shuffle是什么
shuffle是Hadoop大数据计算中,一个必不可少的环节,通过shuffle可以将不同节点上的同类数据给移动到一起,这在分组,排序,聚合的场景中非常常见,简单图示如下:
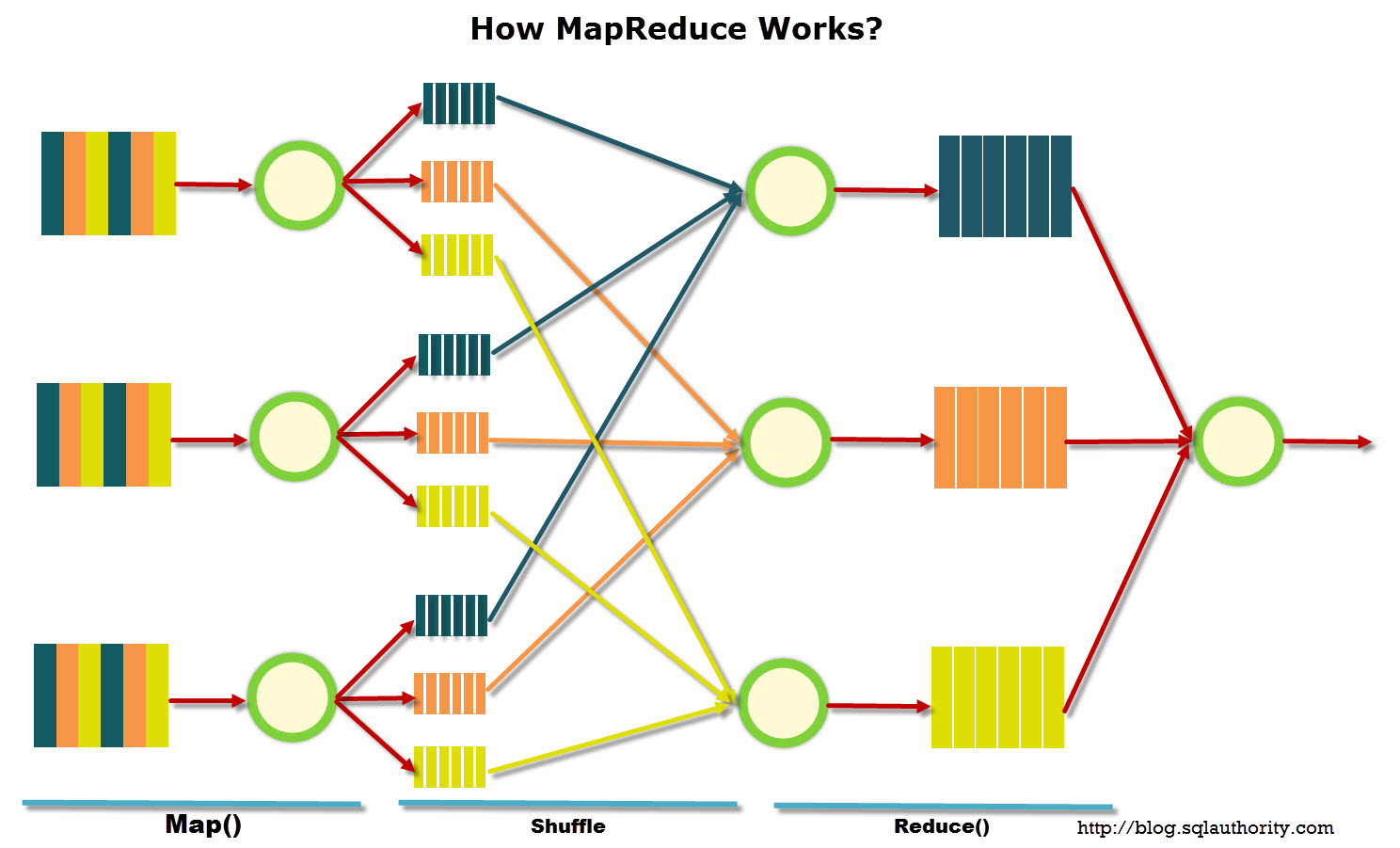
MapReduce数据处理模型假设数据以分布式方式存储在多台机器上,并以一些记录的形式组织起来。数据处理分 3 个阶段进行:
shuffle的三个阶段
Map阶段
使用用户自定义的映射函数,来对数据进行处理,这个阶段的主要目标是预处理和过滤数据,map函数会逐条处理数据集中的每一条数据,然后输出一组(K,V)集合,这里可以有三种情况:
- 不产生任何数据,也就是说数据被全部过滤掉或者数据源为空
- 生成一个 (K,V)对,如果count,max,min,avg,sum等聚合函数
- 生成多个 (K,V)对,如查询,去重,处理转换后的数据
Shuffle阶段
这个阶段所有的(K,V)对,也就是 map 阶段产生的所有键值对都按键排序并分布在集群中的机器上
Reduce阶段
对每个节点上的数据按照 K % (reduce number) 进行横跨节点的分发, reduce 函数计算每组具有相同键的键值对的最终结果。这样 K 相同的数据都会被 shuffle 到同一个节点,形成节点内局部有序的状态。如果想要全局有序,还需要在加一个 reduce 阶段,从而完成最终的排序
Spark中的shuffle
默认情况下,MR任务shuffle都是由当前任务内部完成的,也就是启动了一个spark job,这个job在内部就可完成整个shuffle流程,也就是实时对接的模式,类似快递小哥送快递给你,到你家楼下打电话给你,不见你面他就一直等着你,直到你来了之后,他把快递亲自交到你的手中,他才可以去干下一件快递的排送,这种模式就是默认shuffle的工作原理。
但缺点比较明显,就是资源利用率低,因为等你的途中,快递小哥什么都不能干,所以才有了快递代收点这种产物,在spark里面,可以专门部署一个内置或外置的独立的shuffle服务来处理shuffle数据,这样可以有几个优点:
1,提高资源利用率,
2,增加动态资源调度的弹性,避免开启了动态资源调度时,因为shuffle数据的占用,导致executor无法回收的问题,或者因为executor被回收了,造成shuffle数据被销毁,从而触发该子任务的重算流程
3,减少executor内部之间网络带宽和本地带宽的占用
外部独立的shuffle服务的存储可以不占用YARN内部的本地磁盘,使用独立的SSD磁盘或者SSD的云存储再配上100G的网络带宽来加速shuffle处理性能。
shuffle数据的存储
此外提交spark任务默认shuffle的存储目录为/tmp目录,如果worker节点上这个默认的存储目录的大小比较小,可以在
spark-defaults.conf中配置默认目录:
spark.local.dir /path/local/dir1,/path/local/dir1或者在应用提交时增加参数:
spark-submit --conf "spark.local.dir=/path/to/local/dir" ...shuffle数据的回收
shuffle 数据的回收与应用的生命周期有关,当应用结束时一般会自动清理,当前某些情况下shuffle数据可能并不会被清理掉,这个时候我们需要编写脚本或程序来周期性的清理,spark中shuffle的清理的配置参数如下:
| 参数 | 默认值 | 解释 | 版本支持 |
