文章目录
- 一、二叉搜索树的概念
- 二、二叉搜索树的实现
- 2.1 插入
- 迭代插入
- 递归插入
- 2.2 查找
- 迭代查找
- 递归查找
- 2.3 删除
- 迭代删除
- 递归删除
- 2.4 中序遍历
- 三、二叉搜索树的应用
- 1、K模型
- 2、KV模型
- 四、二叉树的性能分析
一、二叉搜索树的概念
二叉搜索树又叫做二叉排序树。
- 左子树的结点值都小于根
- 右子树的结点值都大于根
- 左右子树分别是二叉搜索树
因为在二叉搜索树中,每个结点左子树上所有结点的值都小于该结点的值,右子树上所有结点的值都大于该结点的值,因此对二叉搜索树进行中序遍历后,得到的是升序序列。
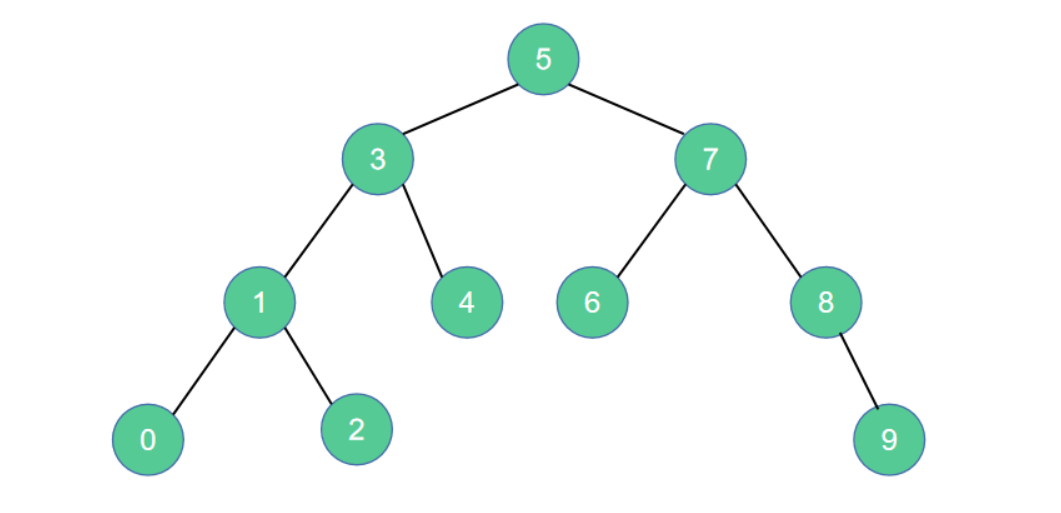
二、二叉搜索树的实现
2.1 插入
迭代插入
思想:插入数据仍然保持它是搜索二叉树
为什么要有返回值呢?
