文章目录
- 一、方法引用
- 1.1 为什么要有方法引用?
- 1.1.1 Lambda表达式冗余
- 1.1.2 解决方案
- 1.2 方法引用的格式
- 1.2 .1 对象::方法名
- 1.2.2 类名::静态方法名
- 1.2.3 类名::引用实例方法
- 1.2.4 类名::构造器
- 1.2.5 数组::构造器
- 二、Stream API
- 2.1 集合处理的弊端
- 2.2 Steam流式思想概述
- 2.3 Stream流的获取方式
- 2.3.1 通过Collection获取
- 2.3.2 通过Stream的of方法
- 2.4 Stream流常用方法介绍
- 2.4.1 forEach
- 2.4.2 count
- 2.4.2 filter
- 2.4.4 limit
- 2.4.5skip
- 2.4.6 map
- 2.4.7 sorted
- 2.4.8 distinct
- 2.4.9 match
- 2.4.10 find
- 2.4.11 max和min
- 2.4.12 reduce
- 2.4.13 map和reduce的组合
- 2.4.14 mapToInt
- 2.4.15 concat
- 3、小结
- 总结
🌕博客x主页:己不由心王道长🌕!
🌎文章说明:JDK8新特性🌎
✅系列专栏:Java基础
🌴本篇内容:对JDK8的新特性进行学习和讲解🌴
☕️每日一语:这个世界本来就不完美,如果我们再不接受不完美的自己,那我们要怎么活。☕️
🚩 交流社区:己不由心王道长(优质编程社区)
一、方法引用
1.1 为什么要有方法引用?
1.1.1 Lambda表达式冗余
在使用Lambda表达式的时候,也会出现代码冗余的情况,比如:用Lambda表达式求一个数组的和
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description
* @Version 1.0
*/
public class FunctionRefTest01 {
public static void main(String[] args) {
getSum(arg1->{
int sum = 0;
for(int temp:arg1){
sum+=temp;
}
System.out.println(sum);
});
}
public static void getSum(Consumer<int[]> consumer){
int[] arr = {10,8,6,4};
consumer.accept(arr);
}
}
1.1.2 解决方案
因为在Lambda表达式中要执行的代码和我们另一个方法中的代码是一样的,这时就没有必要重写一份逻辑了,这时我们就可以“引用”重复代码。
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description
* @Version 1.0
*/
public class FunctionRefTest02 {
public static void main(String[] args) {
getSum(FunctionRefTest02::get);
}
/**
* 获取数组元素之和
* @param arr
*/
public static void get(int[] arr){
int sum = 0 ;
for(int i:arr){
sum+=i;
}
System.out.println("数组之和为:"+sum);
}
/**
* Lambda表达式的用法
* @param consumer
*/
public static void getSum(Consumer<int[]> consumer){
int[] arr = {10,8,6,4};
consumer.accept(arr);
}
}
解释: 其实就是在用Lambda表达式的时候,把小括号里面要做的操作抽离出来,作为一个单独的方法,进行引用,这样就不用每次都去编写重复的代码了。
:: 方法引用 也是JDK8中的新的语法
1.2 方法引用的格式
符号表示: ::
符号说明:双冒号为方法引用运算符,而它所在的表达式被称为 方法引用
应用场景:如果Lambda表达式所要实现的方案,已经有其他方法存在相同的方案,那么则可以使用方法引用。
常见的引用方式:
方法引用在JDK8中使用是相当灵活的,有以下几种形式:
1. instanceName::methodName 对象::方法名
2. ClassName::staticMethodName 类名::静态方法
3. ClassName::methodName 类名::普通方法
4. ClassName::new 类名::new 调用的构造器
5. TypeName[]::new String[]::new 调用数组的构造器
1.2 .1 对象::方法名
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description 对象::方法名
* @Version 1.0
*/
public class FunctionRefTest03 {
public static void main(String[] args) {
Date now = new Date();
Supplier<Long> supplier1 = ()->{return now.getTime();};
System.out.println(supplier1.get());
//对象::方法名
Supplier<Long> supplier2 = now::getTime;
System.out.println(supplier2.get());
}
}
1687760646740
1687760646740
方法引用的注意事项:
- 被引用的方法,参数要和接口中的抽象方法的参数一样
- 当接口抽象方法有返回值时,被引用的方法也必须有返回值
1.2.2 类名::静态方法名
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description 对象::方法名
* @Version 1.0
*/
public class FunctionRefTest04 {
public static void main(String[] args) {
