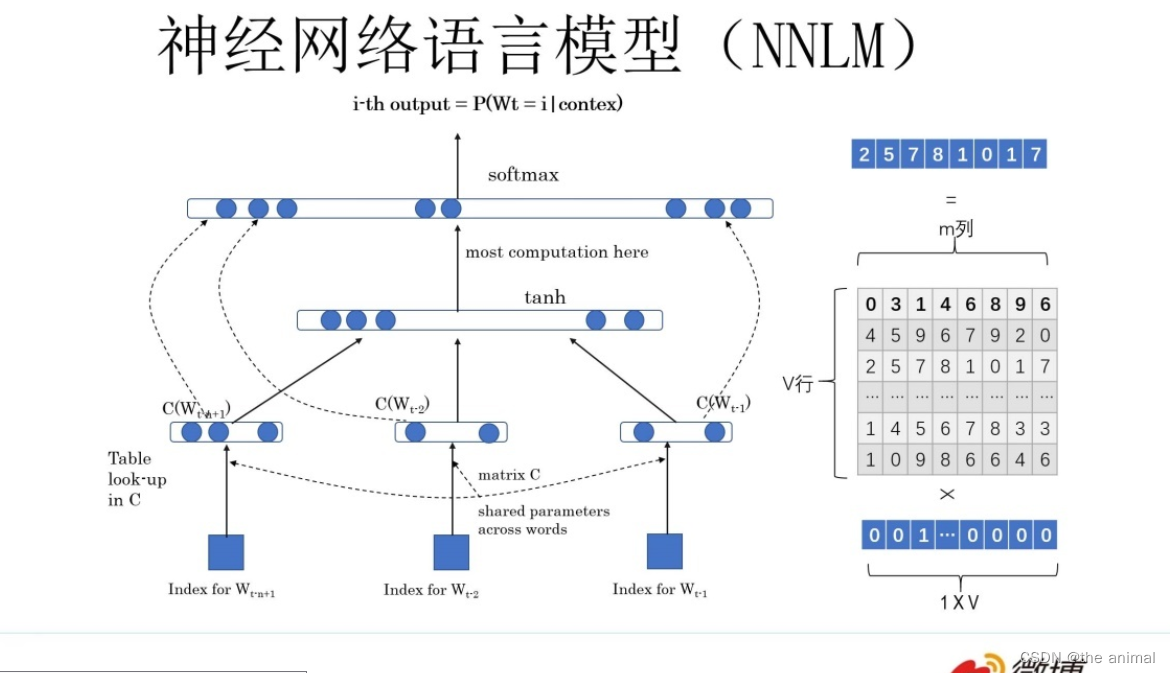
1.3负载均衡
1.3.1什么是负载均衡
负载均衡(Load Balance)是一种技术解决方案。用来在多个资源(一般是服务器)中分配负载,达到最优化资源使用,避免单台服务器过载。
RocketMQ中的负载均衡主要可以分为生产者发送消息的负载均衡和消费者订阅消息的负载均衡以及消费者分配队列的负载均衡。
1.3.2生产者发送消息负载均衡:轮询message queue发送
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。
注:多个队列可以部署在一台机器上即同一台broker,也可以分别部署在多台不同的机器上即不同的broker。
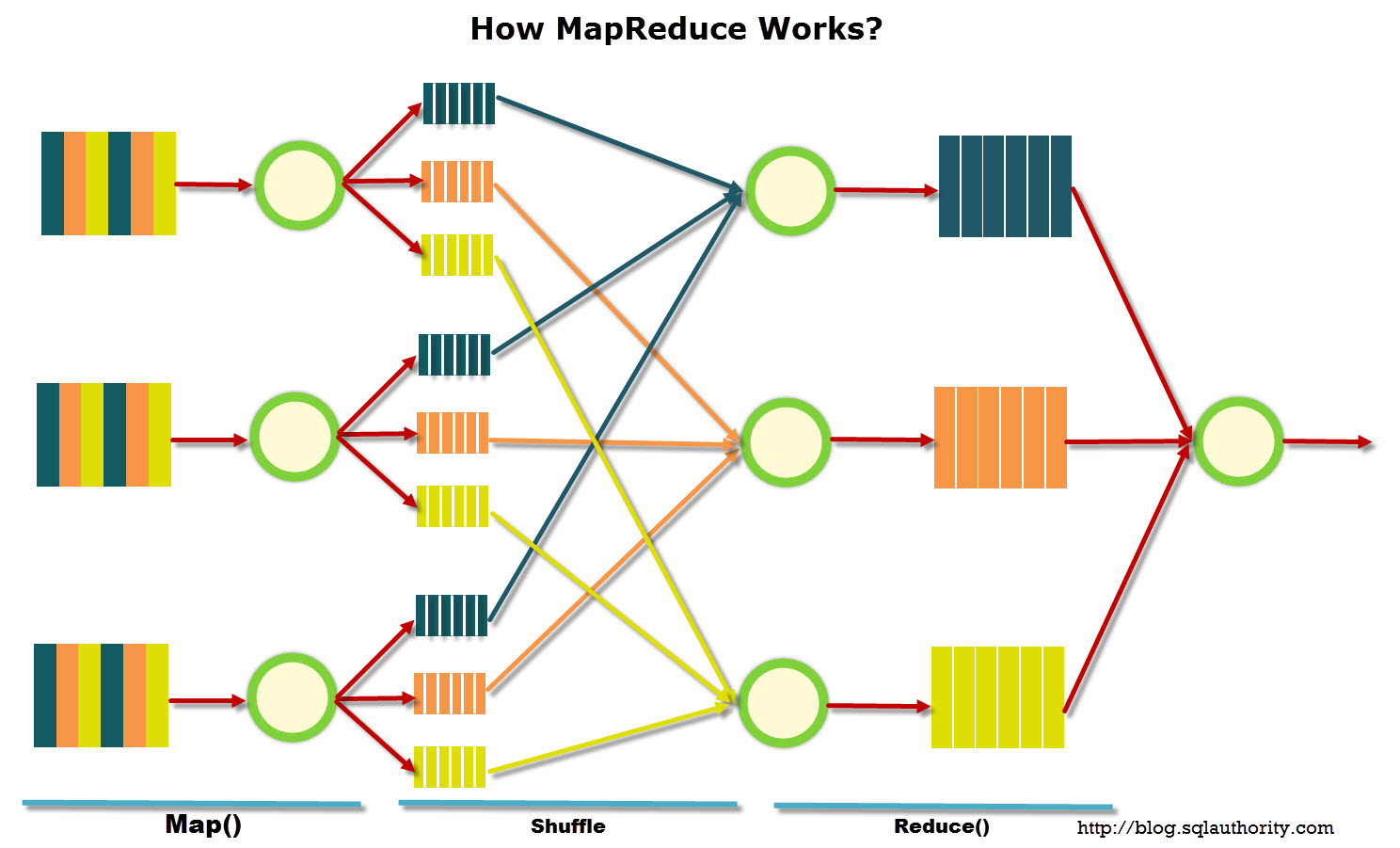
而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下,如下图:
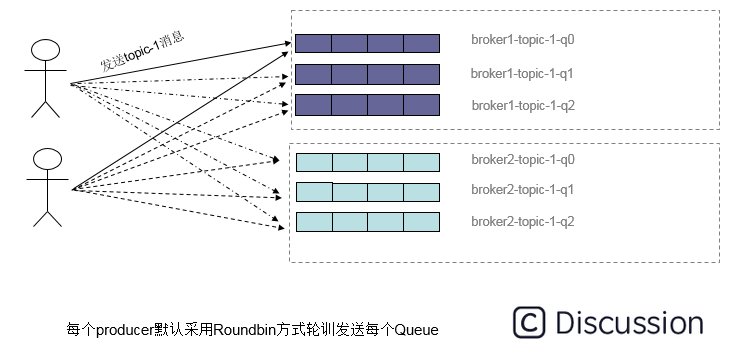
图中箭头线条上的标号代表顺序。
生产者1会把第1条消息发送至broker-1的topic-1下的messageQueue 0
生产者1会把第2条消息发送至broker-1的topic-1下的messageQueue 1
生产者1会把第3条消息发送至broker-1的topic-1下的messageQueue 2
生产者1会把第4条消息发送至broker-2的topic-1下的messageQueue 0
