参考:
https://aistudio.baidu.com/aistudio/projectdetail/4353348
https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md
-
注意
1)安装paddlespeech,参考:
https://blog.csdn.net/weixin_42357472/article/details/131269539?spm=1001.2014.3001.55022)运行代码过程中下载模型报错RuntimeError: Download from https://paddlespeech.bj.bcebos.com/vector:
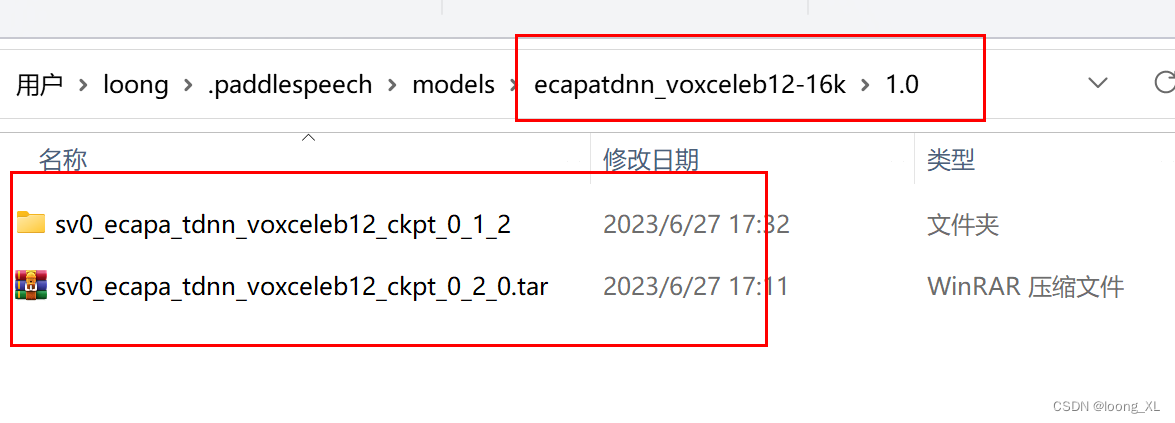
可以自己离线下载下来,根据提示下载链接https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz,paddlespeech模型一般放在C:\Users\loong.paddlespeech\models下;注意这边模型目录结构一般是如下,并且tar包也要放在一块才可以

使用
** paddlespeech提取向量维度是192
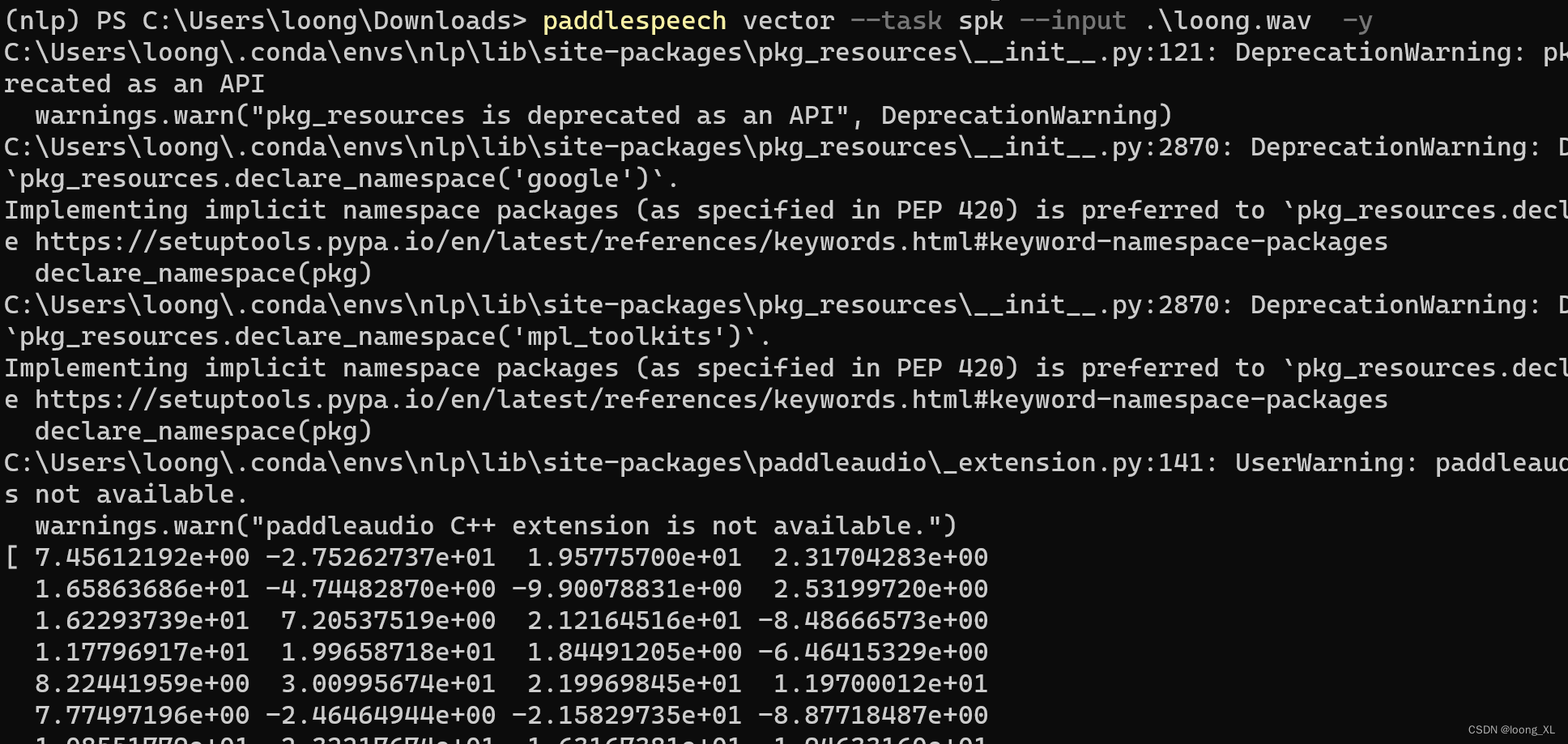
1)命令行使用:
paddlespeech vector --task spk --input zh.wav
paddlespeech vector --task score --input "./85236145389.wav ./123456789.wav"
2)向量提取代码使用:
from paddlespeech.cli.vector import VectorExecutor
vec = VectorExecutor()
result = vec(audio_file="zh.wav")
from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
audio_emb = vector_executor(
