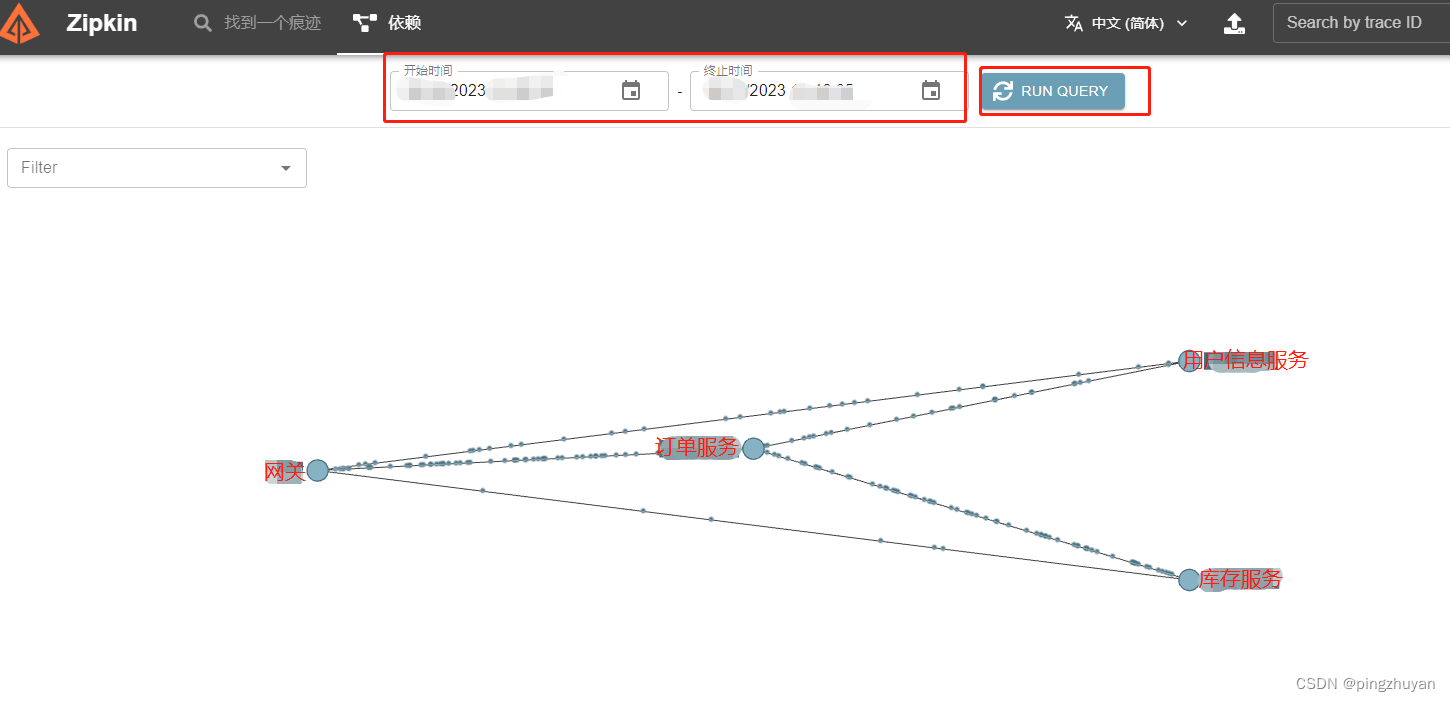
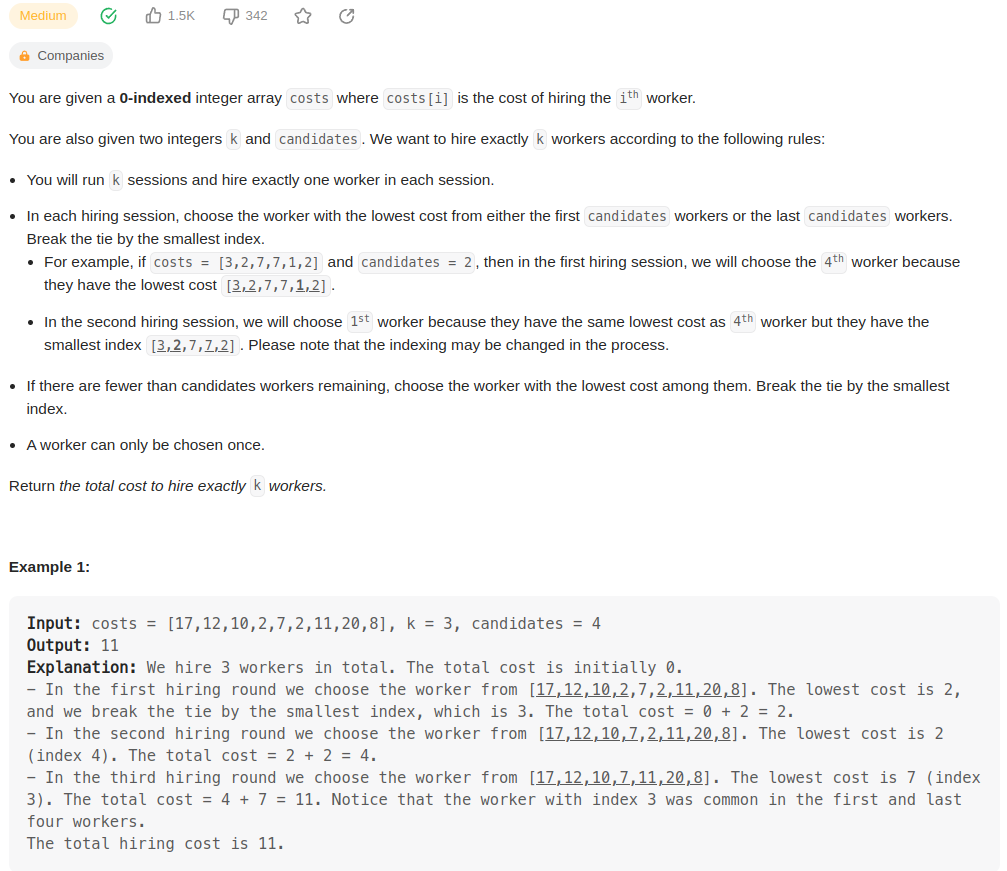
京东的 seckill 秒杀 专区 用 urllib 是获取不到的
回顾一下urllib 爬虫
# urllib 爬虫
from urllib import request
headers = {}
url = ''
# 请求定制
req = request(url=url, headers= headers)
# 模拟请求
response = request(req)
content = response.read().decode('utf-8')
# content 中 没有京东 秒杀专区 的源码
print(content)

Selenium
Selenium定义
- Selenium是一个用于Web应用程序测试的工具
- Selenium测试直接运行在浏览器中,就像真实的用户在操作一样
- 支持通过各种driver ( FireFoxDriver, InternetExplorerDriver、OperaDriver、ChromeDriver)驱动真实浏览器完成测试
- Selenium也是支持无界面浏览器操作的
为啥用Selenium
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
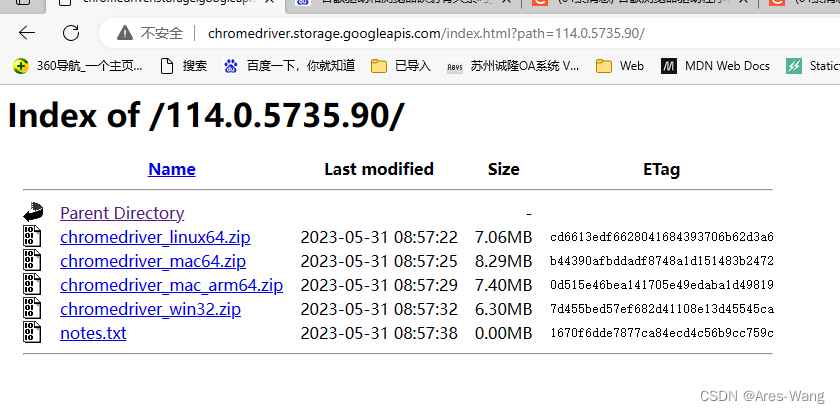
Selenium安装
- 操作谷歌浏览器驱动下载地址 http://chromedriver.storage.googleapis.com/index.html
- pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
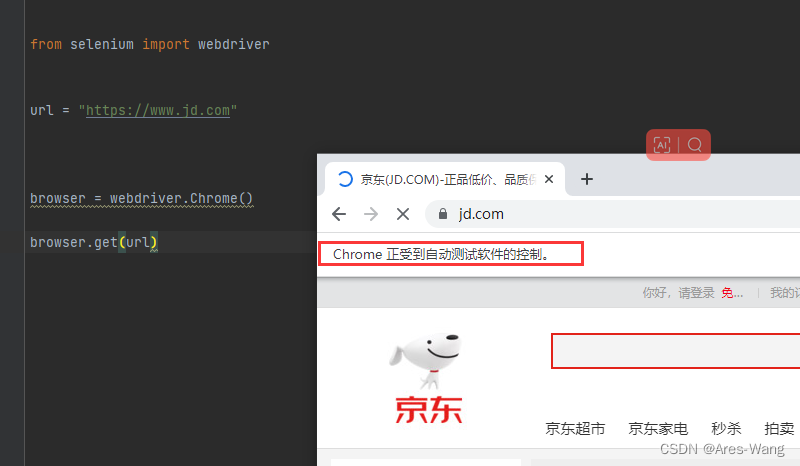
from selenium import webdriver
url = "https://www.jd.com"
browser = webdriver.Chrome()
# 自动打开谷歌浏览器 访问京东
browser.get(url)
# 访问源码
print(browser.page_source)
# 上面打开浏览器,会自动关闭
# 不自动关闭浏览器
#
from selenium import webdriver
url = "https://www.jd.com"
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 注意此处添加了chrome_options参数
browser = webdriver.Chrome(options=option)
# 自动打开谷歌浏览器 访问京东
browser.get(url)
# 访问源码
print(browser.page_source)
元素定位
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.baidu.com"
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 注意此处添加了chrome_options参数 , webdriver.Chrome 创建浏览器对象
browser = webdriver.Chrome(options=option)
browser.get(url)
# print(browser.page_source)
# 元素定位
# By.NAME By.ID By.XPATH By.TAG_NAME By.CSS_SELECTOR(BS4语法) PARTIAL_LINK_TEXT
# By.LINK_TEXT
# 常用 By.ID By.XPATH By.CSS_SELECTOR
# 根据id来定位元素
# button = browser.find_element_by_id('su') 旧版本才支持 返回元素对像
# button = browser.find_element(By.ID,'su') 返回元素对像
# 根据name来定位元素 <input name='wd'>
# button = browser.find_element(By.NAME,'wd') 返回元素对像
# find_elements 是查查找多个。 返回列表
button = browser.find_elements(By.XPATH,'//input') 返回元素对像列表