生产者1会把第5条消息发送至broker-2的topic-1下的messageQueue 1
生产者1会把第6条消息发送至broker-2的topic-1下的messageQueue 2
生产者2以此类推。
发送消息的容错策略在 MQFaultStrategy 这个类中定义。有一个 sendLatencyFaultEnable 开关变量,如果开启,在随机递增取模的基础上,再过滤掉 not available 的 Broker。所谓的"latencyFaultTolerance",是指对之前失败的,按一定的时间做退避。例如,如果上次请求的 latency 超过 550Lms,就退避 3000Lms;超过 1000L,就退避 60000L;如果关闭,采用随机递增取模的方式选择一个队列(MessageQueue)来发送消息。
latencyFaultTolerance 机制是实现消息发送高可用的核心关键所在。
1.3.3消费者消费消息负载均衡
RocketMQ有两种消费模式:BROADCASTING广播模式,CLUSTERING集群模式,默认的是集群消费模式。
因为广播模式所有的Consumer都会收到全量消息,所以RocketMQ的负载均衡只针对于Consumer集群消费的模式。
集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。
RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
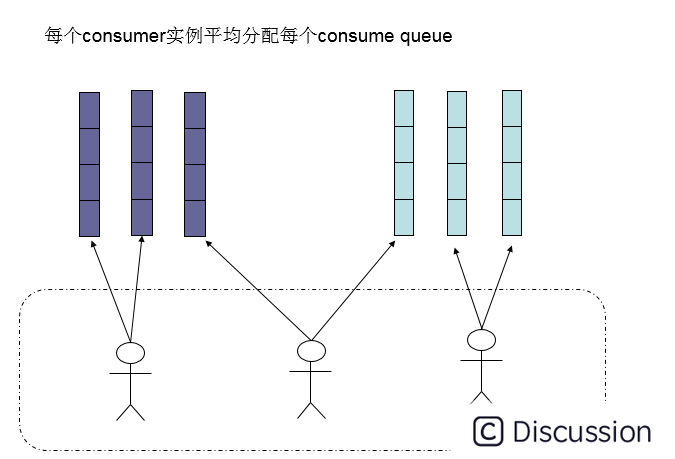