model='ecapatdnn_voxceleb12',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./85236145389.wav',
device=paddle.get_device())
print('Audio embedding Result: \n{}'.format(audio_emb))
3)声纹相似度计算:
import paddle
from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
audio_emb = vector_executor(
model='ecapatdnn_voxceleb12',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./85236145389.wav',
device=paddle.get_device())
print(audio_emb.shape)
print('Audio embedding Result: \n{}'.format(audio_emb))
test_emb = vector_executor(
model='ecapatdnn_voxceleb12',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./123456789.wav',
device=paddle.get_device())
print(test_emb.shape)
print('Test embedding Result: \n{}'.format(test_emb))
# score range [0, 1]
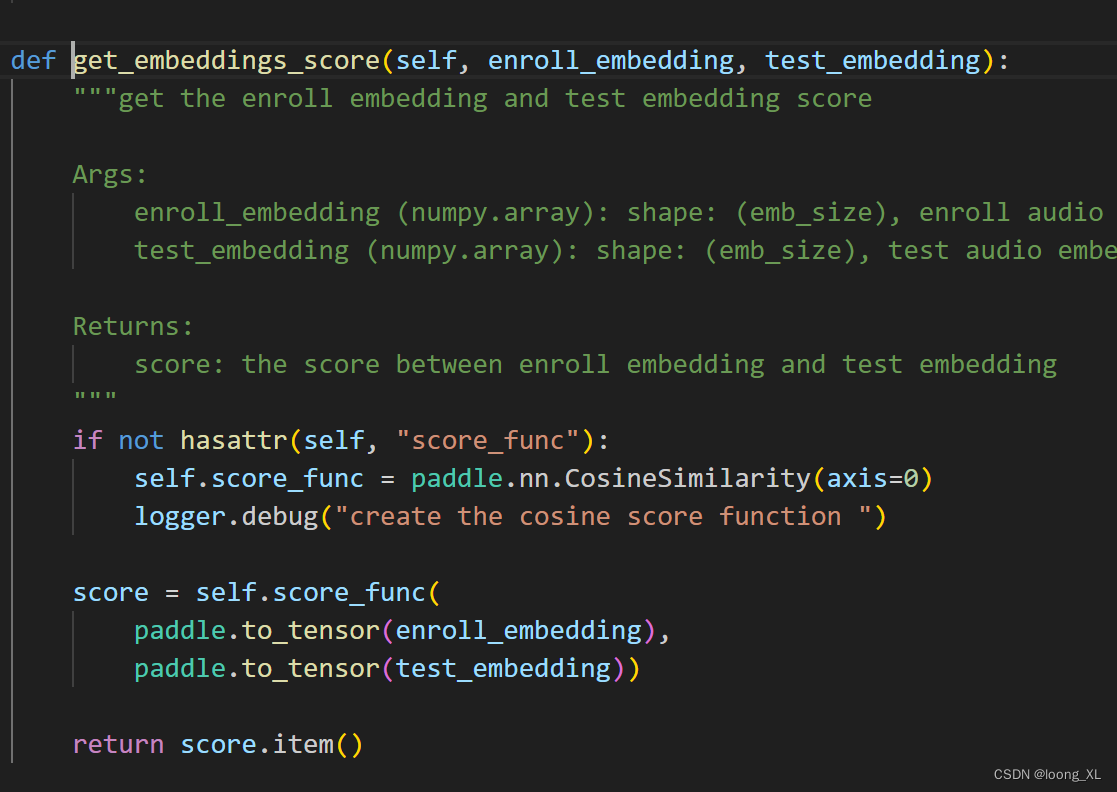
score = vector_executor.get_embeddings_score(audio_emb, test_emb)
print(f"Eembeddings Score: {score}")
底层相似度计算用的CosineSimilarity,结果越大越好