因为搜索二叉树要减少数据的冗余,遇到重复的数字是插入不了的
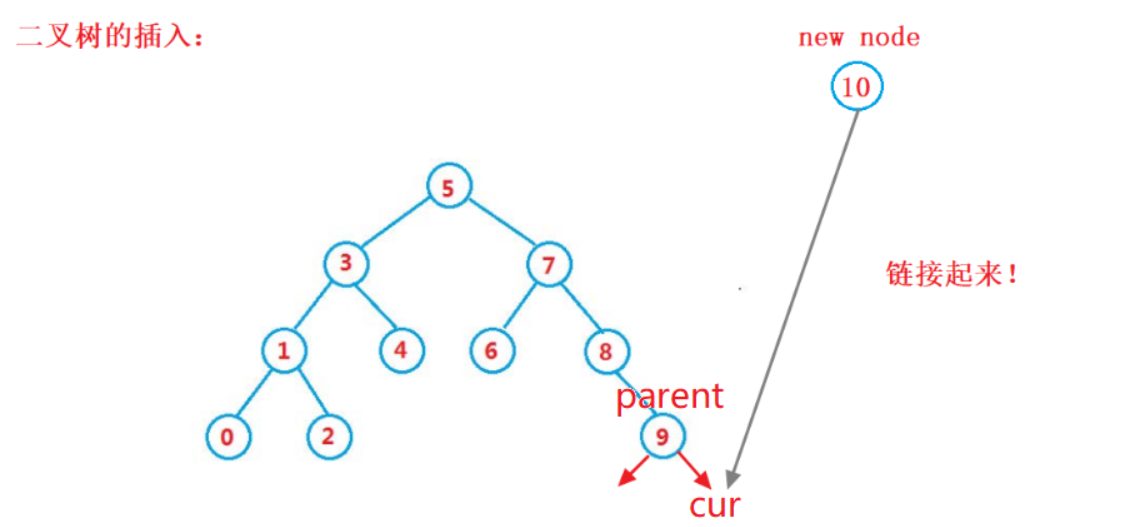
图解:
所以我们在插入过程中必须要记录一下上一个结点的位置,然后再迭代着往后走,不然我们是无法链接起来的。
// 插入数据保持继续是二叉搜索树
bool Insert(const K& key)
{
//如果是空树,直接插入即可
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
// 往右边走
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
// 往左边走
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
// _key==key
else
{
return false;
}
}
// 这里说明走到合适的空位置了,需要链接起来,
//但是还是要判断要插入的数比parent大还是小,这决定插在哪边
cur = new Node(key);
if (key > parent->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
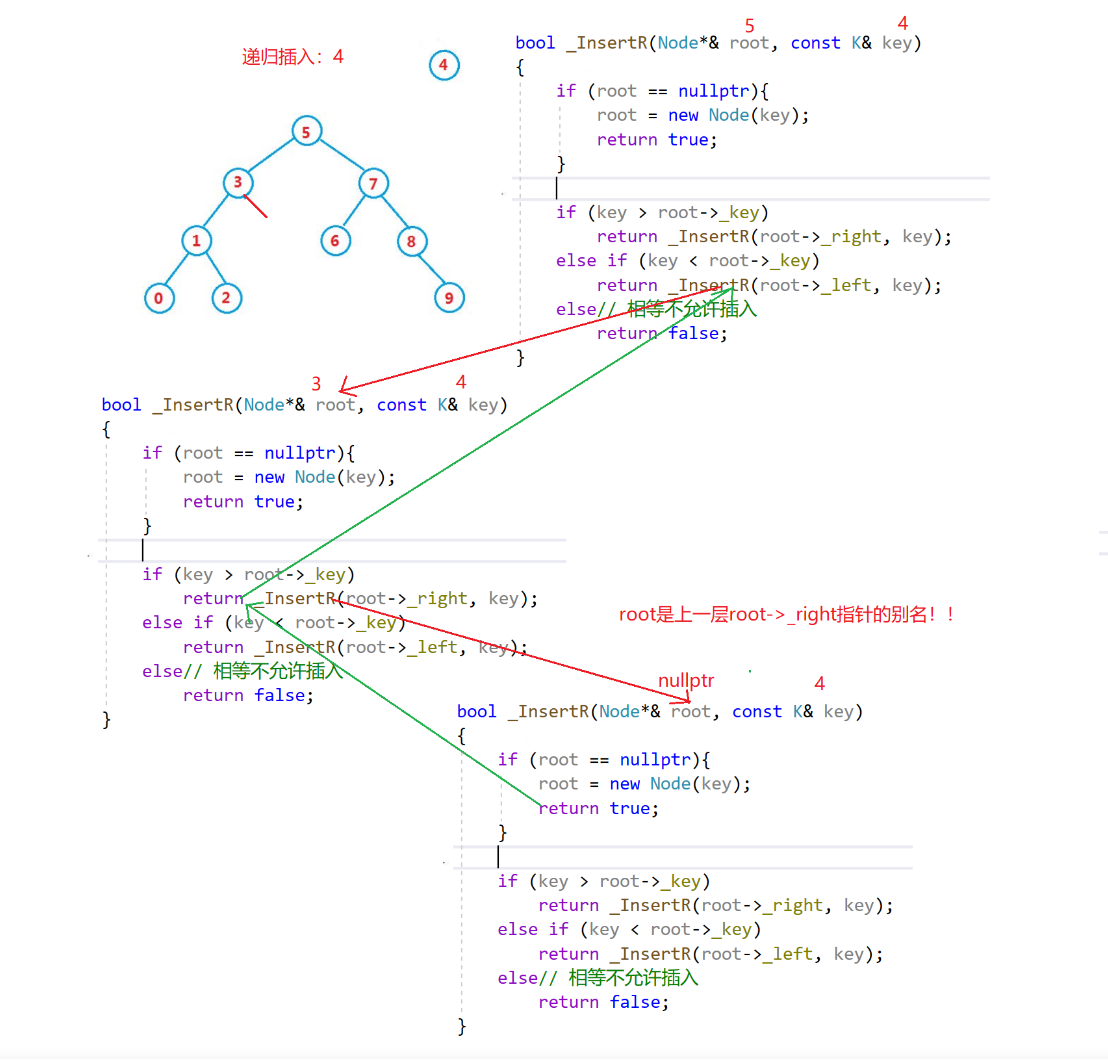
递归插入
图解
这里的指针引用非常细节,这样就能保证链接起来,C语言中就要使用二级指针了。
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr)
{
//开始插入
//因为是引用,root就是上一层的左或者右的别名,所以修改root就是修改上一层的左或者右
root = new Node(key);
return true;
}
if (key > root->_key)
return _InsertR(root->_right, key);
else if (key < root->_key)
return _InsertR(root->_left, key);
else// 相等不允许插入
return false;
}
2.2 查找
迭代查找
// 查找
bool Find(const K& key)
{
Node* cur = _root;
// 从根开始遍历
while (cur)
{
if (key > cur->_key)
cur=cur->_right
else if(key < cur->_key)
cur = cur->_left;
else
return true;
}
return false;
}
递归查找
Node* _FindR( Node* root,const K& key)
{
if (root == nullptr)
return nullptr;
if (key > root->_key)
return _FindR(root->_right, key);
else if (key < root->_left)
return _FindR(root->_left, key);
else// 相等就是找到了,返回节点
return root;
}
2.3 删除
删除是重头戏,这是面试很爱考察的!
删除的节点分类(1,2可以归结为同一类):
1、叶子节点
2、只有一个孩子的节点
3、有两个孩子节点
情况1:删除叶子节点
情况2:删除只有一个孩子的节点
分析:
1️⃣第一种和第二种都是直接删除,其实可以归类为同一种:
- 被删除节点,左为空,让父亲指向被删除节点的右;
- 右为空,让父亲指向被删除节点的左,
注意:
- 要注意特殊情况,被删除的节点是父亲的什么,此处需要特判断一下。
- 当出现父亲节点为空时,就又会出问题,我们需要更新_root
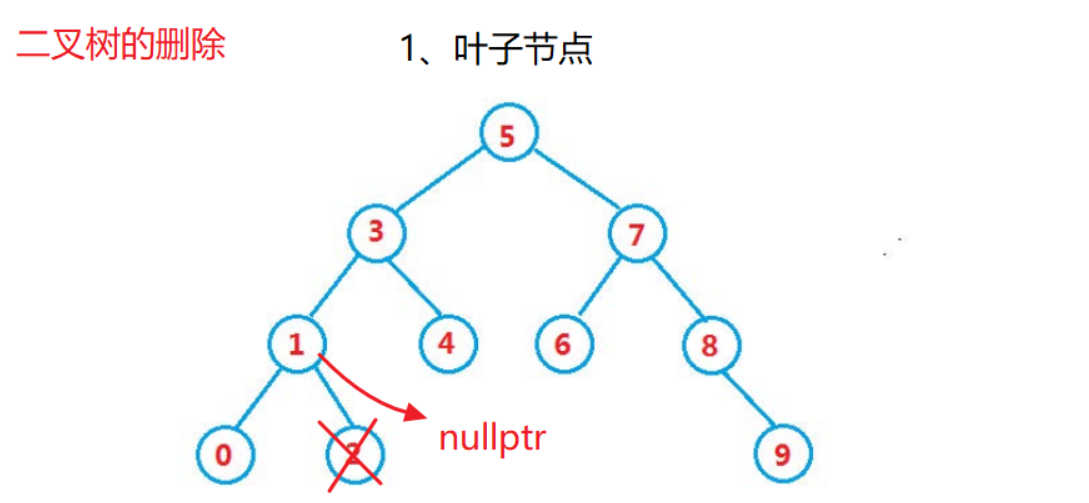