默认的分配算法是AllocateMessageQueueAveragely,如下图:
还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式,如下图:
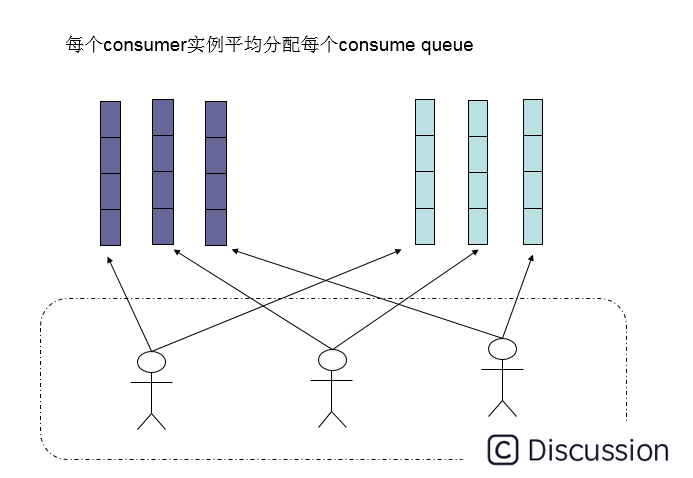
集群模式下,在一个消费组内,1个queue都是只允许分配给一个实例,这是由于如果多个实例同时消费一个queue的消息,由于拉取哪些消息是consumer主动控制的,那样会导致同一个消息在不同的实例下被消费多次。所以算法上都是1个queue只能分给1个consumer实例,但是1个consumer实例可以允许同时分到不同的queue。
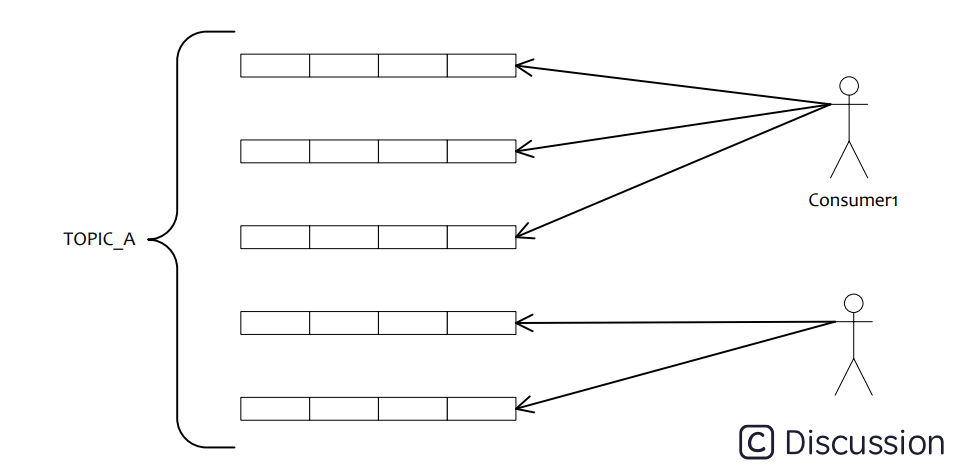
如图所示,如果有 5 个队列,2 个 consumer,那么第一个 Consumer 消费 3 个队列,第二 consumer 消费 2 个队列。 这样即可达到平均消费的目的,可以水平扩展 Consumer 来提高消费能力。
通过增加consumer实例去分摊queue的消费,可以起到水平扩展的消费能力的作用。
而有实例下线的时候,会重新触发负载均衡即rebalance,这时候原来分配到的queue将分配到其他实例上继续消费。
但是如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用了。
所以需要控制让queue的总数量大于等于consumer的数量。
这里扩展一下如何提高Consumer的消费并行度?