Supplier<Long> supplier = ()->{
return System.currentTimeMillis();
};
System.out.println(supplier.get());
//类名:静态方法名
Supplier<Long> supplier1 = System::currentTimeMillis;
System.out.println(supplier1.get());
}
}
1.2.3 类名::引用实例方法
Java面向对象中,类名只能调用静态方法,类名引用实例方法是用前提的,实际上是拿第一个参数作为方法的调用者:
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description 对象::方法名
* @Version 1.0
*/
public class FunctionRefTest05 {
public static void main(String[] args) {
Function<String,Integer> function = (s)->{
return s.length();
};
System.out.println(function.apply("为年少不可得而遗憾终身"));
//通过方法引用实现
Function<String,Integer> function1 = String::length;
System.out.println(function1.apply("为年少不可得而遗憾终身"));
BiFunction<String,Integer,String> function2 = String::substring;
System.out.println(function2.apply("为年少不可得而遗憾终身",3));
}
}
1.2.4 类名::构造器
由于构造器的名称和类名完全一致,所以构造器引用使用 ::new 的格式使用:
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description 构造器
* @Version 1.0
*/
public class FunctionRefTest06 {
public static void main(String[] args) {
Supplier<Person> supplier1 = ()->{
return new Person();
};
System.out.println(supplier1.get());
//构造器
Supplier<Person> supplier2 = Person::new;
System.out.println(supplier2.get());
BiFunction<String,Integer,Person> biFunction = Person::new;
System.out.println(biFunction.apply("王也",18));
}
}
结果:
Person(name=null, age=null)
Person(name=null, age=null)
Person(name=王也, age=18)
1.2.5 数组::构造器
/**
* @Author Administrator
* @Date 2023/6/26 13:59
* @description 构造器
* @Version 1.0
*/
public class FunctionRefTest07 {
public static void main(String[] args) {
Function<Integer,String[]> function = (len)->{
return new String[len];
};
String[] strs = function.apply(3);
System.out.println(strs.length);
//构造器
Function<Integer,String[]> function1 = String[]::new;
String[] strs2 = function1.apply(5);
System.out.println(strs2.length);
}
}
3
5
二、Stream API
2.1 集合处理的弊端
当我们在需要对集合中的元素进行操作的时候,除了必需的添加,删除,获取外,最典型的操作就是集合遍历:
/**
* @Author Administrator
* @Date 2023/6/26 15:45
* @description
* @Version 1.0
*/
public class StreamTest01 {
public static void main(String[] args) {
List<String> list = Arrays.asList("王也","通下下士","张楚岚","张灵玉");
List<String> list1 = new ArrayList<>();
for(String str:list){
if(str.length()==3){
list1.add(str);
}
}
List<String> list2 = new ArrayList<>();
for(String str:list1){
if(str.startsWith("张")&&str.endsWith("玉")){
list2.add(str);
}
}
System.out.println(list2);
}
}
上面的代码针对与我们不同的需求总是一次次的循环循环循环.这时我们希望有更加高效的处理方式,这时我们就可以通过JDK8中提供StreamAPI来解决这个问题了。Stream更加优雅的解决方案:
/**
* @Author Administrator
* @Date 2023/6/26 15:45
* @description
* @Version 1.0
*/
public class StreamTest02 {
public static void main(String[] args) {
List<String> list = Arrays.asList("王也", "通下下士", "张楚岚", "张灵玉");
//
list.stream()
.filter(s->s.startsWith("通"))
.filter(s->s.length()==4).