情况3:删除有两个孩子的节点(找保姆)
替换法:找寻左子树的最大节点,或者右子树的最小节点进行替换删除
分析:
- cur的右子树的左不为空,此时将最小节点min的值和要删除节点的值互换,然后将min节点的父亲连接min的右边(左边不能有节点,因为左边的节点一定比min小),删除min即可
- cur的右子树的左为空,那么cur的右子树就是最小节点。
这里删除8
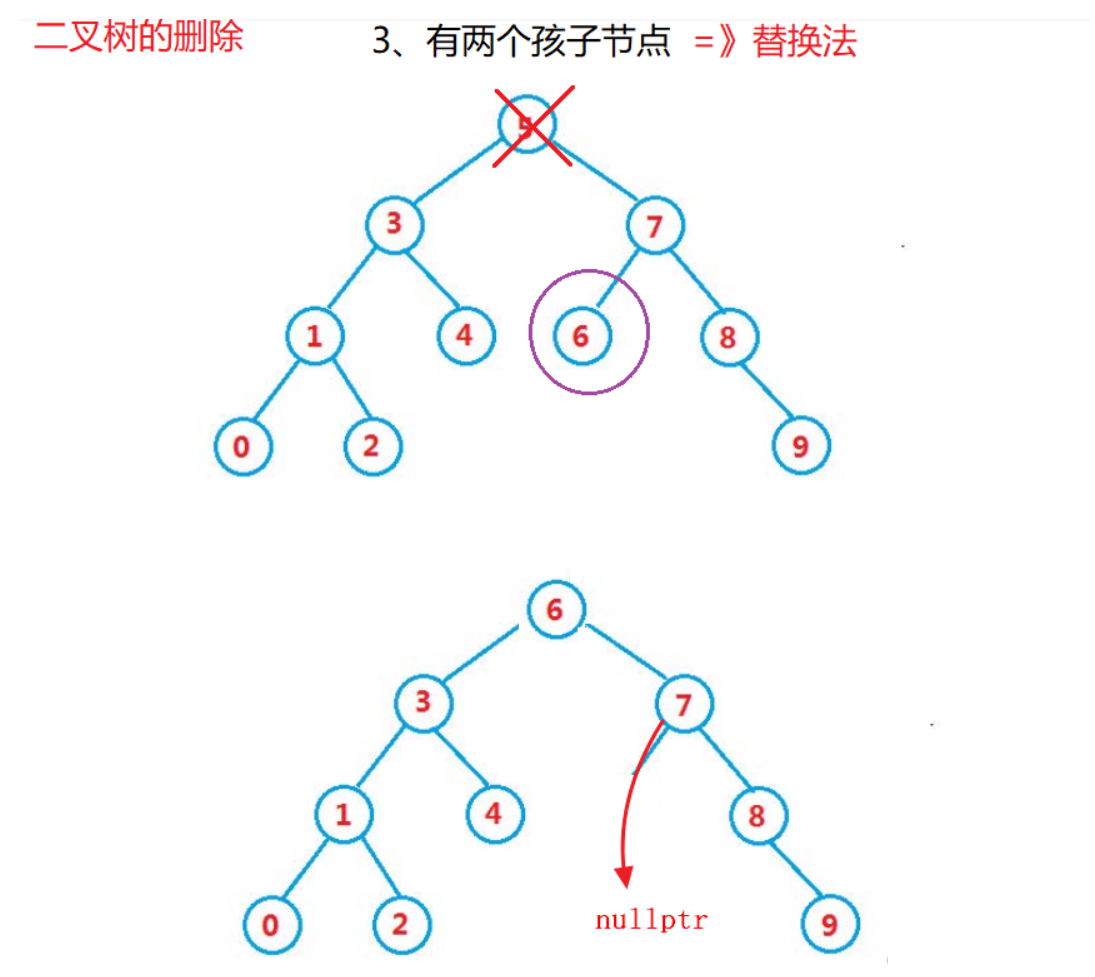


迭代删除
// 删除
bool Erase(const K& key)
{
//先找到我们要删除的那个节点和它的父亲节点
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
parent = cur;
}
else if (key < cur->_left)
{
cur = cur->_left;
parent = cur;
}
else
{
// 找到了 准备开始删除
if (cur->_left == nullptr)
{
// 当父亲为空时,也需要特殊处理一下
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
// 需要特判一下,被删除节点是父亲的哪个节点
if (cur == parent->_left)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
// 当父亲为空时,也需要特殊处理一下
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
}
else
{
// 替换法删除
Node* minParent = cur;
Node* min = cur->_right;//右树的最小节点
while (min->_left)
{
minParent = min;
min = min->_left;
}
// 覆盖cur节点
cur->_key = min->_key;
//转换成删除替代节点min
if (minParent->_left==min)
minParent->_left = min->_right;
else
minParent->_right = min->_right;
delete min;
}
return true;
}
}
return false;
}
递归删除
bool _EraseR(Node* &root, const K& key)
{
if (root == nullptr)
return false;
if (key > root->_key)
return _EraseR(root->_right, key);
else if (key < root->_key)
return _EraseR(root->_left, key);
else// 开始删除
{
Node* del = root;// 记录一下要删除的节点
if (root->_left == nullptr)
root = root -> _right;
else if (root->_right == nullptr)
root = root->_left;
else
{
//替代法删除
//左右都不为空
Node* min = root->_right;
while (min->_left)
{
min = min->_left;
}
std::swap(min->_key, root->_key);
// 递归到右子树去删除
return _EraseR(root->_right, key);
}
delete del;
return true;
}
}
2.4 中序遍历
public:
void InOrder()
{
_InOrder(_root);
}
// 中序遍历