1.同一个Consumer Group下,通过增加Consumer实例数量来提高并行度,不过需要注意,超过订阅队列数的Consumer实例无效。可以通过加机器,或者在已有机器启动多个进程的方式。
2.提高单个 Consumer 的消费并行线程,通过修改设置 consumeThreadMin最小并发线程数和consumeThreadMax最大并发线程数来提高消费能力。
3.通过设置Consumer的consumeMessageBatchMaxSize这个参数,默认是1,即一次只消费一条消息,例如设置为N,那么每次消费的消息数小于等于N。这样即可大幅度提高消费的吞吐量。
适用场景&注意事项
消费端集群化部署,每条消息只需要被处理一次。
由于消费进度在服务端维护,可靠性更高。
集群消费模式下,每一条消息都只会被分发到一台机器上处理。如果需要被集群下的每一台机器都处理,请使用广播模式。
集群消费模式下,不保证每一次失败重投的消息路由到同一台机器上,因此处理消息时不应该做任何确定性假设。
广播模式
由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。
在实现上,其中一个不同就是在consumer分配queue的时候,所有consumer都分到所有的queue。
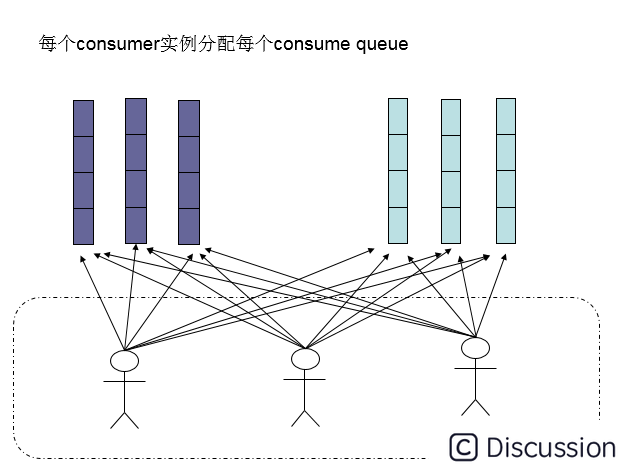
适用场景&注意事项
每条消息都需要被相同逻辑的多台机器处理。
消费进度在客户端维护,出现重复的概率稍大于集群模式。