forEach(s -> System.out.println(s));
//更加优雅写法
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s -> s.endsWith("玉"))
.forEach(System.out::println);
}
}
上面的SteamAPI代码的含义:获取流,过滤张,过滤长度,逐一打印。代码相比于上面的案例更加的简洁直观
2.2 Steam流式思想概述
Stream流式思想类似于工厂车间的“生产流水线”,Stream流不是一种数据结构,不保存数据,而是对数
据进行加工
处理。Stream可以看作是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商
品。
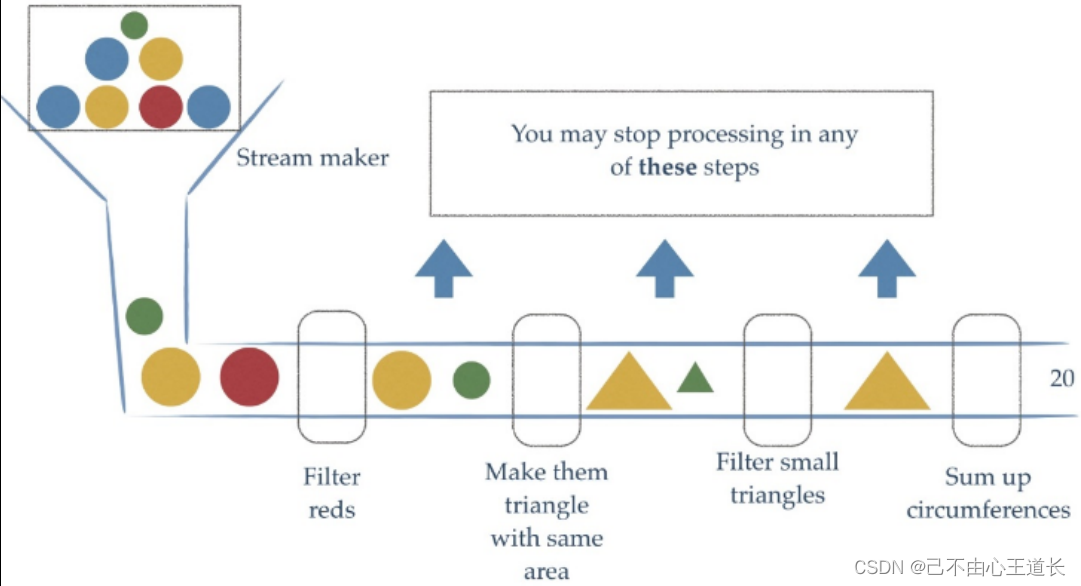
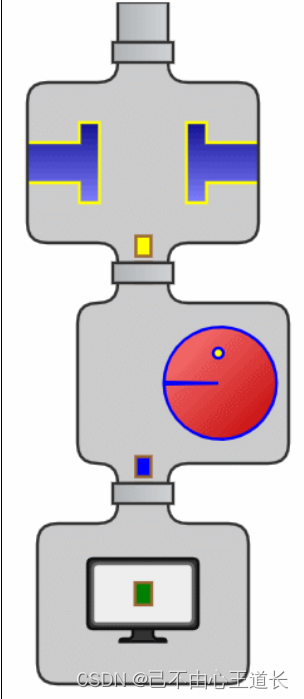
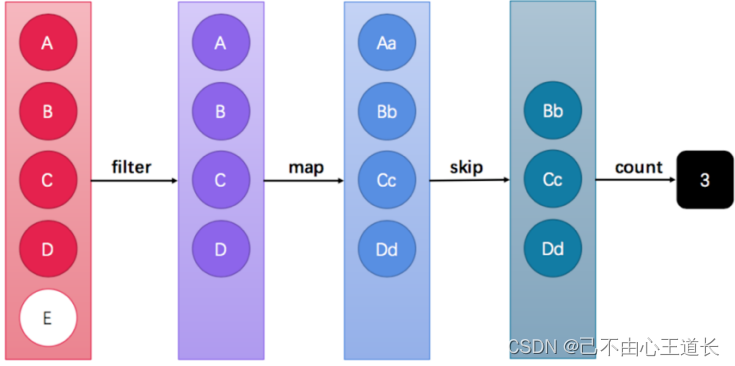
Stream API能让我们快速完成许多复杂的操作,如筛选、切片、映射、查找、去除重复,统计,匹配和归约。
2.3 Stream流的获取方式
2.3.1 通过Collection获取
首先,java.util.Collection 接口中加入了default方法 stream,也就是说Collection接口下的所有的实现都可以通过steam方法来获取Stream流:
/**
* @Author Administrator
* @Date 2023/6/26 16:33
* @description
* @Version 1.0
*/
public class StreamTest03 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.stream();
Set<String> set = new HashSet<>();
set.stream();
Queue<String> queue = new ArrayDeque<>();
queue.stream();
Vector<String> vector = new Vector<>();
vector.stream();
}
}
值得注意的是Map接口别没有实现Collection接口,那这时怎么办呢?这时我们可以根据Map获取对应的key、value的集合。
/**
* @Author Administrator
* @Date 2023/6/26 16:33
* @description
* @Version 1.0
*/
public class StreamTest04 {
public static void main(String[] args) {
Map<String,Object> map = new HashMap<>();
Stream<String> stream = map.keySet().stream();
Stream<Object> stream1 = map.values().stream();
Stream<Map.Entry<String,Object>> stream2 = map.entrySet().stream();
}
}
2.3.2 通过Stream的of方法
在实际开发中我们不可避免的还是会操作到数组中的数据,由于数组对象不可能添加默认方法,所有Stream接口中提供了静态方法of:
/**
* Returns a sequential {@code Stream} containing a single element.