void _InOrder(Node * root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
std::cout << root->_key << " ";
_InOrder(root->_right);
}
三、二叉搜索树的应用
1、K模型
K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
主要用于解决在不在问题:
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
以单词集合中的每个单词作为key,构建一棵二叉搜索树
在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
namespace K
{
template<class K>
struct BSTreeNode
{
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
BSTreeNode(const K& key) :_left(nullptr), _right(nullptr), _key(key) {}
};
template<class K>
struct BSTree
{
typedef BSTreeNode<K> Node;
public:
BSTree() :_root(nullptr) {}
~BSTree() {}
// 递归版本
// 因为递归都需要根,但是我们在类外穿参数时,都拿不到根,所以要嵌套一个子函数
bool InsertR(const K& key)
{
return _InsertR(_root, key);
}
Node* FindR(const K& key)
{
return _FindR(_root, key);
}
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
// 插入数据保持继续是二叉搜索树
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
// 往右边走
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
// 往左边走
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
// _key==key
else
{
return false;
}
}
// 这里说明走到合适的空位置了,需要链接起来
cur = new Node(key);
if (key > parent->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
// 查找
bool Find(const K& key)
{
Node* cur = _root;
// 从根开始遍历
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return true;
}
}
return false;
}
bool Erase(const K& key)
{
//先找到我们要删除的那个节点和它的父亲节点
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
// 找到了 准备开始删除
if (cur->_left == nullptr)
{
// 当父亲为空时,也需要特殊处理一下
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
// 需要特判一下,被删除节点是父亲的哪个节点
if (cur == parent->_left)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