广播模式下消息队列 RocketMQ保证每条消息至少被每台客户端消费一次,但是并不会对消费失败的消息进行失败重投,因此业务方需要关注消费失败的情况。
广播模式下,客户端每一次重启都会从最新消息消费。客户端在被停止期间发送至服务端的消息将会被自动跳过,请谨慎选择。
广播模式下,每条消息都会被大量的客户端重复处理,因此推荐尽可能使用集群模式。
目前仅 Java 客户端支持广播模式。
广播消费模式下不支持顺序消息。
广播消费模式下不支持重置消费位点。
广播模式下服务端不维护消费进度,所以消息队列 RocketMQ 控制台不支持消息堆积查询、消息堆积报警和订阅关系查询功能。
1.3.4队列重负载均衡:Rebalance
Rebalance概念
Rebalance即再均衡,指的是将⼀个Topic下的多个Queue在同⼀个Consumer Group中的多个 Consumer间进行重新分配的过程,它能够提升消息的并行消费能力。
触发Rebalance的场景
消费者所订阅Topic的队列数量发生变化
比如我们动态调整了Topic对应的队列数量,那么此时肯定是要重新分配一下,也就是触发Rebalance再均衡。例如⼀个Topic下5个队列,有2个消费者的情况下,那么就可以给其中⼀个消费者分配2个队列,给另⼀个分配3个队列;假设我们调整到Topic下有7个队列,还是2个消费者的情况下,那么就可以给其中⼀个消费者分配4个队列,给另⼀个分配3个队列;从而提升消息的并行消费能力。如下图:
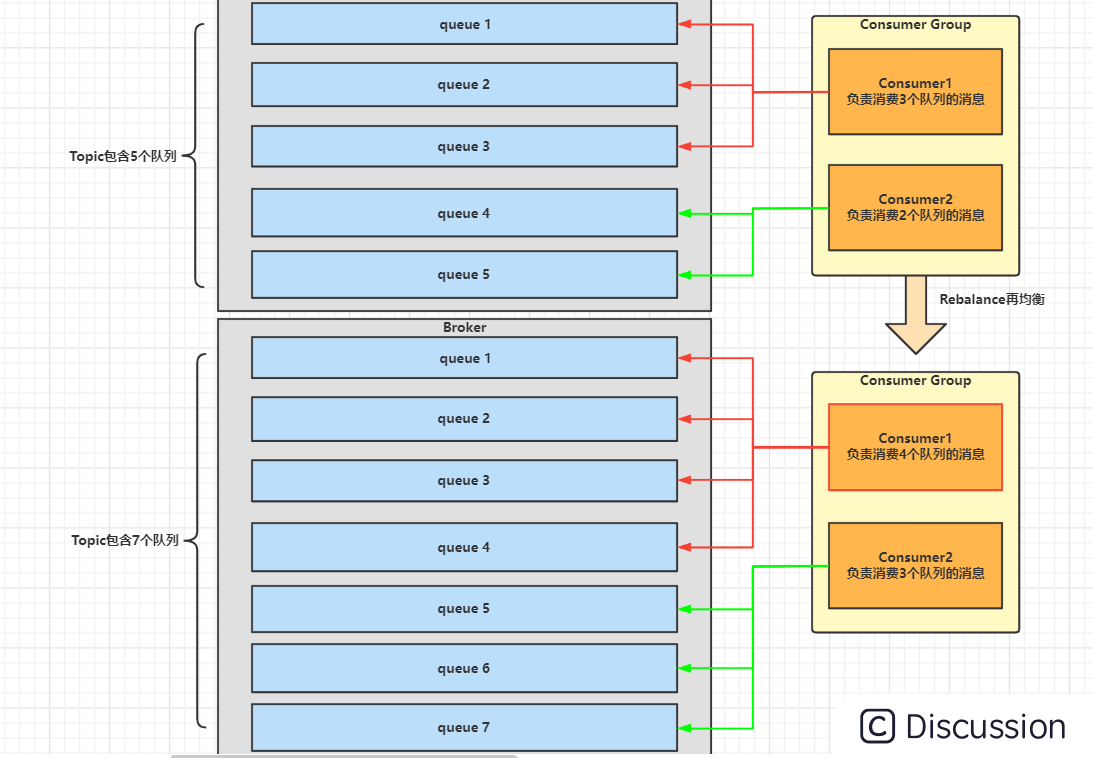
