逗号处分割的方法移除该前缀。然后,使用 Base64 解码图像数据,回到最初的二进制格式。要想加载图像,PIL需要一个类似文件的接口所以在传给Image类之前,我们又使用了Bytes IO对这个二进制数据进行了封装。
在得到这个格式更加合适的验证码图像后,我们就可以尝试从中抽取文本了

7.2 光学字符识别
光学字符识别( Optical Character Recognition, OCR)用于从图像中抽取文本。本节中,我们将使用开源的Tesseract OCR 引擎。该引擎最初由惠普公司开发,目前由 Google 主导。Tesseract 的安装说明可以从 https://code.google.com/p/tesseract-ocr/wiki/ReadMe获取。然后,可以使用p ip安装其Python封装版本pytesseract。
pip install pytes seract
如果直接把验证码原始图像传给 pyte sseract,解析结果一般都会很糟糕。

上面的代码在执行后,会返回一个空字符司抖也就是说 Tesseract 在抽取输入图像中的字符时失败了。这是因为 Tesseract 的设计初衷是抽取更加典型的文本,比如背景统一的书页。如果我们想要更加有效地使用 Tesseract,需要先修改验证码图像,去除其中的背景噪音,只保留文本部分。 为了更好地理解我们将要处理的验证码系统,下图中又给出了几个示例验证码。

从上图的例子可以看出,验证码文本一般都是黑色的,背景则会更加明亮,所以我们可以通过检查像素是否为黑色将文本分离出来,该处理过程又被称为阁值化。通过 Pillow 可以很容易地实现该处理过程。

此时,只有或淘值小于1的像素才会保留,也就是说,只有全黑的像素才会保留下来。这段代码片段保存了3张图像,分别是原始验证码图像、转换后的灰度图以及阔值化处理后的图像。下图所示为每个阶段保存的图像。

最终,经过阔值化处理的图像中,文本更加清晰,此时我们就可以将其传给 Tesseract 进行处理 了。

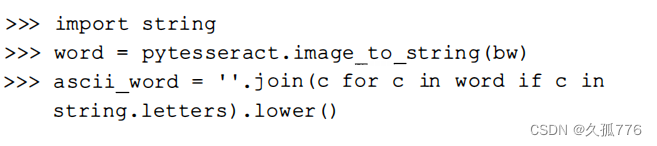
成功了!验证码中的文本已经被成功抽取出来了。在我测试的100张图片中,该方法正确解析了其中的84个验证码图像。由于示例文本总是小写的ASCII字符,因此我们可以将结果限定在这些字符中 ,从而进一步提高性能。
在对相同的 100 张图片的测试中,其识别率提高到了88%。下面是目前注册脚本的完整代码。
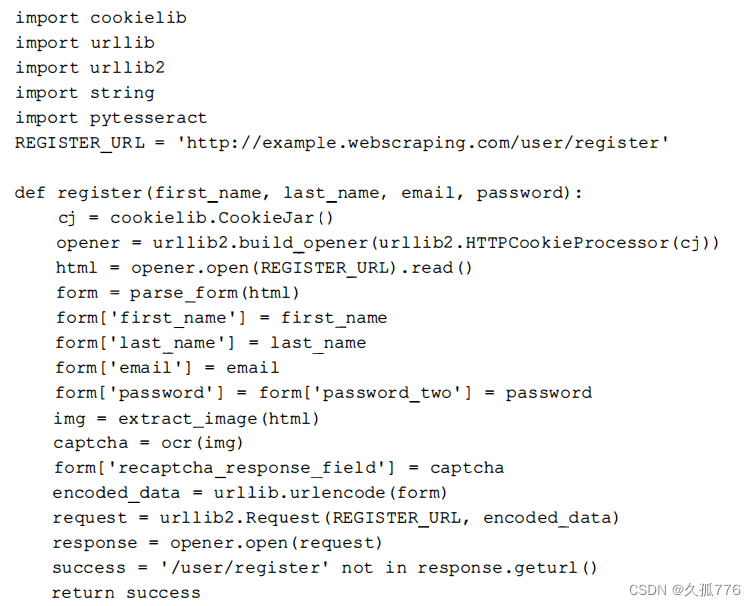

regi ster( )函数下载注册页面,抓取其中的表单,并在表单中设置新账号的名称、邮箱地址和密码。然后抽取验证码图像,传给OCR函数,并将OCR函数产生的结果添加到表单中。接下来提交表单数据,检查响应URL确认注册是否成功。如果注册失败,响应URL仍然会是注册页,这既可能是因为验证码图像解析不正确,也可能是注册账号的邮箱地址己经存在。现在,只需要使用新账号信息调用 regi ster( )函数,就可以注册账号了。