// 当父亲为空时,也需要特殊处理一下
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
}
else
{
// 替换法删除
Node* minParent = cur;
Node* min = cur->_right;//右树的最小节点
while (min->_left)
{
minParent = min;
min = min->_left;
}
// 覆盖cur节点
cur->_key = min->_key;
//转换成删除替代节点min
if (minParent->_left == min)
minParent->_left = min->_right;
else
minParent->_right = min->_right;
delete min;
}
return true;
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
std::cout << std::endl;
}
// 中序遍历
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
std::cout << root->_key << " ";
_InOrder(root->_right);
}
private:
Node* _FindR(Node* root, const K& key)
{
if (root == nullptr)
return nullptr;
if (key > root->_key)
return _FindR(root->_right, key);
else if (key < root->_left)
return _FindR(root->_left, key);
else// 相等就是找到了,返回节点
return root;
}
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr) {
root = new Node(key);
return true;
}
if (key > root->_key)
return _InsertR(root->_right, key);
else if (key < root->_key)
return _InsertR(root->_left, key);
else// 相等不允许插入
return false;
}
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
return false;
if (key > root->_key)
return _EraseR(root->_right, key);
else if (key < root->_key)
return _EraseR(root->_left, key);
else// 开始删除
{
Node* del = root;// 记录一下要删除的节点
if (root->_left == nullptr)
root = root->_right;
else if (root->_right == nullptr)
root = root->_left;
else
{
//替代法删除
//左右都不为空
Node* min = root->_right;
while (min->_left)
{
min = min->_left;
}
std::swap(min->_key, root->_key);
// 递归到右子树去删除
return _EraseR(root->_right, key);
}
delete del;
return true;
}
}
private:
Node* _root;
};
void TestBSTree()
{
BSTree<int> t;