像Broker扩容或缩容、Broker与NameServer间发生网络异常、Queue扩容或缩容等场景都可能导致消费者所订阅Topic的队列数量发生变化。
消费者组中消费者的数量发生变化
比如我们动态添加了Consumer进行消费,那么此时肯定是要重新分配一下,也就是触发Rebalance再均衡。例如,⼀个Topic下5个队列,在只有1个消费者的情况下,这个消费者将负责消费这5个队列的消息。如果此时我们增加⼀个消费者,那么就可以给其中⼀个消费者分配2个队列,给另⼀个分配3个队列,从而提升消息的并行消费能力。 如下图:
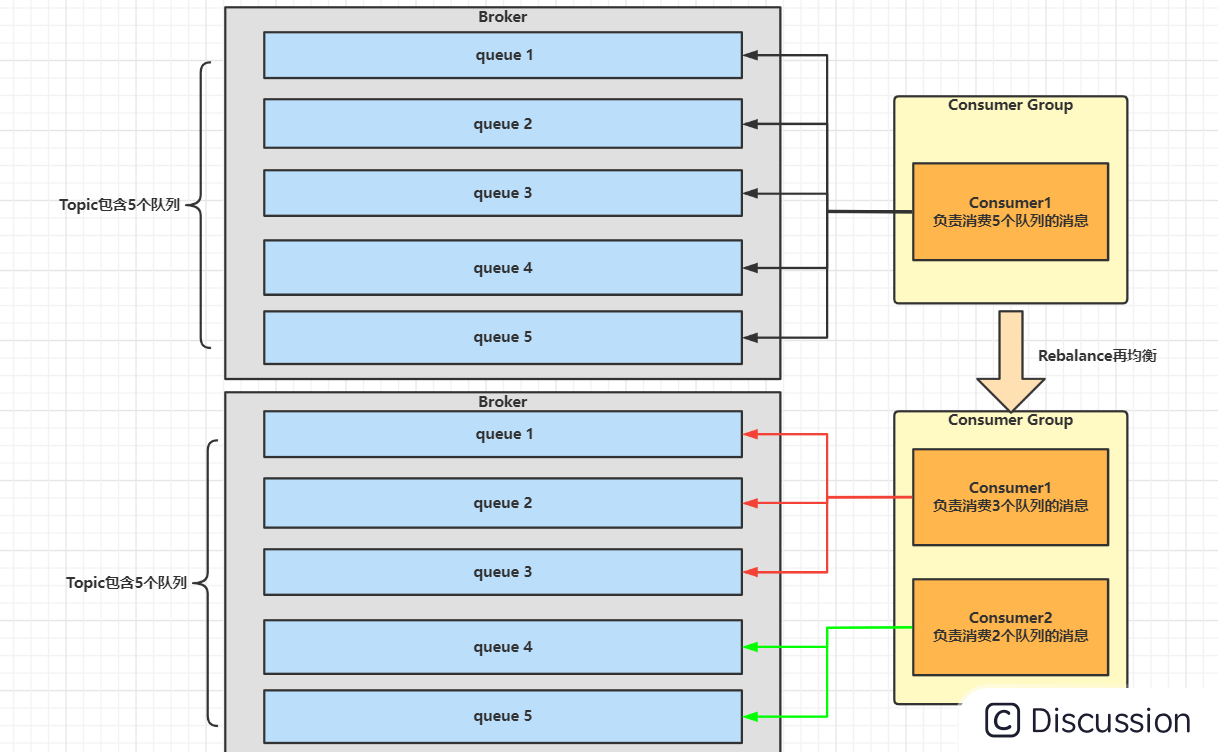
像Consumer Group扩容或缩容、Consumer与NameServer间发生网络异常、Consumer发生宕机等都会导致消费者组中消费者的数量发生变化。
需要注意的是,由于⼀个队列最多分配给⼀个消费者,因此当某个消费者组下的消费者实例数量大于队列的数量时, 多余的消费者实例将分配不到任何队列,等于是多余的消费者什么都不做,白白浪费。
Rebalance的危害
Rebalance的在提升消费能力的同时,也带来一些问题:
1.消费暂停
在只有一个Consumer时,其负责消费所有队列;在新增了一个Consumer后会触发 Rebalance的发生。此时原Consumer就需要暂停部分队列的消费,等到这些队列分配给新的Consumer后,这些暂停消费的队列才能继续被消费。
2.消费重复
Consumer在消费新分配给自己的队列时,必须接着之前Consumer 提交的消费进度的offset 继续消费。然而默认情况下,offset是异步提交的,这个异步性导致提交到Broker的offset与Consumer实际消费的消息并不一致。这个不一致的差值就是可能会重复消费的消息。
