【半监督图像分类 2022 CVPR 】Semi-ViT
论文题目:Semi-supervised Vision Transformers at Scale
中文题目:
论文链接:https://arxiv.org/abs/2208.05688
论文代码:https://github.com/amazon-science/semi-vit
发表时间:2022年8月
论文团队:亚马逊人工智能实验室
教学视频:https://www.bilibili.com/video/BV1CN4y1w7hU
摘要
我们研究了视觉Transformer(VIT)的半监督学习(SSL)。尽管VIT体系结构在不同的任务中得到了广泛的应用,但这是一个尚未被深入研究的课题。 为了解决这个问题,我们提出了一种新的SSL流水线,它首先由非/自监督的预训练,然后是监督的微调,最后是半监督的微调组成。 在半监督微调阶段,我们采用指数移动平均(EMA)-教师框架来代替流行的FixMatch,因为前者对半监督Transformer来说更稳定,提供更高的精度。 此外,我们提出了一种概率伪混淆机制来内插未标记样本及其伪标记以改进正则化,这对于训练具有弱诱导偏差的VITs很重要。 我们提出的方法,称为半VIT,在半监督分类设置中取得了与CNN对应的相当或更好的性能。 Semi-VIT还享有VITS的可伸缩性优势,可以很容易地按比例扩展到大尺寸模型,并且精确度越来越高。 例如,Semivit-HUGE仅使用1%的标签就在ImageNet上实现了令人印象深刻的80%的Top-1准确率,这与使用100%ImageNet标签的Inception-V4相当。
1. 介绍
在过去的几年里,视觉Transformer(VIT)[18]在监督学习[59,41,69]、非/自监督学习[16,12,24]和许多其他计算机视觉任务[11,19,1,54](结构修改)方面取得了显著的进展。 然而,VITS在半监督学习(SSL)中还没有表现出同样的优势,在SSL中只有一小部分训练数据被标记,这是一个介于监督和非/自监督学习之间的问题。 尽管SSL中最近的几种方法已经显著地推进了这一领域[37,58,7,51,66,10,49],但这些方法从卷积神经网络(CNN)到VIT体系结构的转移还没有显示出太大的希望。 对于top-1精确度top-1精确度imageNet top-1精确度semi-vit-h resnet-152 inception-v4 swin-b convnext-l效率net-l2 semi-vit-h arxiv:2208.05688 v1[cs.cv]2022年8月11日示例,如[64]中所讨论的,直接将fixmatch[51](最流行的SSL方法之一)应用于vit导致比使用CNN架构时性能更差(约差10分)。 这一挑战可能是由于VITs需要更多的数据进行训练,并且比CNNs具有更弱的归纳偏差[18]。 然而,在本文中,我们证明了半监督VITs在适当训练时可以优于CNN对应的VITs,这表明有希望将SSL提升到超越CNN体系结构的水平。
为了获得这样的成功,我们提出了以下SSL管道:
1)对所有数据(包括标记和未标记)进行非/自监督预训练,
然后是2)只对标记数据进行监督微调,
最后是3)对所有数据进行半监督微调。
在我们的实验中,当训练VITs用于SSL时,这种新的管道是稳定的,并有助于降低超参数调整的敏感性。
在半监督微调的最后阶段,我们采用EMA-Teacher框架[58,10],这是对流行的FixMatch[51]的改进版本。
与FixMatch在训练半监督VIT时常常不能收敛不同,EMA-Teacher表现出更稳定的训练行为和更好的性能。
此外,我们提出了基于伪标记的SSL方法的概率伪混淆,该方法将未标记的样本与伪标记耦合进行插值,以增强正则化。
在标准混合[71]中,混合比率从β分布随机取样。
相反,在概率伪混合中,该比率取决于两个混合样本各自的置信度,因此置信度高的样本在最终插值样本中的权重更大。
这种新的数据增强技术带来了不可忽略的收益,因为VIT具有较弱的归纳偏差,特别是对于训练更加困难的场景,例如,没有非/自监督的预训练,或者在带有很少标记样本(例如,1%标签)的数据制度上。