int a[] = { 9,8,7,6,5,4,3,2,1,0 };
for (auto e : a)
{
t.InsertR(e);
}
t.InOrder();
t.EraseR(5);
t.InOrder();
t.EraseR(7);
t.InOrder();
}
}
2、KV模型
KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。
主要解决给一个值查找另外一个值
该种方式在现实生活中非常常见:比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。
比如:实现一个简单的英汉词典dict,可以通过英文找到与其对应的中文,具体实现方式如下:
- <单词,中文含义>为键值对构造二叉搜索树,注意:二叉搜索树需要比较,键值对比较时只比较Key
- 查询英文单词时,只需给出英文单词,就可快速找到与其对应的key
namespace KV
{
template<class K, class V>
struct BSTreeNode
{
BSTreeNode<K, V>* _left;
BSTreeNode<K, V>* _right;
K _key;
V _value;
BSTreeNode(const K& key, const V& value)
:_left(nullptr),
_right(nullptr),
_key(key),
_value(value)
{}
};
template<class K, class V>
struct BSTree
{
typedef BSTreeNode<K, V> Node;
public:
BSTree() :_root(nullptr) {}
~BSTree() {}
// 插入数据保持继续是二叉搜索树
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
// 往右边走
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
// 往左边走
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
// _key==key
else
{
return false;
}
}
// 这里说明走到合适的空位置了,需要链接起来
cur = new Node(key, value);
if (key > parent->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
// 查找
Node* Find(const K& key)
{
Node* cur = _root;
// 从根开始遍历
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const K& key)
{
//先找到我们要删除的那个节点和它的父亲节点
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
// 找到了 准备开始删除
if (cur->_left == nullptr)
{
// 当父亲为空时,也需要特殊处理一下
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
// 需要特判一下,被删除节点是父亲的哪个节点
if (cur == parent->_left)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
// 当父亲为空时,也需要特殊处理一下
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
}
else
{
// 替换法删除