# print(button) 打印元素对象
button = browser.find_element(By.ID, 'su')
# 获取元素标签名称 Eg img,span、input等
print(button.tag_name)
# 获取标签的属性
print(button.get_attribute("Class"))
print(button.get_attribute("Value"))
print(button.get_property('value'))
# 获取元素文本 <element>文本</element>
print(button.text)
partial_link 翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位,
加油!ZENbrowser.find_elements(By.PARTIAL_LINK_TEXT,'加油')
交互

单击右键
鼠标右击的操作与左击有很大不同,需要使用 ActionChains 。
from selenium.webdriver.common.action_chains import ActionChains
定位搜索按钮
button = browser.find_element(By.XPATH,‘//*[@id=“toolbar-search-button”]/span’)
右键搜索按钮
ActionChains(browser).context_click(button).perform()
双击
模拟鼠标双击操作。
定位搜索按钮
button = browser.find_element(By.XPATH,‘//*[@id=“toolbar-search-button”]/span’)
执行双击动作
ActionChains(browser).double_click(button).perform()
拖动
模拟鼠标拖动操作,该操作有两个必要参数,
source:鼠标拖动的元素
target:鼠标拖至并释放的目标元素
定位要拖动的元素
source = browser.find_element(By.XPATH,‘xxx’)
定位目标元素
target = browser.find_element(By.XPATH,‘xxx’)
执行拖动动作
ActionChains(browser).drag_and_drop(source, target).perform()
悬停
定位收藏栏
collect = browser.find_element(By.XPATH,‘//’)
悬停至收藏标签处
ActionChains(browser).move_to_element(collect).perform()
键盘控制
webdriver 中 Keys 类几乎提供了键盘上的所有按键方法,我们可以使用 send_keys + Keys 实现输出键盘上的组合按键如 “Ctrl + C”、“Ctrl + V” 等。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By定位输入框并输入文本
browser.find_element(By.ID,‘xxx’).send_keys(‘ZEN’)
模拟回车键进行跳转(输入内容后)
browser.find_element(By.ID,‘xxx’).send_keys(Keys.ENTER)
使用 Backspace 来删除一个字符
browser.find_element(By.ID,‘xxx’).send_keys(Keys.BACK_SPACE)
Ctrl + A 全选输入框中内容
browser.find_element(By.ID,‘xxx’).send_keys(Keys.CONTROL, ‘a’)
Ctrl + C 复制输入框中内容
browser.find_element(By.ID,‘xxx’).send_keys(Keys.CONTROL, ‘c’)
Ctrl + V 粘贴输入框中内容
browser.find_element(By.ID,‘xxx’).send_keys(Keys.CONTROL, ‘v’)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.keys import Keys
url = "https://www.baidu.com"