| spark.cleaner.periodicGC.interval | 30min | 控制触发垃圾收集的频率。 仅当弱引用被垃圾收集时,此上下文清理器才会触发清理。在具有大型驱动程序 JVM 的长时间运行的应用程序中,驱动程序几乎没有内存压力,这种情况可能偶尔会发生或根本不会发生。根本不清理可能会导致执行器在一段时间后耗尽磁盘空间 | 1.6.0 |
| spark.cleaner.referenceTracking | true | 启用或禁用上下文清理 | 1.0.0 |
| spark.cleaner.referenceTracking.blocking | true | 控制清理线程是否应阻塞清理任务(shuffle 除外,这是由 Spark.cleaner.referenceTracking.blocking.shuffle Spark 属性控制的) | 1.0.0 |
| spark.cleaner.referenceTracking.blocking.shuffle | false | 控制清理线程是否应阻塞随机清理任务 | 1.1.1 |
| spark.cleaner.referenceTracking.cleanCheckpoints | false | 控制在引用超出范围时是否清理检查点文件 |
动态资源调度
通过动态资源调度,可以提升集群资源利用率,但动态资源调度的executor在被回收后,会造成shuffle数据的丢失,当我们启动了外置独立的shuffle服务就可以解决问题。
配置动态资源调度的两种方式:
第一种:使用默认的shuffle service,但需要注意executor的回收策略
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.shuffleTracking.enabled=true第二种:使用外置的shuffle service
spark.dynamicAllocation.enabled=true
spark.shuffle.service.enabled=true注意:以上的 shuffleTracking 或外部 shuffle 服务的目的是允许删除 executor 而不删除它们生成的 shuffle 文件
启用 shuffleTracking 很简单,但设置外部 shuffle 服务的方法,不同的资源调度器配置都不一样,如standalone,YARN,Mesos等
- standalone模式:设置 spark.shuffle.service.enabled = true 即可
- Mesos coarse-grained 模式:
-
- 启动 $SPARK_HOME/sbin/start-mesos-shuffle-service.sh
- 设置 spark.shuffle.service.enabled = true
3. yarn 模式:
-
- 确保spark-<version>-yarn-shuffle.jar在nodemanager节点的classpath中,可以将这个jar放在hadoop的common目录下
- 确保这个jar在集群所有 nodemanager 节点的 claapath路径中
- 在yarn-site.xml中,追加 spark_shuffle选项到 yarn.nodemanager.aux-services配置项的value中,然后将yarn.nodemanager.aux-services.spark_shuffle.class 设置为org.apache.spark.network.yarn.YarnShuffleService
- 增加 nodemanager 的内存,默认1GB不够用
- 重启所有的nodemanager节点
动态资源调度的配置项参考:
Configuration - Spark 3.0.1 Documentation