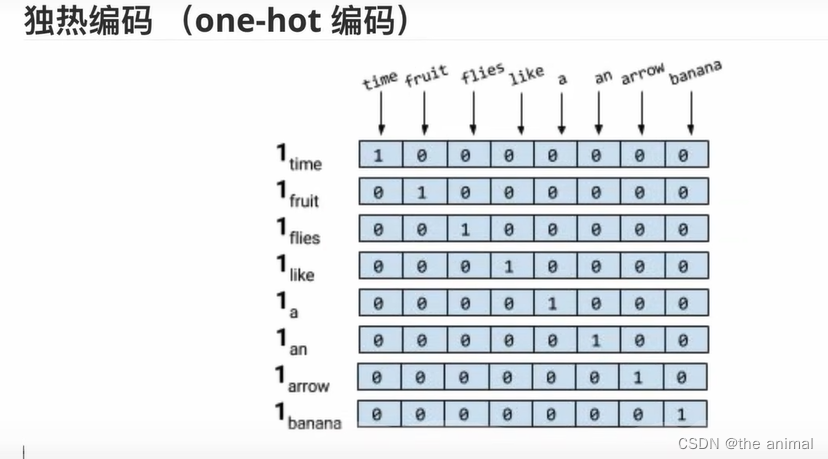
对于一个大小为N词典,给出一个N*N的矩阵。将这些词分别进行编码。再者,例如,香蕉与水果这两个词词意接近,我们引进余弦相似度来计算两者相似度。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似。而由于在独热编码中词与词之间余弦相似度均为0,就是词与词之间相似度为0,这是不合适的,所有又引入词向量。
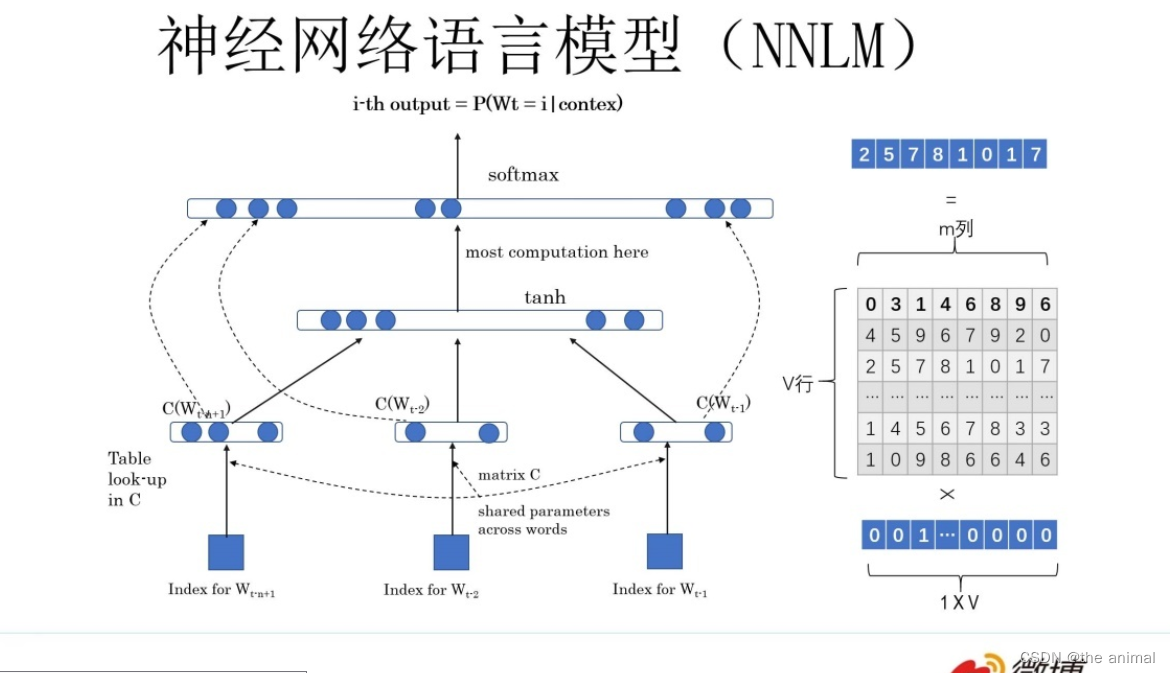 给定几个词,预测下一个词。上图所示有一个 V×m 的矩阵 Q,这个矩阵 Q 包含 V 行,V代表词典大小,每一行的内容代表对应单词的 Word Embedding 值。
给定几个词,预测下一个词。上图所示有一个 V×m 的矩阵 Q,这个矩阵 Q 包含 V 行,V代表词典大小,每一行的内容代表对应单词的 Word Embedding 值。
解释:神经网络语言模型的第一层,为输入层。首先将前 n−1 个单词用 Onehot 编码作为原始单词输入,之后乘以一个随机初始化的矩阵 Q 后获得词向量 C(wi)。神经网络语言模型的第二层,为隐层,包含 h 个隐变量,H 代表权重矩阵,因此隐层的输出为 Hx+d,其中 d 为偏置项。并且在此之后使用 tanh 作为激活函数。神经网络语言模型的第三层,为输出层,给出下一个词为该词的概率。随着多次学习,其中向量 C(wi)和权重Q会逐渐稳定,我们将C(Wi)作为该词的词向量。
例子·:给我任何一个词,判断” --》 独热编码w1 [1,0,0,0,0],w1*Q =c1 (“判断”这个词的词向量)。