# 关闭浏览器自动关闭
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
browser = webdriver.Chrome(options=option)
#
# browser = webdriver.Chrome()
browser.get(url)
# 设置浏览器大小
browser.set_window_size(width=200, height=400)
# 设置浏览器最大化 最小化
browser.maximize_window()
browser.minimize_window()
# 访问jd
browser.get('https://www.jd.com/')
time.sleep(2)
#访问 baidu
browser.get('https://www.baidu.com')
###
# 上面 会在原来的页面打开,而不是在新标签中打开
####
## 在原页面打开
browser.get('https:xxxx')
# 新标签中打开
js = "window.open('https://xxxxxxx')"
browser.execute_script(js)
###
# 浏览器睡眠2s
time.sleep(2)
# 根据id来定位元素 输入框
# 如果获得的元素是照片 可以对象的.location 获得坐标, .size 获取大小
text = browser.find_element(By.ID, 'kw')
# 模拟输入指定内容
text.send_keys('Ares_ZEN')
# 文本框回车键
text.send_keys(Keys.ENTER)
# 根据id 定位 百度一下 按钮
button = browser.find_element(By.ID, 'su')
button.click()
time.sleep(2)
# 滚动条滑到最下面
js_bottom = 'document.documentElement.scrollTop=10000'
browser.execute_script(js_bottom)
time.sleep(2)
# 点击下一页
next = browser.find_element(By.XPATH, "//a[@class='n']")
next.click()
time.sleep(2)
browser.execute_script(js_bottom)
#通过 x ,y 坐标滑动对于这种通过坐标滑动的方法,我们需要知道做表的起始位置在页面左上角(0,0)
# js = "window.scrollTo(0,500);"
# driver.execute_script(js)
time.sleep(2)
# 浏览器 回退
browser.back()
time.sleep(2)
# 刷新页面
browser.refresh()
time.sleep(2)
# 浏览器 前进
browser.forward()
time.sleep(2)
# 关闭当前页
browser.close()
# 退出浏览器
browser.quit()
switch.to.[window | frame |alert]
浏览器窗口切换
在很多时候我们都需要用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位注册页面的标签就会发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照时间来的,最新打开的窗口放在数组的末尾,这时我们就可以定位到最新打开的那个窗口了。
获取打开的多个窗口句柄
windows = browser.window_handles
#切换到当前最新打开的窗口
browser.switch_to.window(windows[-1])
表单切换
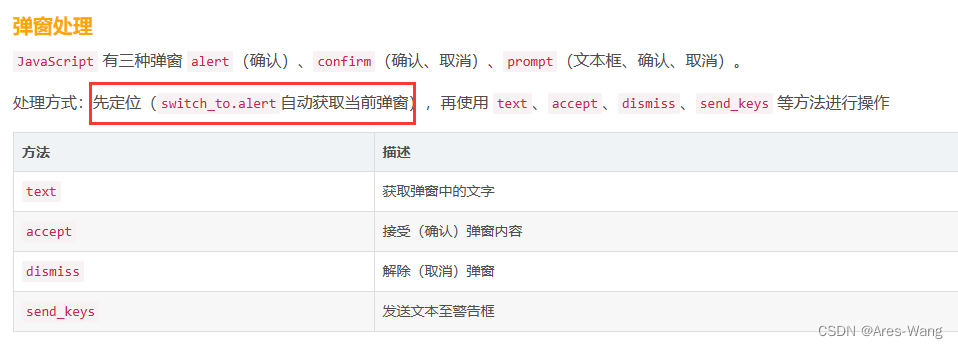
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch_to.frame() 方法将当前操作的对象切换成 frame/iframe 内嵌的页面。
switch_to.frame() 默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 读取本地html文件
driver.get('file:///' + str(Path(Path.cwd(), 'iframe测试.html')))