*
* @param t the single element
* @param <T> the type of stream elements
* @return a singleton sequential stream
*/
public static<T> Stream<T> of(T t) {
return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false);
}
/**
* Returns a sequential ordered stream whose elements are the specified values.
*
* @param <T> the type of stream elements
* @param values the elements of the new stream
* @return the new stream
*/
@SafeVarargs
@SuppressWarnings("varargs") // Creating a stream from an array is safe
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
/**
* @Author Administrator
* @Date 2023/6/26 16:33
* @description
* @Version 1.0
*/
public class StreamTest05 {
public static void main(String[] args) {
Stream<String> a1 = Stream.of("己不由心","王也","冯宝宝");
Integer[] arr = {18,20,30};
Stream<Integer> b1 = Stream.of(arr);
String[] arr1 = {"己不由心","心岂会由己","自欺欺人"};
Stream<String> b2 = Stream.of(arr1);
b2.forEach(System.out::println);
}
}
2.4 Stream流常用方法介绍
Stream常用方法
Stream流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法:返回值类型不再是 Stream 类型的方法,不再支持链式调用。本小节中,终结方法包括count 和forEach 方法。
非终结方法:返回值类型仍然是 Stream 类型的方法,支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
Stream注意事项(重要)
- Stream只能操作一次
- Stream方法返回的是新的流
- Stream不调用终结方法,中间的操作不会执行
2.4.1 forEach
用法:forEach用来遍历流中的数据
该方法接收一个Consumer接口,会将每一个流元素交给函数处理
/**
* Performs an action for each element of this stream.
*
* <p>This is a <a href="package-summary.html#StreamOps">terminal
* operation</a>.
*
* <p>The behavior of this operation is explicitly nondeterministic.
* For parallel stream pipelines, this operation does <em>not</em>
* guarantee to respect the encounter order of the stream, as doing so
* would sacrifice the benefit of parallelism. For any given element, the
* action may be performed at whatever time and in whatever thread the
* library chooses. If the action accesses shared state, it is
* responsible for providing the required synchronization.
*
* @param action a <a href="package-summary.html#NonInterference">
* non-interfering</a> action to perform on the elements
*/
void forEach(Consumer<? super T> action);
举例:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest06ForEach {
public static void main(String[] args) {
Stream.of("王也","诸葛青","冯宝宝","张楚岚")
.forEach(System.out::println);
}
}
结果:
王也
诸葛青
冯宝宝
张楚岚
2.4.2 count
Stream流中的count方法用来统计其中的元素个数的:
long count();
该方法返回一个long型数据,表示元素个数:
使用·:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest07Count {
public static void main(String[] args) {
long count = Stream.of("王也", "诸葛青", "冯宝宝", "张楚岚")
.count();
System.out.println(count);
}
}
2.4.2 filter
filter方法的作用是用来过滤数据的。返回符合条件的数据
该方法接收一个Predicate接口作为参数
Stream<T> filter(Predicate<? super T> predicate);
用法:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest08Filter {
public static void main(String[] args) {
Stream.of("王也", "诸葛青", "冯宝宝", "张楚岚")
.filter((s)->s.contains("王"))
.forEach(System.out::println);
}
}
2.4.4 limit
limit方法可以对流进行截取处理,只取前n个数据:
/**
* Returns a stream consisting of the elements of this stream, truncated
* to be no longer than {@code maxSize} in length.
*
* <p>This is a <a href="package-summary.html#StreamOps">short-circuiting
* stateful intermediate operation</a>.