Node* minParent = cur;
Node* min = cur->_right;//右树的最小节点
while (min->_left)
{
minParent = min;
min = min->_left;
}
// 覆盖cur节点
cur->_key = min->_key;
cur->_value = min->_value;
//转换成删除替代节点min
if (minParent->_left == min)
minParent->_left = min->_right;
else
minParent->_right = min->_right;
delete min;
}
return true;
}
}
return false;
}
void InOrder()
{
_InOrder(_root);
std::cout << std::endl;
}
// 中序遍历
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
private:
Node* _root;
};
//测试如下
void TestBSTree_KV1()
{
// 字典模型KV
BSTree<std::string, std::string> dict;
dict.Insert("sort", "排序");
dict.Insert("study", "学习");
dict.Insert("C++", "C加加");
dict.InOrder();
std::string str;
while (std::cin >> str)
{
BSTreeNode<std::string, std::string>* ret = dict.Find(str);
if (ret)
{
std::cout << "对应的中文解释为: " << ret->_value << std::endl;
}
else
{
std::cout << "词库无此单词!!" << std::endl;
}
}
}
void TestBSTree_KV2()
{
//统计水果出现的次数
string fruits[] = { "香蕉","香蕉","香蕉","香蕉","橘子","苹果","橘子","西瓜","橘子" ,"橘子" ,"橘子","苹果","苹果","苹果","苹果" };
BSTree <string, int> countTree;
for (auto& str : fruits)
{
//BSTreeNode<std::string, int>* ret = countTree.Find(e);
auto ret = countTree.Find(str);
if (ret != nullptr)
{
ret->_value++;
}
else
{
countTree.Insert(str,1);
}
}
countTree.InOrder();
}
}
四、二叉树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
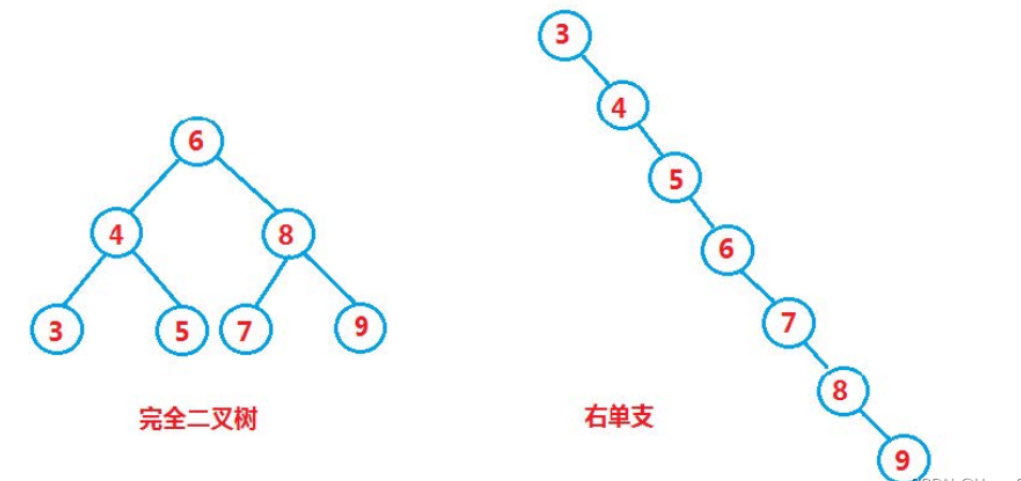
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:logN
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2

![前沿重器[35] | 提示工程和提示构造技巧](https://img-blog.csdnimg.cn/img_convert/7e58021e19c2a1fd75a3989cf3729549.png)










![[JVM]再聊 CMS 收集器](https://img-blog.csdnimg.cn/a4fe8c81a83745e8bf7d9c1cf60639d9.png)