# 1.通过id定位
driver.switch_to.frame('id')
# 2.通过name定位
# driver.switch_to.frame('name')
# 通过xpath定位
# 3.iframe_label = driver.find_element(By.XPATH,'/html/body/iframe')
# driver.switch_to.frame(iframe_label)
from selenium import webdriver
from pathlib import Path
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 打开本地xx.html 网页
# Path.cwd() 当前的项目的路径
# Path(Path.cwd(), 'XX.html') 当前的项目的路径 和xx.html 拼接
driver.get('file:///' + str(Path(Path.cwd(), 'XX.html')))
sleep(2)
# 点击alert按钮
driver.find_element(By.XPATH,'//*[@id="alert"]').click()
sleep(1)
# 获取弹出的窗体对象
alert = driver.switch_to.alert
# 打印alert弹窗的文本
print(alert.text)
# 确认
alert.accept()
sleep(2)
# 点击confirm按钮
driver.find_element(By.XPATH,'//*[@id="confirm"]').click()
sleep(1)
# 获取弹出的窗体对象
confirm = driver.switch_to.alert
print(confirm.text)
# 取消
confirm.dismiss()
sleep(2)
# 点击confirm按钮
driver.find_element(By.XPATH,'//*[@id="prompt"]').click()
sleep(1)
# 获取弹出的窗体对象
prompt = driver.switch_to.alert
print(prompt.text)
# 向prompt的输入框中传入文本
prompt.send_keys("ZEN")
sleep(2)
prompt.accept()
设置元素等待
很多页面都使用 ajax 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。webdriver 中的等待分为 显式等待 和 隐式等待。
显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(TimeoutException)。显示等待需要使用 WebDriverWait,同时配合 until 或 not until 。下面详细讲解一下。
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
- driver:浏览器驱动
- timeout:超时时间,单位秒
- poll_frequency:每次检测的间隔时间,默认为0.5秒
- ignored_exceptions:指定忽略的异常,如果在调用 until 或 until_not的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有 NoSuchElementException 。
until(method, message=’ ‘)
until_not(method, message=’ ')
method:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。
until_not 正好相反,当元素消失或指定条件不成立,则继续执行后续代码
message: 如果超时,抛出 TimeoutException ,并显示 message 中的内容
method 中的预期条件判断方法是由 expected_conditions 提供,下面列举常用方法。
定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
># Tuple 元组
locator = (By.ID, 'kw')
element = browser.find_element(By.ID,'kw')