我们称我们的方法为半VIT。 请注意,Semi-VIT构建在完全相同的VITS设计上(即,既没有额外的参数,也没有架构更改)。
Semi-VIT从不同方面实现了有希望的结果(图1)。
- 在SSL1上,我们首次发现纯VITS可以达到与CNNS相当或更好的精度。
- 在SSL设置下,半VIT可以很容易地放大。 这在图1(a)和(b)中说明了不同规模的VIT架构,从VIT小到VIT大,半VIT优于现有技术,如SIMCLRV2[15]。
- Semi-VIT显示出显著降低标记成本的潜力。例如,如图1©所示,具有1%(10%)ImageNet标签的Semi-VIT-HUGE实现了与全监督Inception-V4,convnext-L相当的性能。 这意味着人类注释成本减少了100×(10×)。
- Semi-VIT在ImageNet上达到了最先进的SSL结果,例如,仅用1%(10%)的标签就达到了80.0%(84.3%)Top-1的准确率。 此外,Semi-VIT对性能的大幅提升并不是孤立于ImageNet之上的:我们发现,对于其他数据集,包括Food-101[9]、Inaturalist[28]和GoogleLandMark[48],与监督微调基线相比,使用1%(10%)标签的Top-1精度提高了13%-21%(7%-10%)。

图1:(a)和(b)是在不同的模型尺度下我们的半VIT与最先进的SSL算法的比较,©是与最先进的监督模型的比较。
2. 半监督Transformer
2.1 Pipeline
文献中存在一些半监督学习的管道。 例如:1)使用SSL技术直接从头开始训练模型,例如FixMatch[51]; 2)先对模型进行非/自监督预训练,然后对标记数据进行优化[25,14,22]; 3)先对模型进行自监督预训练,然后对标记数据和未标记数据进行半监督优化[10]。 在本文中,我们提出了以下流程:首先,在不使用任何标签的情况下,对所有数据进行可选的自监督预训练; 其次,对已有的标注数据进行标准监督微调; 最后,对标记数据和未标记数据进行半监督微调。 这个过程类似于[15],不同的是他们在最后阶段使用知识蒸馏[27]。 我们发现,该训练管道可以稳定地训练半监督视觉Transformer,并且在可能较少的超参数调整情况下取得了很好的效果。
2.2 EMA-Teacher Framework
FixMatch[51]在过去几年中作为一种流行的SSL方法出现。 正如[10]中所讨论的,它可以被解释为一个学生-教师框架,其中学生和教师模型是相同的,如图2(a)所示。 然而,FixMatch有意想不到的行为,特别是当模型包含批规范化(BN)时[33]。 尽管VIT使用层归一化(LN)[4]代替BN作为归一化,但我们仍然发现VIT的FixMatch性能低于CNN的同类,并且经常不收敛。 在[64]中也观察到了这种现象。 一个潜在的原因是FixMatch中的学生模型和教师模型是相同的,这很容易导致模型崩溃[25,22]。 正如文[10]所建议的,EMA-meacher(如图2(b)所示)是FixMatch的一个改进版本,因此我们采用它作为我们的半监督VIT。 在EMA-Teacher框架中,教师参数θ由学生参数θ通过指数移动平均(EMA)更新,
θ
′
=
m
θ
′
+
(
1
−
m
)
θ
\theta^\prime=m\theta^\prime+(1-m)\theta
θ′=mθ′+(1−m)θ
其中动量衰减
m
m
m是一个接近1的数字,例如0.9999。 学生参数通过标准学习优化来更新,例如SGD或ADAMW[43]。 其他组件与FixMatch完全相同,如图2所示。 这种时间加权平均可以稳定训练轨迹[3,34]并避免模型崩溃问题[25,22]。 实验还表明,在训练Semi-ViT时,该EMA-Teacher框架比FixMatch具有更好的训练效果和更稳定的训练行为。
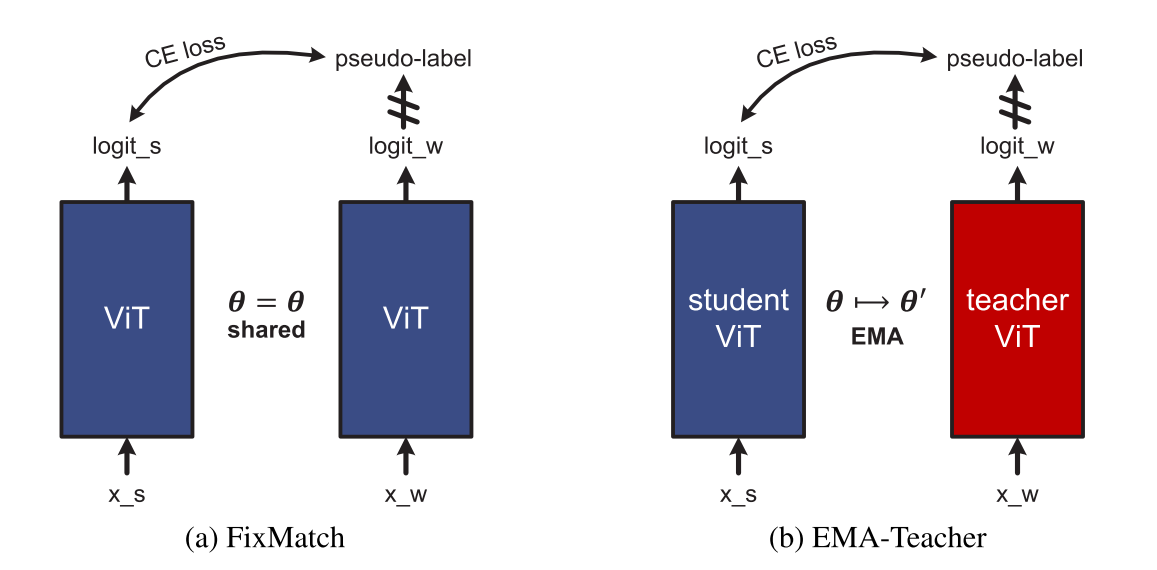
图2:FixMatch(A)和EMA-Teacher(B)的框架比较。 xs/xw是样本x的强/弱增广视图,θ是模型参数。
2.3 半监督学习公式
