论文:https://arxiv.org/pdf/2304.10592v1.pdf
代码:https://github.com/vision-cair/minigpt-4
一. 作者动机
GPT-4展示了非凡的多模态能力,比如直接从手写文本生成网站,以及识别图像中的幽默元素。这些特性在以前的视觉语言模型中很少见。我们认为GPT-4具有先进的多模态生成能力的主要原因在于利用了更先进的大型语言模型(LLM)。然而,大语言模型和视觉模型训练起来比较消耗资源,作者提出了MiniGPT-4,它将一个冻结的视觉编码器与一个冻结的LLM(Vicuna)对齐,仅训练一个投影层,达到类似GPT-4的效果。
二. 算法架构
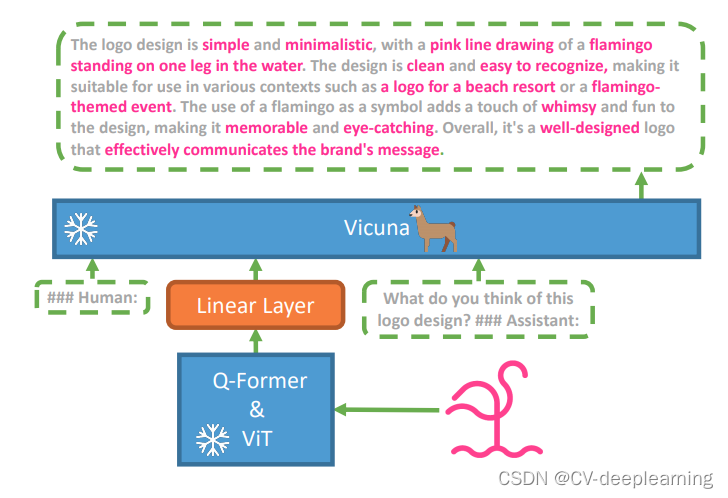
图1 大型语言模型的结构示意图:MiniGPT-4由一个具有预训练ViT和Q-Former的视觉编码器、一个线性投影层和一个高级Vicuna大型语言模型组成。MiniGPT-4只需要训练线性投影层,将视觉特征与Vicuna对齐。
三. 训练细节
- 预训练阶段
在初始的预训练阶段,模型旨在从大量对齐的图像文本对中获取视觉语言知识。我们将从注入的投影层输出的结果视为LLM的软提示,促使其生成相应的真实文本。 - 微调阶段
使用筛选出的高质量图像文本对对预训练模型进行微调。在微调过程中,我们使用以下模板中预定义的提示语:

在这个提示语中, 表示从我们预定义的指令集中随机抽取的指令,包括“详细描述这张图片”或“能否为我描述一下这张图片的内容”等不同形式的指令。需要注意的是,我们不会针对这个特定的文本-图像提示计算回归损失。
四. 论文点评
训练大模型很耗资源,而作者整个训练过程需要约10小时,利用4个A100(80GB)GPU完成。这样给普通人或者研究者提供了方向,降低了训练门槛。
阅读推荐:https://zhuanlan.zhihu.com/p/626206324