*
* @apiNote
* While {@code limit()} is generally a cheap operation on sequential
* stream pipelines, it can be quite expensive on ordered parallel pipelines,
* especially for large values of {@code maxSize}, since {@code limit(n)}
* is constrained to return not just any <em>n</em> elements, but the
* <em>first n</em> elements in the encounter order. Using an unordered
* stream source (such as {@link #generate(Supplier)}) or removing the
* ordering constraint with {@link #unordered()} may result in significant
* speedups of {@code limit()} in parallel pipelines, if the semantics of
* your situation permit. If consistency with encounter order is required,
* and you are experiencing poor performance or memory utilization with
* {@code limit()} in parallel pipelines, switching to sequential execution
* with {@link #sequential()} may improve performance.
*
* @param maxSize the number of elements the stream should be limited to
* @return the new stream
* @throws IllegalArgumentException if {@code maxSize} is negative
*/
Stream<T> limit(long maxSize)
用法:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest09limit {
public static void main(String[] args) {
Stream.of("王也", "诸葛青", "冯宝宝", "张楚岚")
.limit(3)
.forEach(System.out::println);
}
}
结果:
王也
诸葛青
冯宝宝
2.4.5skip
如果希望跳过前面几个元素,可以使用skip方法获取一个截取之后的新流:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest10Skip {
public static void main(String[] args) {
Stream.of("王也", "诸葛青", "冯宝宝", "张楚岚")
.skip(3)
.forEach(System.out::println);
}
}
2.4.6 map
如果我们需要将流中的元素映射到另一个流中,可以使用map方法:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的数据
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest11Map {
public static void main(String[] args) {
Stream.of("1","2","3","4")
.map(Integer::parseInt)
.forEach(System.out::println);
}
}
2.4.7 sorted
对数据进行排序,支持默认排序(升序)和自定义排序(实现compartor)
Stream<T> sorted();
用法:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest12Sorted {
public static void main(String[] args) {
Integer[] arr = {9,8,10,7,6};
Stream.of(arr)
.sorted()
.forEach(System.out::println);
}
}
2.4.8 distinct
对元素进行去重:
普通去重:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest12Distinct {
public static void main(String[] args) {
Integer[] arr = {9,9,10,7,6,6};
Stream.of(arr)
.distinct()
.forEach(System.out::println);
}
}
结果:
9
10
7
6
自定义去重:
Stream流中的distinct方法对于基本数据类型是可以直接出重的,但是对于自定义类型,我们是需要重写hashCode和equals方法来移除重复元素。
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest13Distinct {
public static void main(String[] args) {
// Integer[] arr = {9,9,10,7,6,6};
// //普通去重
// Stream.of(arr)
// .distinct()
// .forEach(System.out::println);
// //自定义去重
Stream.of(
new Person("王也",18),
new Person("冯宝宝",18),
new Person("张楚岚",19),
new Person("冯宝宝",18)
).distinct()
.forEach(System.out::println);
}
}
2.4.9 match
如果需要判断数据是否匹配指定的条件,可以使用match相关的方法:注意match是一个终结方法
boolean anyMatch(Predicate<? super T> predicate); // 元素是否有任意一个满足条件
boolean allMatch(Predicate<? super T> predicate); // 元素是否都满足条件
boolean noneMatch(Predicate<? super T> predicate); // 元素是否都不满足条件
使用:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest13Match {
public static void main(String[] args) {
Integer[] arr = {9,9,10,7,6,6};
boolean b = Stream.of(arr)
.allMatch(s -> s > 3);
System.out.println(b);//true
boolean b1 = Stream.of(arr)
.anyMatch(s -> s == 10);
System.out.println(b1);//true
boolean b2 = Stream.of(arr)
.noneMatch(s -> s > 9);
System.out.println(b2);
}
}
结果:
2.4.10 find
如果我们需要找到某些数据,可以使用find方法来实现
Optional<T> findFirst();
Optional<T> findAny();
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest15Find {
public static void main(String[] args) {
Integer[] arr = {9,9,10,7,6,6};
Optional<Integer> first = Stream.of(arr)
.findFirst();
System.out.println(first.get());
