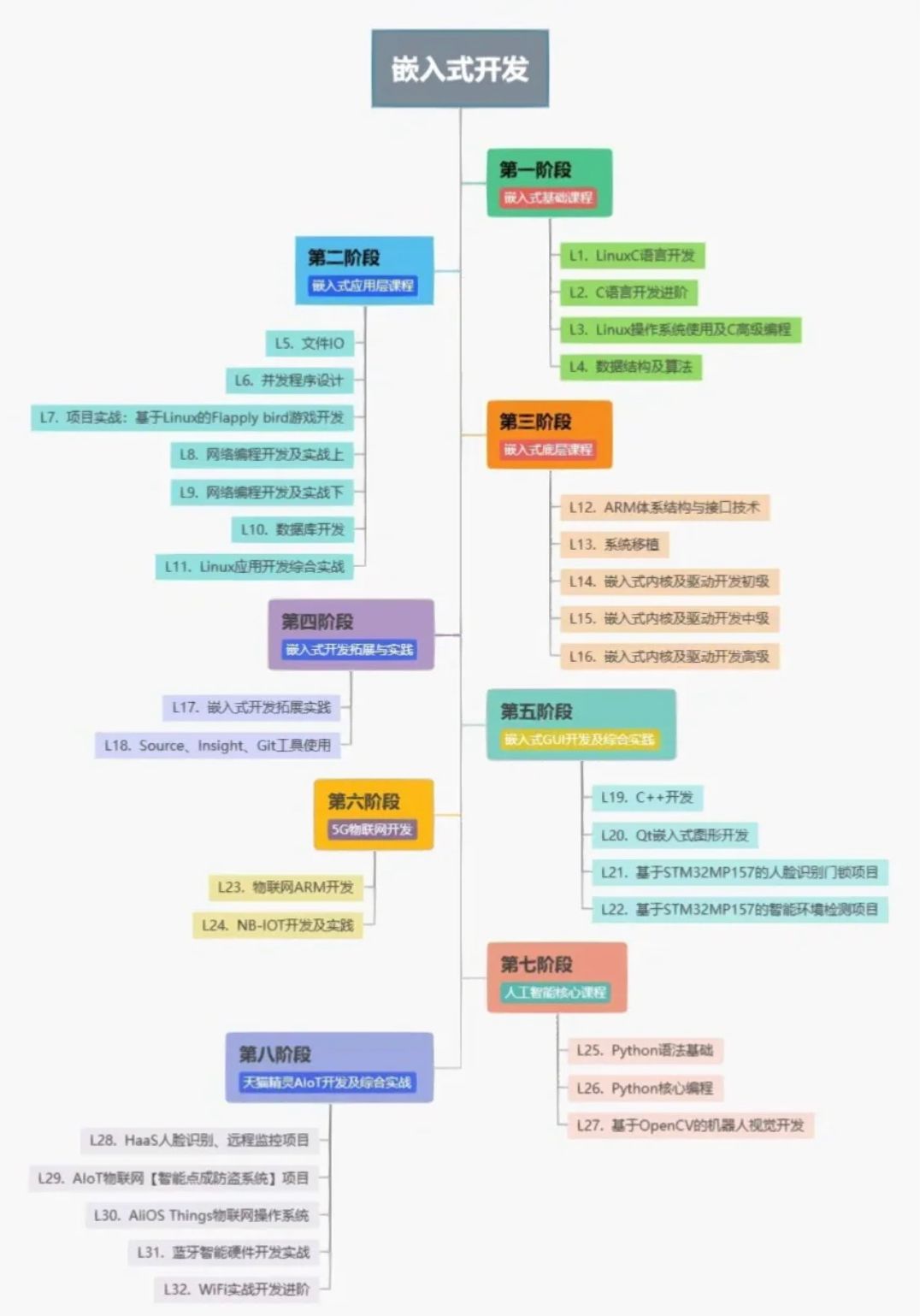
Python爬虫在许多情况下是非常有用的,爬虫可以帮助自动化地从互联网上获取大量数据。这些数据可以是产品信息、新闻文章、社交媒体内容、股票数据等通过爬虫可以减少人工收集和整理数据的工作量,提高效率。在软件开发中,可以使用爬虫来进行自动化的功能测试、性能测试或页面链接检查等。
正常做爬虫都是有一定的模板可借用,大体上分为几种。

要使用 Python 进行网络爬虫,可以遵循以下一般步骤:
1、安装 Python:确保已在计算机上安装 Python 解释器。
2、安装所需的库:常用的爬虫库包括 requests、BeautifulSoup 和 Scrapy。使用pip命令进行安装,例如 pip install requests。
3、导入所需的库:在 Python 脚本中导入所需的库。例如,import requests 和 from bs4 import BeautifulSoup。
4、发送 HTTP 请求:使用 requests 库发送 HTTP 请求以获取网页的内容。通过向网站的 URL 发送 GET 或 POST 请求来获取数据。
5、解析网页内容:使用 BeautifulSoup 库解析 HTML 或 XML 网页的内容。这使您能够从网页中提取所需的数据使用 BeautifulSoup 的查询语法选择器 (selector) 从解析后的网页内容中提取所需的数据。
6、处理数据:对提取的数据进行必要的处理和清洗,例如过滤无用的标签或格式化数据。
7、存储数据:将处理后的数据保存到文件、数据库或其他适当的存储介质中。
8、环迭代:如果需要爬取多个页面或进行持续抓取,可以使用循环迭代来处理不同的页面。
9、异常处理:考虑对网络请求和其他操作进行异常处理,以应对可能的错误情况。
请注意,在进行任何爬取活动之前,请确保您遵守网站的使用条款和法律要求,并尊重网站的 robots.txt 文件。另外,爬取速度应适度,以免给目标网站造成过大的负担。
Python爬虫简单代码
Python爬虫是指使用Python编写程序来自动获取互联网上的数据。下面是一个简单的示例,展示了如何使用Python进行基本的网络爬取:
import requests
from bs4 import BeautifulSoup
# 发送HTTP GET请求并获取页面内容
response = requests.get("https://example.com")
# 检查响应状态码
if response.status_code == 200:
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(response.content, "html.parser")
# 通过标签名称或选择器提取所需的数据
title = soup.title.text # 提取页面标题
# 打印提取的数据
print("页面标题:", title)
else:
print("请求失败")
这个示例中,我们使用requests库发送一个GET请求到https://example.com获取页面的内容,并使用BeautifulSoup库对页面进行解析。然后,我们提取页面的标题并将其打印出来。
当然,这只是一个非常简单的爬虫示例。实际上,你可以使用Python的爬虫库(如requests、BeautifulSoup)来处理不同的网页结构、处理JavaScript渲染的页面、配置HTTP请求头等。此外,你还需要了解如何处理表单提交、身份验证、分页、异常处理以及存储数据等更高级的爬虫技术。