在EMA-Teacher框架中,在训练过程中,一个minibatch中既有标记样本,也有未标记样本。 标记样品上的损失 { ( x i l , y i l } i = 1 N l \{(x_i^l,y_i^l\}_{i=1}^{N_l} {(xil,yil}i=1Nl是标准的交叉熵损失, L l = 1 N i ∑ i = 1 N l C E ( x i l , y i l ) \mathcal{L}_l=\frac{1}{N_i}\sum_{i=1}^{N_l}CE(x_i^l,y_i^l) Ll=Ni1∑i=1NlCE(xil,yil)。
对于未标记样本
x
u
∈
{
x
i
u
}
i
=
1
N
u
x^u\in\{x_i^u\}_{i=1}^{N_u}
xu∈{xiu}i=1Nu,对其进行弱增广和强增广,分别生成
x
u
,
w
x^{u,w}
xu,w和
x
u
,
s
x^{u,s}
xu,s。 弱增广的
x
u
,
w
x^{u,w}
xu,w通过教师网络转发,并输出类上的概率,
p
=
f
(
x
u
,
w
;
θ
′
)
p=f(x^{u,w};\theta^\prime)
p=f(xu,w;θ′)。 然后由
y
^
=
arg
max
c
p
c
\hat{y}=\arg \max_cp_c
y^=argmaxcpc产生伪标记,其相关置信度为
p
=
max
p
c
p=\max p_c
p=maxpc。 然后使用置信度高于置信度阈值τ的伪标签来监督学生在强增广样本
x
u
,
s
x^{u,s}
xu,s上的学习,
L
u
=
1
N
u
∑
i
=
1
N
u
[
o
i
≥
τ
]
C
E
(
x
i
u
,
s
,
y
^
i
)
\mathcal{L}_u=\frac{1}{N_u}\sum_{i=1}^{N_u}[o_i\ge \tau]CE(x_i^{u,s},\hat{y}_i)
Lu=Nu1i=1∑Nu[oi≥τ]CE(xiu,s,y^i)
其中[·]是指示函数。 总损耗为
L
=
L
l
+
μ
L
u
\mathcal{L}=\mathcal{L}_l+\mu\mathcal{L}_u
L=Ll+μLu,其中
μ
\mu
μ为权衡权重。 注意,只有置信度高于阈值的伪标签才会导致最终损失; 其他的都没有使用。 这种过滤背后的原理是,低置信度的伪标签噪音更大,可能会劫持SSL训练。
3 概率伪混和

图3:未标记数据上的不同混搭变体。 红色样本是通过置信度阈值的样本,而不是蓝色样本。
3.1 Mixup
Mixup[71]执行对样本及其标签的凸组合,
x
^
=
λ
x
i
+
(
1
−
λ
)
x
j
y
^
=
λ
y
i
+
(
1
−
λ
)
y
j
\hat{x}=\lambda x_i+(1-\lambda)x_j \\ \hat{y}=\lambda y_i+(1-\lambda)y_j
x^=λxi+(1−λ)xjy^=λyi+(1−λ)yj
其中,
α
∈
(
0
,
∞
)
\alpha \in (0,\infty)
α∈(0,∞)的混合比
λ
∼
B
e
t
a
(
α
,
α
)
∈
[
0
,
1
]
\lambda \sim Beta(\alpha,\alpha)\in [0,1]
λ∼Beta(α,α)∈[0,1]。 在训练过程中,样本通常被混合在一个小批中。 给定一个minibatch b和它的洗牌版本b,混合的minibatch是~b=λb+(1-λ)b,其中λ可以是批处理式的,也可以是元素式的。 由于弱电感偏差的性质,VIT比CNN更需要数据,因此有效的数据增强(如混杂)对于训练全监督VIT是至关重要的[18,59,41,69]。 这也适用于Semivit,因为它继承了VIT的弱电感偏置的性质。 虽然在监督学习中使用MIXUP是标准的,但如何在基于伪标记的SSL框架(如EMA-TESTEAR)下使用MIXUP还不清楚,我们将在下面讨论它。
3.2 伪混合
在基于伪标记的SSL框架[38,51,49,10]下,给定一个未标记样本及其伪标记 ( x u , y ^ ) (x^u,\hat{y}) (xu,y^),只有当其置信度O不小于置信度阈值 τ \tau τ时,才会导致损失 L u \mathcal{L}_u Lu,如(2)所示。
