istio熔断
熔断主要是无感的处理服务异常并保证不会发生级联甚至雪崩的服务异常。在微服务方面体现是对异常的服务情况进行快速失败,它对已经调用失败的服务不再会继续调用,如果仍需要调用此异常服务,它将立刻返回失败。
与此同时,它一直监控服务的健康状况,一旦服务恢复正常,则立刻恢复对此服务的正常访问。这样的快速失败策略可以降低服务负载压力,很好地保护服务免受高负载的影响。
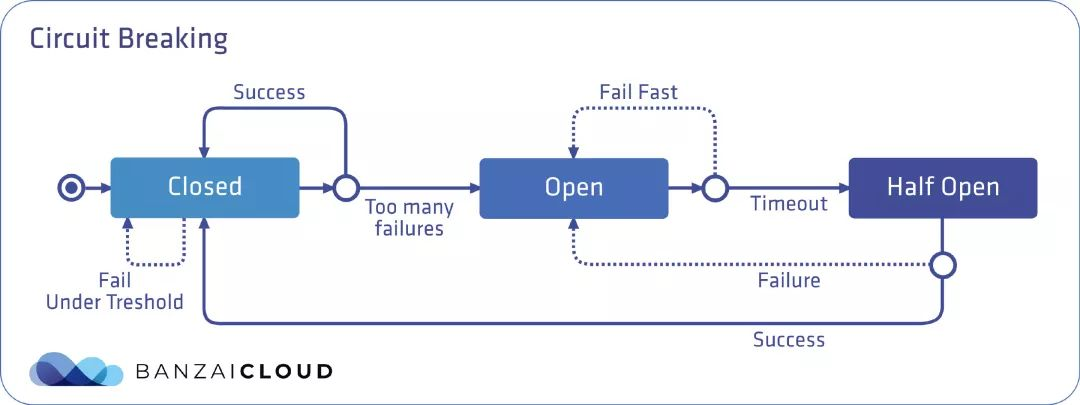
一个熔断器可以有三种状态:关闭、打开和半开,默认情况下处于关闭状态。在关闭状态下,无论请求成功或失败,到达预先设定的故障数量阈值前,都不会触发熔断。而当达到阈值时,熔断器就会打开。
当调用处于打开状态的服务时,熔断器将断开请求,这意味着它会直接返回一个错误,而不去执行调用。通过在客户端断开下游请求的方式,可以在生产环境中防止级联故障的发生。在经过事先配置的超时时长后,熔断器进入半开状态,这种状态下故障服务有时间从其中断的行为中恢复。如果请求在这种状态下继续失败,则熔断器将再次打开并继续阻断请求。否则熔断器将关闭,服务将被允许再次处理请求

连接池和异常处理就是配置熔断的一个用法了,

熔断就是我们生活当中所谓的跳闸,
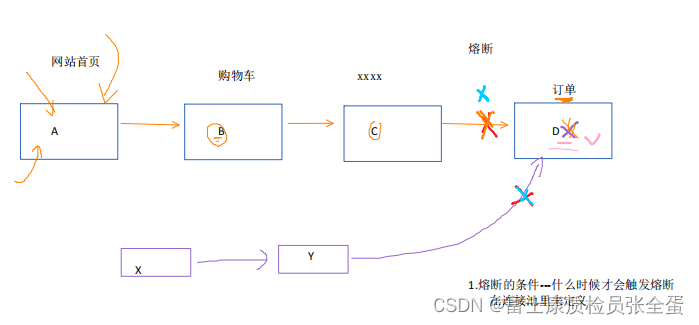
有一天对于d服务来说,负载压力比较大,可能还有其他应用也会调用到d服务。d服务如果出现问题可能是会影响到其他服务的,影响面比较广。
为了防止某一个服务问题带来的使得整个架构都出现问题,那么可以将某个应用切断,那么这样就将d服务隔离开来了。
一些概念
连接数:
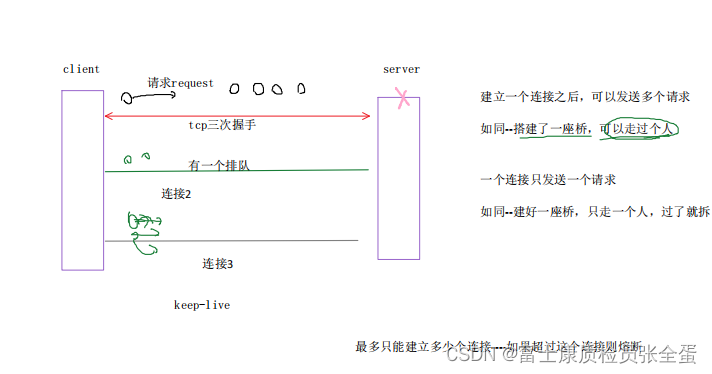
客户端向服务端发请求,需要建立TCP连接,那么建立TCP连接的数量就是连接数。
并发连接数(SBC):每秒建立的TCP连接数
请求数:(在同一个连接里面发送不同的请求)
客户端建立连接后,先服务端发送GET/POST/HEAD数据包,服务器返回结果两种情况:
1、http数据包头有close字段,关闭连接
2、http数据包头有keep-live字段,本次连接不关闭,可以下一次继续发送请求,减少TCP连接
并发请求数(QPS):每秒钟处理的请求数
熔断-连接池
熔断的定义是在DR里定义的,主要有2部分
trafficPolicy: 用于定义连接池
连接池的定义分成两类:
- TCP连接
maxConncections: 到目标主机的最大连接数
connectTimeOut: TCP连接超时,最小值必须要大于1ms
- http连接
http1MaxPendingReguests: 针对一个目标的HTTP请求最大排队数量,默认是1024
http2MaxRequests: 对一个后端的最大请求数
maxRequestsPerConnection:每个连接最多发送多少个请求
maxReties: 在给定的时间,集群所有主机最大重试数,默认值为3

连接池满了,但是可以有一个排队的,等待着处理。

一次性建立了5个连接,一共发送20个请求,
异常处理
outlierDetection:
用于定义熔断的条件,达到什么条件就开始熔断
consecutiveGatewayErrors: 1 连续错误几次开始熔断,该实例会被踢掉(从连接池里面踢掉,那么就不会往里面去进行转发了)
interval:驱逐检查的时间间隔(驱逐检测的统计时间),默认为10秒
baseEjectionTime指定来一个实例被踢掉之后,最少多长时间之后加回来,如果连续触发熔断,熔
断的时长会乘以相应的倍数,时间默认为30秒
一个服务被驱逐的时间等于驱逐次数乘以最小驱逐时间,所以被驱逐的实例再被再次驱逐时会变得
越来越长
maxEjectionPercent:服务的可驱逐故障实例的最大比例,默认为10%。官方不建议配置过高,过
分的驱逐会影响服务的服务能力
minHealthPercent:最小健康比例,当负载的实例中,如果健康的实例数量低于这个比例,istio
会进入恐慌模式,异常检查功能会被禁用,所有的服务不论是否是故障实例都可以接受请求。(有效的机器不能低于这个值,低于这个值,熔断就不再生效了)
后端的某一个pod被熔断了,它不再对外提供服务了,希望在过一段时间是可以启动起来的。
这个时候就需要去配置异常处理,