Optional<Integer> any = Stream.of(arr)
.findAny();
System.out.println(any.get());
}
}
2.4.11 max和min
如果我们想要获取最大值和最小值,那么可以使用max和min方法:
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
使用:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest16MaxMin {
public static void main(String[] args) {
String[] arr = {"1","6","5","2000","7200","35","24"};
Optional<Integer> max = Stream.of(arr)
.map(Integer::parseInt)
.max(((o1, o2) -> o1-o2));
System.out.println(max.get());
Optional<Integer> min = Stream.of(arr)
.map(Integer::parseInt)
.min(((o1, o2) -> o1-o2));
System.out.println(max.get());
}
}
2.4.12 reduce
如果需要将所有数据归纳得到一个数据,可以使用reduce方法:
T reduce(T identity, BinaryOperator<T> accumulator);
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest17Reduce {
public static void main(String[] args) {
Integer reduce = Stream.of(1, 2, 3, 4)
.reduce(0, (x, y) -> {
return x + y;
});
System.out.println(reduce);
}
}
说明:0,初始化x为0,x,y作为参数,y每次都从of里顺序取数与x进行操作并且返回给x。
2.4.13 map和reduce的组合
在实际的应用中,map与reduce的组合使用是非常多的
我们举个例子使用一下:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest18ReduceMap {
public static void main(String[] args) {
//1、求出所有年龄的综合
Integer reduce = Stream.of(
new Person("王也", 18),
new Person("冯宝宝", 18),
new Person("张楚岚", 19),
new Person("冯宝宝", 18)
).map(Person::getAge)
.reduce(0, (x, y) -> {
return x + y;
});
System.out.println(reduce);
//2、求出所有年龄中的最大值
Integer Max = Stream.of(
new Person("王也", 18),
new Person("冯宝宝", 18),
new Person("张楚岚", 19),
new Person("冯宝宝", 18)
).map(Person::getAge)
.reduce(0, Math::max);
System.out.println(Max);
//统计字符出现的次数
Integer reduce1 = Stream.of("1", "2", "2", "3", "4")
.map(ch -> "2".equals(ch) ? 1 : 0)
.reduce(0, (x, y) -> {
return x + y;
});
System.out.println(reduce1);
}
}
结果:
73
19
2
2.4.14 mapToInt
如果需要将Stream中的Integer类型转换成int类型,可以使用mapToInt方法来实现:
出现这个的原因:
由于Stream流中基本数据类型的数组类型不能有效输出,而包装类型的内存消耗比基本内容大很多,所以在进入流之后应该对其进行拆箱。
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest19mapToInt {
public static void main(String[] args) {
int[] arr = {1,2,3};
Stream.of(arr)
.forEach(System.out::println);
//结果:[I@404b9385
}
}
使用:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest19mapToInt {
public static void main(String[] args) {
Integer[] arr = {2,3,5,9,7,8};
Stream.of(arr)
.filter(i->i>3)
.mapToInt(Integer::intValue)
.sorted()
.forEach(System.out::println);
}
}
2.4.15 concat
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat:
/**
* Creates a lazily concatenated stream whose elements are all the
* elements of the first stream followed by all the elements of the
* second stream. The resulting stream is ordered if both
* of the input streams are ordered, and parallel if either of the input
* streams is parallel. When the resulting stream is closed, the close
* handlers for both input streams are invoked.
*
* @implNote
* Use caution when constructing streams from repeated concatenation.
* Accessing an element of a deeply concatenated stream can result in deep
* call chains, or even {@code StackOverflowException}.
*
* @param <T> The type of stream elements
* @param a the first stream
* @param b the second stream
* @return the concatenation of the two input streams
*/
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}
使用:
/**
* @Author Administrator
* @Date 2023/6/26 20:12
* @description
* @Version 1.0
*/
public class StreamTest20Contact {
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("1","2","3","a");
Stream<String> stream2 = Stream.of("4","5","6","a");
Stream.concat(stream1,stream2)
.forEach(System.out::println);
}
}
结果:
1
2
3
a
4
5
6
a
3、小结
这里介绍的方法并不是Stream流的全部方法,而是Stream流的常用方法,
其实很好理解,自己动手写一遍。
总结
**本来想分为上下部的,结果一看,好家伙,这字数就挺多的啦,不能再多,所以就暂且分为中部吧,最后一部是结尾篇,下部。在完成JDK8新特新的学习之后,我会把上中下整合起来,当然分开的也留着。 **