根据它们的置信度得分,未标记的小批量 B u {\mathcal{B}}^{u} Bu可以被分组为一个干净子集 B ^ u = { ( x i u , y i ^ ) ∣ o i ≥ τ } \hat{B}^u=\{(x_i^u,\hat{y_i})|o_i\ge \tau\} B^u={(xiu,yi^)∣oi≥τ}和一个噪声子集 B ˙ u = B u − B ^ u \dot{B}^u=B^u-\hat{B}^u B˙u=Bu−B^u。 一个简单的解决方案是在完整的未标记的Minibatch BU上应用混合,在干净的和噪声的样品之间没有区别,称为伪混合,如图3(a)所示。 伪混合后,仍然只有 B u \mathcal{B}^u Bu中的样本对损失有贡献,而B u中的样本被抛弃。 这样,混搭操作就不仅仅是数据扩充了。 事实上,如果将 B ˙ u \dot{B}^u B˙u中的样本与 B ^ u \hat{\mathcal{B}}^u B^u中的样本混在一起,也会导致最终的损失。 因此,由于随机性,它可能会在损失计算中涉及大量的噪声样本,然而,这违背了伪标记的哲学。 由于只有干净的子集 B ^ u \hat{\mathcal{B}}^u B^u会导致最终损耗,另一种选择是只对 B ^ u \hat{B}^u B^u使用mixup,表示为 p s e u d o m i x u p + pseudo\ mixup+ pseudo mixup+,如图3(b)所示。 这样,噪声子集 B ˙ u \dot{B}^u B˙u中的任何样本都不会影响训练。
3.3 Probabilistic Pseudo Mixup
尽管
B
˙
u
\dot{B}^u
B˙u中的样本存在噪声,但它们仍然携带了一些有用的信息供模型学习。 上面的伪混合可以通过混合噪声和干净的伪样本在一起以某种方式利用这些信息。 然而,问题是混合比是随机产生的一个贝塔分布,它不依赖于每个样本的置信度。 这并不理想。 例如,当两个样本混合时,置信度较高的样本应该有较高的混合比,这样它在最终损失中的分量就更大。 基于这种直觉,我们提出了概率伪混合(图3©),其中混合比λ关系到样本的可信度
λ
i
=
o
i
/
(
o
i
+
o
j
)
\lambda_i=o_i/(o_i+o_j)
λi=oi/(oi+oj)
同时,在混合操作后,将
x
i
u
x_{i}^{u}
xiu的置信度得分更新为
o
i
∗
=
max
(
o
i
,
o
j
)
o_i^*=\max(o_i,o_j)
oi∗=max(oi,oj)
因为置信度得分应该与大多数图像内容对齐。 且最终清洁子集
B
~
u
=
{
(
x
~
i
u
,
y
~
i
u
)
∣
o
i
∗
≥
τ
}
\tilde{\mathcal{B}}^u=\{(\tilde{x}_i^u,\tilde{y}_i^u)|o_i^*\geq\tau\}
B~u={(x~iu,y~iu)∣oi∗≥τ}将促成最终损失。 使用这种概率伪混合可以增强正则化,利用来自所有样本的信息,即使是有噪声的样本,同时也不会违反伪标记的哲学。 实验结果表明,该方法可以有效地缓解半VIT的弱归纳偏置问题,并带来较大的增益。
4. 实验
本文提出了一种基于半监督学习的视觉变换器半VIT算法。 这是第一次纯视觉变形金刚能够在半监督学习上取得有希望的结果,甚至大大超过了以前最好的基于CNN的同行。 此外,半VIT继承了VIT的可扩展性优点,较大的模型导致与全监督上界的差距较小。 这是半监督学习的一个很有前途的方向。 Semi-VIT的优点可以很好地推广到其他数据集,暗示潜在的更广泛的影响。 我们希望这些有希望的结果能鼓励更多的半监督视觉变形金刚的努力。
![数据结构07:查找[C++][平衡二叉排序树AVL]](https://img-blog.csdnimg.cn/f2849f7100a94375a7a3c73ee59ec32b.png)







![【群智能算法改进】基于二次插值策略的改进白鲸优化算法 改进后的EBWO[3]算法【Matlab代码#44】](https://img-blog.csdnimg.cn/de0816c6270f406bbdfd5a1cc1185602.png#pic_center)