3.消费突刺
由于Rebalance可能导致重复消费,如果需要重复消费的消息过多,或者因为Rebalance暂停时间过长从而导致积压了部分消息。那么有可能会导致在Rebalance结束之后瞬间需要消费很多消息。
Reblance分配算法
一个Topic中的Queue只能由Consumer Group中的一个Consumer进行消费,而一个Consumer可以同时 消费多个Queue中的消息。那么Queue与Consumer间的配对关系是如何确定的,即Queue要分配给哪个Consumer进行消费,也是有算法策略的。常见的有四种策略,分别是:平均分配策略、环形平均策略、一致性hash策略、同机房策略。这些策略是通过在创建Consumer时的构造器传进去的。
平均分配策略(默认)
该算法是根据【avg = QueueCount / ConsumerCount 】的计算结果进行分配的,如果能够整除,则按顺序将avg个Queue逐个分配,如果不能整除,则将多余出的Queue按照Consumer顺序逐个分配。
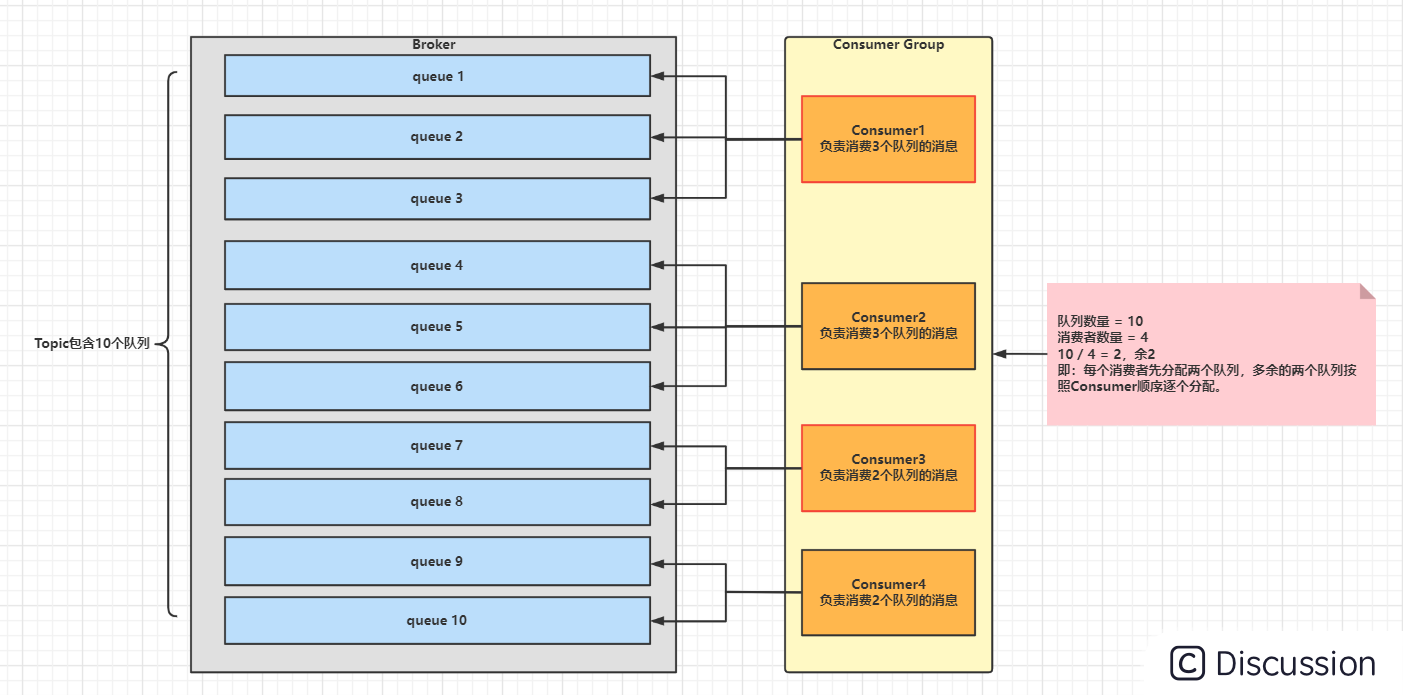
环形分配策略
环形平均算法是指,根据消费者的顺序,依次由Queue队列组成的环形图逐个分配,该方法不需要提前计算。如下图:
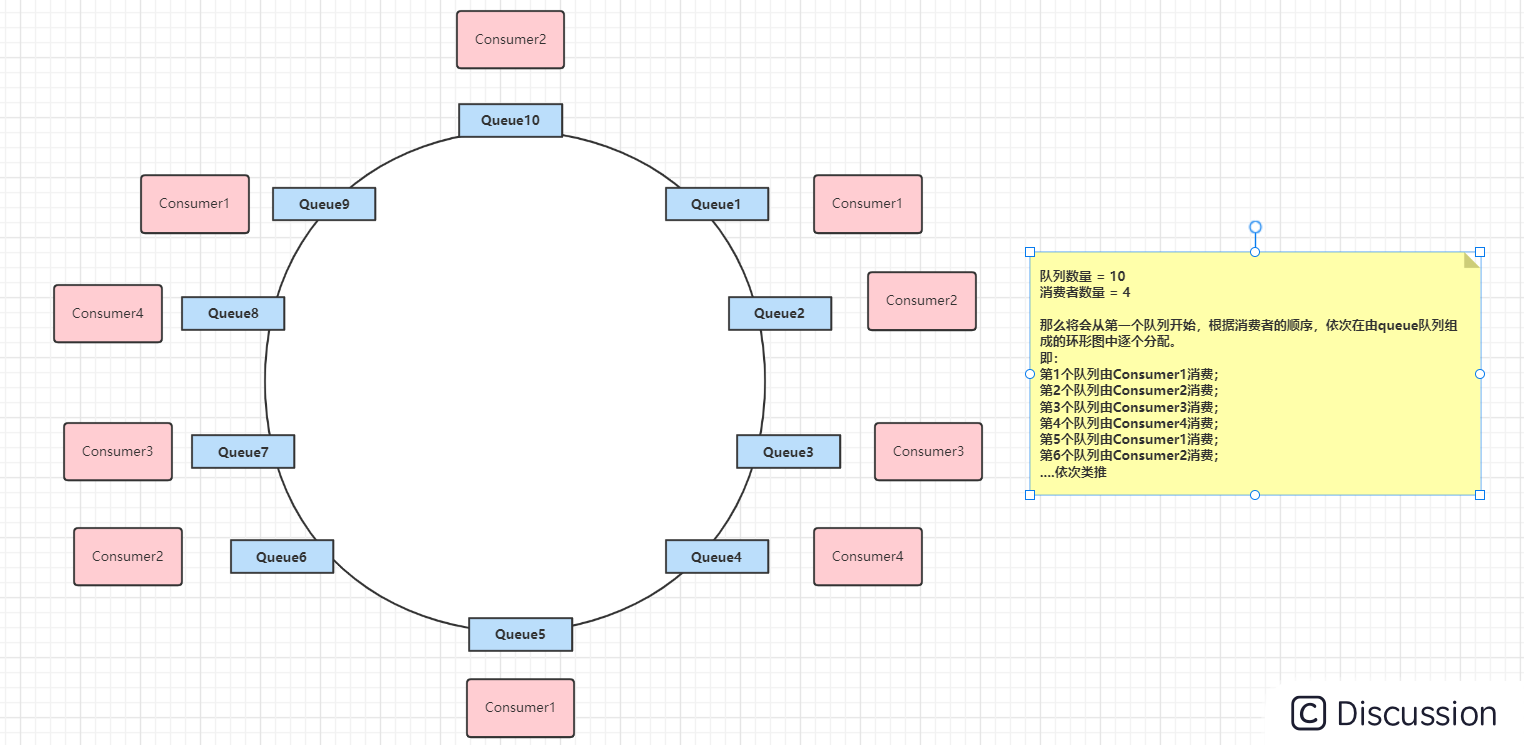
一致性哈希分配策略