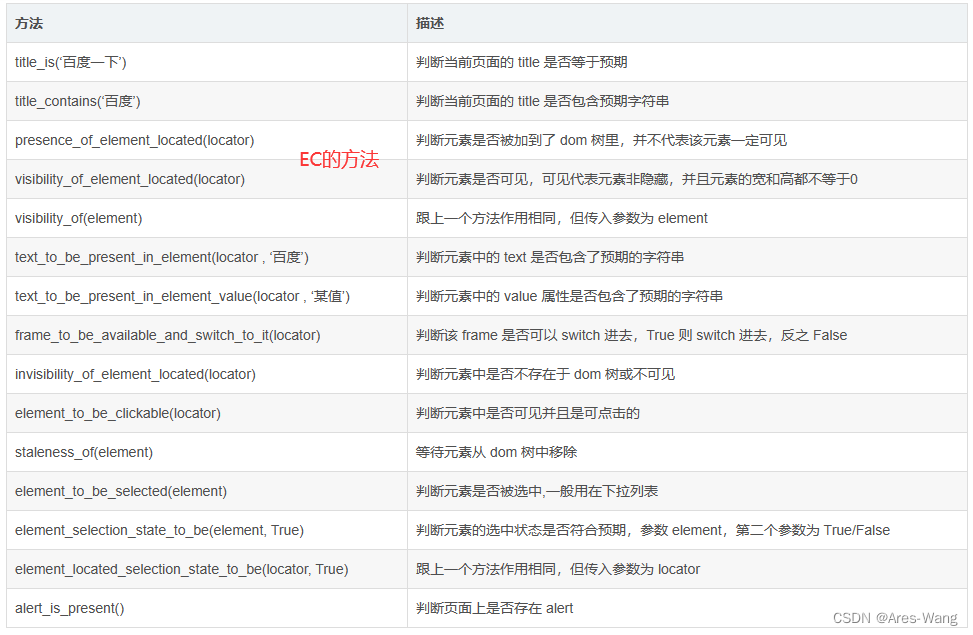
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, 'kw')),
message='超时啦!')
隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 NoSuchElementException 异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用 implicitly_wait() 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 id 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间
from selenium import webdriver
from time import time
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('url')
start = time()
browser.implicitly_wait(5)
try:
browser.find_element(By.ID,'kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')
代码运行到 browser.find_element(By.ID,‘kw’)这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
强制等待
使用 time.sleep() 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('url')
start = time()
sleep(5)
try:
driver.find_element(By.ID,'kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')
值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
下载文件
Chrome浏览器
Firefox 浏览器要想实现文件下载,需要通过 add_experimental_option 添加 prefs 参数。
download.default_directory:设置下载路径。
profile.default_content_settings.popups:0 禁止弹出窗口。
from selenium import webdriver
from selenium.webdriver.common.by import By
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory': str(Path.cwd())}
option = webdriver.ChromeOptions()
option.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=option)
driver.get("xxx")
# 下载会弹出对话框
driver.find_element(By.ID,'xxx').click()
driver.switch_to.window(driver.window_handles[-1])
driver.find_element(By.ID,'./html').send_keys('thisisunsafe')
Firefox浏览器
Firefox 浏览器要想实现文件下载,需要通过 set_preference 设置 FirefoxProfile() 的一些属性。
browser.download.foladerList:0 代表按浏览器默认下载路径;2 保存到指定的目录。
browser.download.dir:指定下载目录。
browser.download.manager.showWhenStarting:是否显示开始,boolean 类型。
browser.helperApps.neverAsk.saveToDisk:对指定文件类型不再弹出框进行询问。
from selenium import webdriver
import os
from selenium.webdriver.common.by import By