7.2.1 进一步改善
要想进一步改善验证码 OCR 的性能, 下面还有一些可能会使用 到 的方法:
实验不同阙值:
腐蚀阙值文本,突出字符形状:
调整图像大小( 有时增大只寸会起到作用 ):
根据验证码字体训练OCR工具:
限制结果为字典单词。
如果你对改善性能的实验感兴趣,可以使用该链接中的示例数据:https://bitbucket.org/wswp/ code/src/tip/chapter07/samples/。不过对于我们注册账号这一目的,目前88%的准确率已经足够 了,这是因为即使是真实用户也会在输入验证码文本时出现错误。实际上,即使1%的准确率也是足够的,因为脚本可以运行多次直至成功,不过这样做对服务器不
够友好,甚至可能会导致 IP 被封禁。
7.3 处理复杂验证码
前面用于测试的验证码系统相对来说比较容易处理,因为文本使用的黑色字体与背景很容易区分,而且文本是水平的,无须旋转就能被 Tesseract 准确解析。一般情况下,网站使用的都是类似这种比较简单的通用验证码系统,此时可以使用OCR方法。但是如果网站使用的是更加复杂的系统,比如Google 的 reCAPTCHA , OCR 方法则需要花费更多努力,甚至可能无法使用。
下图所示为网络上找到的一些更加复杂的验证码图像。

在这些例子中,因为文本被置于不同的角度,并且拥有不同的字体和颜色,所以要使用OCR方法的话,需要更多工作来清理这些噪音。即使是真实人类,解析这些图像也可能会存在困难,尤其是对于那些视觉障碍人士而言。
7.3.1 使用验证码处理服务
为了处理这些更加复杂的图像,我们将使用验证码处理服务。验证码处理服务有很多,比如 capt cha.com 和 deathbycaptcha.com,一般其服务价位在1美元1000个验证码图像左右。当把验证码图像传给它们的API时,会有人进行人工查看,并在 HTTP 响应中给出解析后的文本。一般来说该过程在30秒以内。在本节的示例中,我们将使用9kw.eu的服务。虽然该服务没有提供最便宜的验证码处理价格,也没有最好的API设计,但是使用该API可能不需要花钱。这是因为9kw.eu 允许用户人工处理验证码以获取积分,然后花费这些积分处理我们的验证码。
7.3.2 9kw入门
要想开始使用9kw,首先需要创建一个账号,注册网址为https://www.
9kw.eu/register.html,注册界面如下图所示
然后,按照账号确认说明进行操作。登录后,我们被定位到https://www.
9kw.eu/usercaptcha.html,其页面显示如下图所示
在本页中,需要处理其他用户的验证码未获取后面使用 API 时所需的积
分。在处理了几个验证码之后,会被定位到https://
www.91α1.eu/index.
cgi?action=userapinew&source=api来创建API key。
9kw 验iiH马 API
9kw的API文档地址为https://www.9kw.eu/api.html#apisubmit-tab。我们用
于提交验证码和检查结果的主要部分总结如下。
提交验证码
URL: https://www.9kw.eu/index.cgi( POST)
apikey: 你 的 API key
action:必须设为“usercaptchaup
I
oad”
file-upload-01:需要处理的图像( 文件、url或字符串)
base64:如果输入是 Base64 编码,则设为“1”
maxtimeout:等待处理的最长时间( 必须为 60~3999 秒 )
selfsolve:如果自己处理该验证码,则设为“ 1 ”
返回值:该验证码的ID
请求己提交验证码的结果
URL:
https://
www.9kw.eu/index.cgi
( GET )
apikey : 你的API
key
action : 必须设为“usercaptchacorrectdata”
id: 要检查的验证码 ID
info: 若设为1,没有得到结果时返回 “NODATA"( 默认返回空 )
返回值: 要处理的验证码文本或错误码
错误码
0001 API
ke y 不存在
0002 没有找到 API
ke y
0003 没有找到激活 的 API
ke y
0031 账号被系统禁用 24 小 时
0032 账号没有足够的权限
0033 需要升级插件
下面是发送验证码 图像到该 API 的初始实现代码 。
import urllib
import urllib2API_URL = ’https://www.9kw.eu/index.cgi’
def send_captcha (api_key, img_data) :
data = {
’ action ’:’ usercaptchaupload ’ ,
’ apikey ’:api_key,
’ file-upload-01’:img_data.encode(’base64’),
’ base64’:’1’,
’ selfsolve’:’1’,
’ maxtimeout’ :’60’
}
encoded_data = urllib.urlencode(data)
request = urllib2.Request(API_URL, encoded_data)
response = urllib2.urlopen(request)
return response.read ()
这个结构应该看起来很熟悉,首先我们创建了一个所需参数的字典,对其进行编码,然后将其作为请求体提交。需要注意的是,这里将selfsolve选项设为’1’,这种设置下,如果我们正在使用9kw 的Web界面处理验证码,那么验证码图像就会传给我们自己处理,从而可以节约我们的积分。如 果此时我们没有处于登录状态,验证码则会像平时一样传给其他用户。
下面是获取验证码图像处理结果的代码
def get_captcha(api_key, captcha_id):
data = {
’action’:’usercaptchacorrectdata’ ,
’id’:captcha_id,
’apikey’ : api_key
}
encoded data = urllib . url encode ( data )
# note this is a GET request
# so the data is appended to the URL
re sponse = urllib2.urlopen(API_URL + ’ ? ’ + encoded_data )
return response.read()
9kw的API有一个缺点是其响应是普通字符串,而不是类似 JSON 的结构化格式,这样就会使错误信息的区分更加复杂。例如,此时没有用户处理验证码图像,则会返回ERRORNOUSER字符 串。不过幸好我们提交的验证码图像永远不会包含这类文本。
另一个困难是,只有在其他用户有时间人工处理验证码图像时,getcaptcha( )函数才能返回错误信息,正如之前提到的,通常要在30秒之后。为了使实现更加友好,我们将会增加一个封装函数,用于提交验证码图像以及等待结果返回。下面的扩展版本代码把这些功能封装到一个可复用
类当中,另外还增加了检查错误信息的功能。
import time
import urllib
import urllib2
import re
from io import BytesIO
class CaptchaAP I:
def__init__( self,api_key,timeout=60):
self.api_key = api_key
self.timeout = timeout
self.url = ’https://www.9kw.eu/index.cgi’
def solve(self,img):
””” Submit CAPTCHA and return result when ready
”””
img_buffer = BytesIO()
img.save(img_buffer,format=”PNG”)
img_data = img_buffer.getvalue()
captcha_id = self.send(img_data)
start_time = time.time()
while time.time() < start_time + self.timeout:
try:
text = self.get (captcha_id)
except CaptchaError:
pass # CAPTCHA still not ready
else:
if text != ’NO DATA ’ :
if text == ’ERROR NO USER ’ :
raise CaptchaError(’ Error: no user
available to solve CAPTCHA’)
else :
print ’CAPTCHA solved!’