该算法会将consumer的hash值作为Node节点存放到hash环上,然后将queue的hash值也放到hash环 上,通过顺时针方向,距离queue最近的那个consumer就是该queue要分配的consumer。
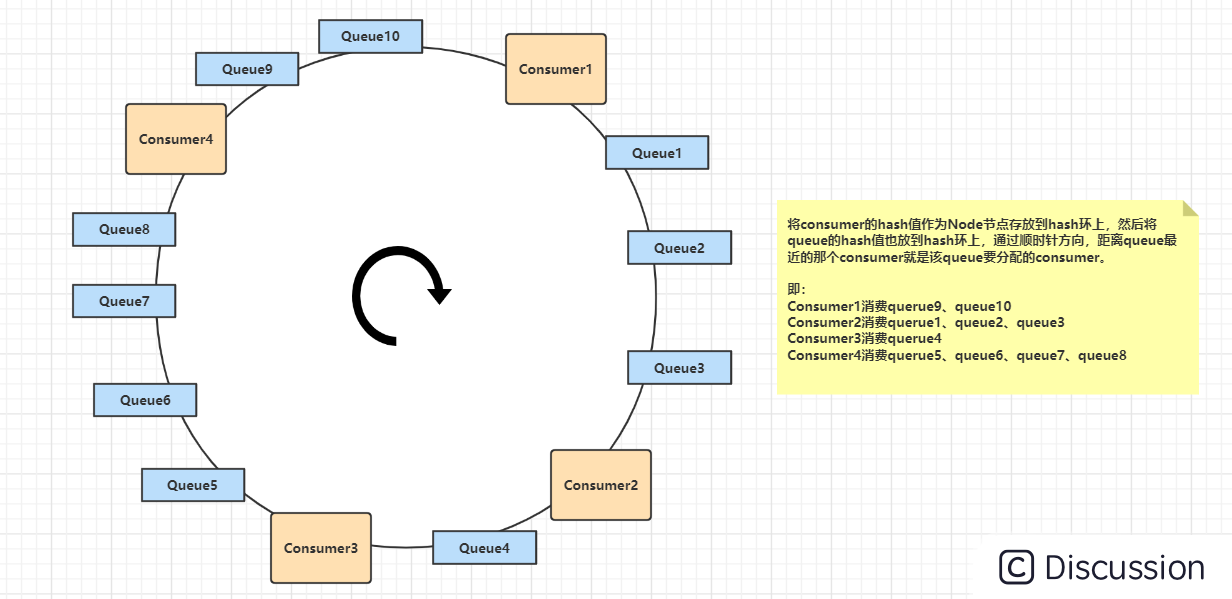
一致性哈希算法可以有效减少由于消费者组扩容或缩容所带来的大量的Rebalance,所以它适合用在Consumer数量变化较频繁的场景 。如下图:
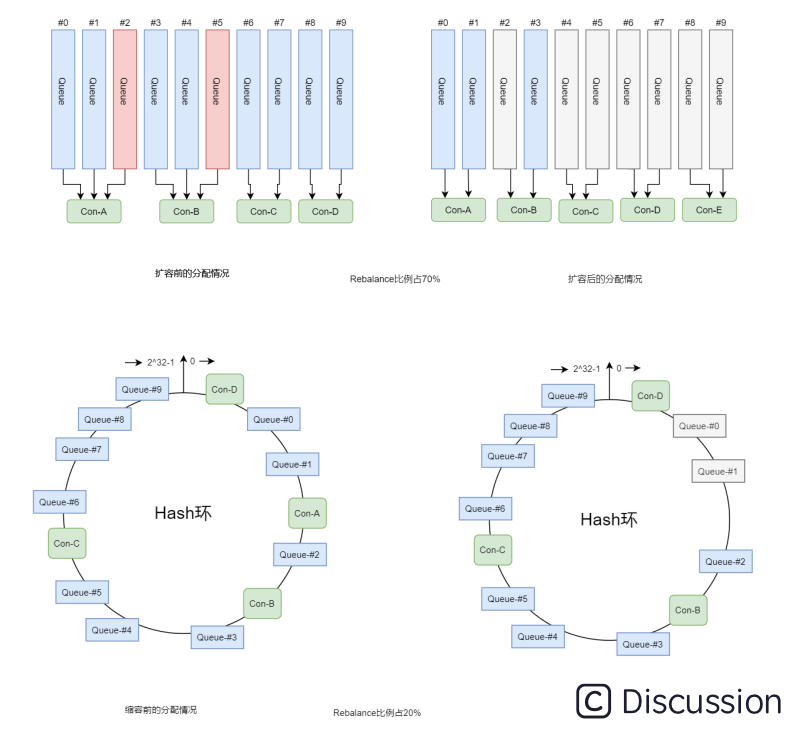
但是一致性哈希算法也存在不足,就是分配效率较低,容易导致分配不均的情况。即每个消费者消费的队列数,有可能相差很大,这样就会造成个别消费者压力过大。我们可以引入虚拟节点,让queue在hash环中尽可能分配均匀。
机房分配策略
该算法会根据queue的部署机房位置和consumer的位置,过滤出当前consumer相同机房的queue。然 后按照平均分配策略或环形平均策略对同机房queue进行分配。如果没有同机房queue,则按照平均 配策略或环形平均策略对所有queue进行分配。
如下图:

参考:https://blog.csdn.net/daobuxinzi/article/details/127501166
参考:https://blog.csdn.net/qq_45929882/article/details/124913163
一致性哈希:https://blog.csdn.net/a745233700/article/details/120814088