fp = webdriver.FirefoxProfile()
fp.set_preference("browser.download.dir",os.getcwd())
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showhenStarting",True)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/octet-stream")
driver = webdriver.Firefox(firefox_profile = fp)
driver.get("https://pic.sogou.com/d?query=%E7%83%9F%E8%8A%B1&did=4&category_from=copyright")
driver.find_element(By.ID,'//xx').click()
cookies操作
cookies 是识别用户登录与否的关键,爬虫中常常使用 selenium + requests 实现 cookie持久化,即先用 selenium 模拟登陆获取 cookie ,再通过 requests 携带 cookie 进行请求。
webdriver 提供 cookies 的几种操作:读取、添加删除。
get_cookies:以字典的形式返回当前会话中可见的 cookie 信息。
get_cookie(name):返回 cookie 字典中 key == name 的 cookie 信息。
add_cookie(cookie_dict):将 cookie 添加到当前会话中
delete_cookie(name):删除指定名称的单个 cookie。
delete_all_cookies():删除会话范围内的所有 cookie。
下面看一下简单的示例,演示了它们的用法。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("URL")
# 输出所有cookie信息
print(driver.get_cookies())
cookie_dict = {
'domain': 'aa',
'expiry': 1664765502,
'httpOnly': False,
'name': 'test',
'path': '/',
'secure': True,
'value': 'null'}
# 添加cookie
driver.add_cookie(cookie_dict)
# 显示 name = 'test' 的cookie信息
print(driver.get_cookie('test'))
# 删除 name = 'test' 的cookie信息
driver.delete_cookie('test')
# 删除当前会话中的所有cookie
driver.delete_all_cookies()
通过参照标签滑动
这种方式需要先找一个参照标签,然后将滚动条滑动至该标签的位置。我们用循环来实现重复滑动。该 li 标签实际是一种懒加载,当用户滑动至最后标签时,才会加载后面的数据。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://blog.csdn.net/")
sleep(1)
driver.implicitly_wait(3)
for i in range(31, 102, 10):
sleep(1)
target = driver.find_element(By.XPATH,f'//*[@id="feedlist_id"]/li[{i}]')
driver.execute_script("arguments[0].scrollIntoView();", target)
获取当前页面url
driver.current_url
获取当前html源码
driver.page_source
获取当前页面标题
driver.title
获取浏览器名称(chrome)
driver.name
对页面进行截图,返回二进制数据
driver.get_screenshot_as_png()
对当前页面进行截图
driver.save_screenshot(‘page.png’)
设置浏览器尺寸
driver.get_window_size()
获取浏览器尺寸,位置
driver.get_window_rect()
获取浏览器位置(左上角)