Capt chaAPI类的源码可以从https://bitbucket.org/wswp/code/src/tip/chapter07/api.py获取,该链接中的代码会在9kw.eu修改其API时保持更新。这个类使用你的APIkey以及超时时间进行实例化,其中超时时间默认为60秒然后,solve()方法把验证码图像提交给API,并持续请求,直到验证码图像处理完成或者到达超时时间。目前,检查 API响应中的错误信息时check()方法只检查 了初始字符,确认其是否遵循错误信息前包含4位数字错误码的格式。要想该 API在使用时更加健壮,可以对该方法进行扩展,使其包含全部34种错误类型。
下面是使用CaptchaAPI类处理验证码图像时的执行过程示例。
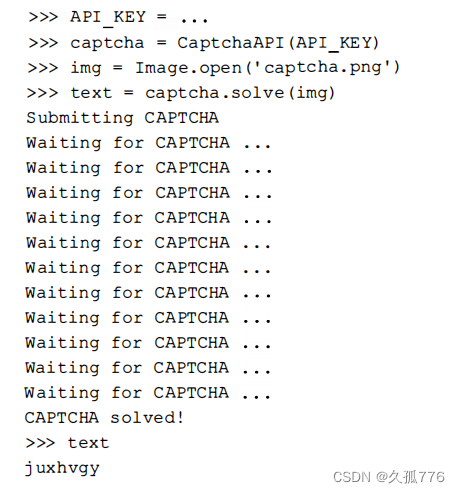
这是本章前面给出的第一个复杂验证码图像的正确识别结果。如果再次提交相同的验证码图像, 则会立即返回缓存结果,并且不会再次消耗积分。

7.3.3 与 注册功能集成
目前我们已经拥有了一个可以运行的验证码API解决方案,下面我们可以将其与前面的表单进行集成。下面的代码对register函数进行了修改,使其将处理验证码图像的函数作为参数传递进来这样我们就可以选择使用OCR方法还是API方法了。
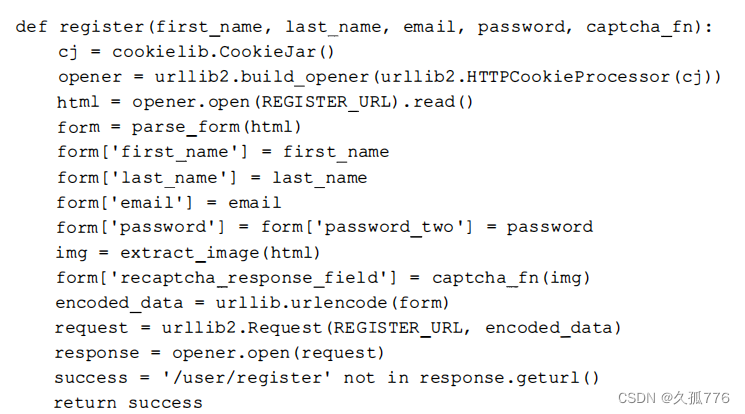
下面是使用该函数的例子。


运行成功了!我们从表单中成功获取到验证码图像,提交给9k的API,之后其他用户人工处理了该验证码,程序将返回结果提交到Web服务器端,注册了一个新账号。
7.4 本章小结
本章给出了处理验证码的方法:首先是使用OCR,然后是使用外部API。对于简单的验证码,或者需要处理大量验证码时,在OCR方法上花费时间是很值得的。否则,使用验证码处理API会更加经济有效。