driver.get_window_position()
设置浏览器尺寸
driver.set_window_size(width=1000, height=600)
设置浏览器位置(左上角)
driver.set_window_position(x=500, y=600)
设置浏览器的尺寸,位置
driver.set_window_rect(x=200, y=400, width=1000, height=600)
selenium进阶
隐藏特征
chrome_options.add_argument(‘–user-agent=“”’) # 设置请求头的User-Agent
chrome_options.add_argument(‘–window-size=1280x1024’) # 设置浏览器分辨率(窗口大小)
chrome_options.add_argument(‘–start-maximized’) # 最大化运行(全屏窗口),不设置,取元素会报错
chrome_options.add_argument(‘–disable-infobars’) # 禁用浏览器正在被自动化程序控制的提示
chrome_options.add_argument(‘–incognito’) # 隐身模式(无痕模式)
chrome_options.add_argument(‘–hide-scrollbars’) # 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument(‘–disable-javascript’) # 禁用javascript
chrome_options.add_argument(‘–blink-settings=imagesEnabled=false’) # 不加载图片, 提升速度
chrome_options.add_argument(‘–headless’) # 浏览器不提供可视化页面
chrome_options.add_argument(‘–ignore-certificate-errors’) # 禁用扩展插件并实现窗口最大化
chrome_options.add_argument(‘–disable-gpu’) # 禁用GPU加速
chrome_options.add_argument(‘–disable-software-rasterizer’) # 禁用 3D 软件光栅化器
chrome_options.add_argument(‘–disable-extensions’) # 禁用扩展
chrome_options.add_argument(‘–start-maximized’) # 启动浏览器最大化
# https://bot.sannysoft.com/ 真实浏览器打开和selenium 访问 结果有差异的
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://bot.sannysoft.com/')
关键点在于如何在浏览器检测之前将这些特征进行隐藏,解决这个问题的关键,实际就是一个 stealth.min.js 文件,这个文件是给 puppeteer 用的,在 Python 中使用的话需要单独执行这个文件,该文件获取方式需要安装 node.js ,如果已安装的读者可以直接运行如下命令即可在当前目录生成该文件。

npx extract-stealth-evasions
import time
from selenium import webdriver
option = webdriver.ChromeOptions()
# 没有界面
option.add_argument("--headless")
# 无头浏览器需要添加user-agent来隐藏特征
option.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36')
driver = webdriver.Chrome(options=option)
# 隐式等待
driver.implicitly_wait(5)
# stealth.min.js 放在根目录下
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('hidden_features.png')
通过 stealth.min.js 的隐藏,可以看到这次使用无头浏览器特征基本都以隐藏,已经十分接近人工打开浏览器了。
stealth.min.js 下载