目录
ConcurrentHashMap 1.8的优化
初始化流程
扩容流程
读取数据流程
计数器的实现
ConcurrentHashMap 1.8的优化
-
存储结构的优化
数组+链表 -> 数组+链表+红黑树 -
写数据加锁的优化
-
扩容的优化(协助优化)
-
计数器的优化
LongAddr -> Cell[] 分段和汇总
线程安全,但是复合操作时只保证弱一致性/最终一致性 散列算法 当需要向ConcurrentHashMap中写入数据时,会根据key的hashcode来确定当前数据要放在数组的哪一个索引位置上,那么ConcurrentHashMap是如何实现散列算法的,我们来看看源码
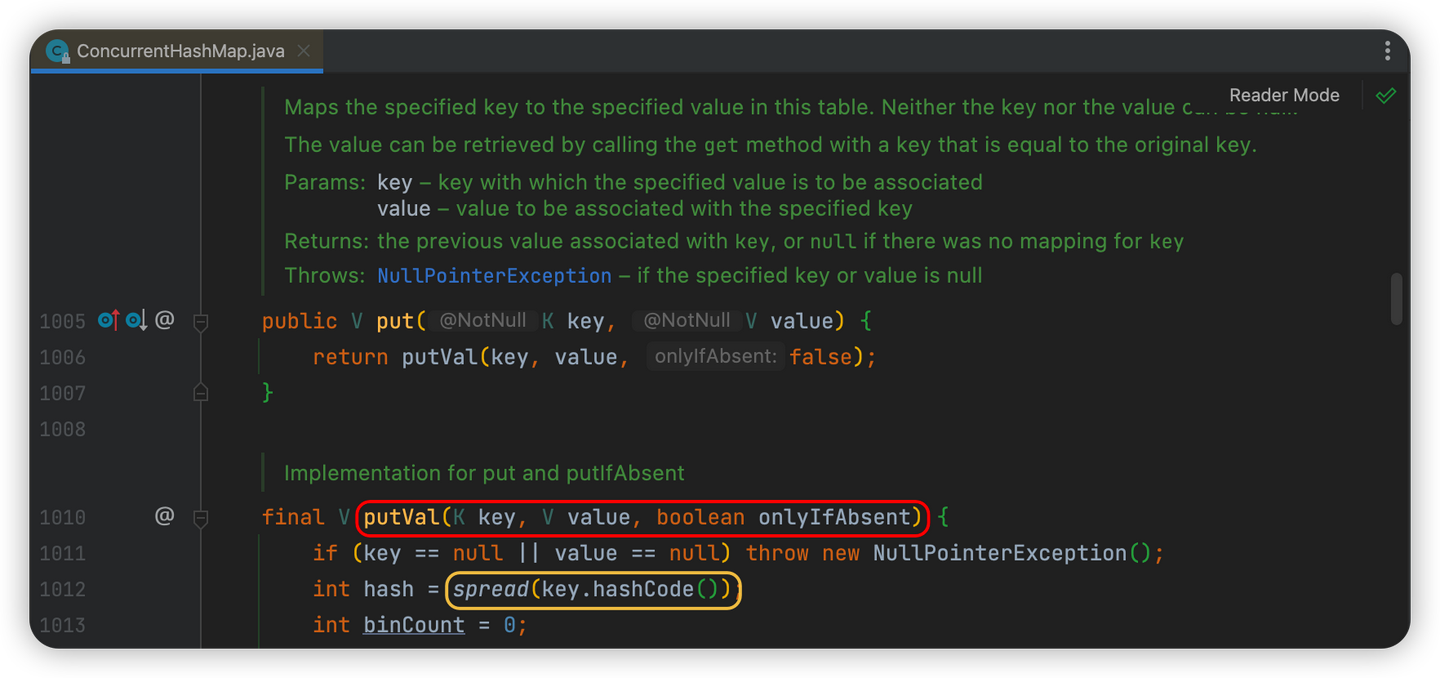
当向map中放数据时,我们用的是put()方法,这个方法在ConcurrentHashMap的源码中实际上是调用了putVal()方法
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 不允许key或者value值为null(HashMap没有这个限制🚫)
if (key == null || value == null) throw new NullPointerException();
// 根据key的hashCode计算出一个哈希值,后面得出当前key-value要存储在哪个数组索引位置
int hash = spread(key.hashCode());
// 后面会用到的一个标识
int binCount = 0;
……
}方法中先对key和value值进行了是否为空的判断,ConcurrentHashMap是不允许key或者value值为null的,这也是和HashMap的一个区别,然后开始计算🧮key的hashCode,以获取后面得出当前key-value要存储在哪个数组索引位置,而在计算key的hash值时,调用了一个名为spread的方法

简单翻译下方法上面👆的那几行绿字
将哈希值的高位传播(XOR)到低位,并将最高位强制为0。 因为表使用了2次方掩码,仅在当前掩码以上的位数不同的一组哈希值总是会发生碰撞。(已知的例子包括在小表中持有连续整数的Float键的集合)。因此,我们应用一个转换,将高位的影响向下分散。在速度、实用性和位传播的质量之间有一个权衡。因为许多常见的哈希集已经是合理分布的(所以不受益于传播),而且因为我们使用树来处理大集的碰撞,我们只是以最便宜的方式XOR一些移位的比特,以减少系统损失,以及纳入最高比特的影响,否则由于表的界限,永远不会被用于索引计算。
这个方法将key的hashcode的高低16位进行"^"(异或)运算,最终又与HASH_BITS(如下图)进行"&"(与)运算,此处巧妙的使用了一个转换,通过将key的hashcode的右移16位,将其哈希值的高位向下传播到低位,并通过与HASH_BITS即0x7fffffff(Integer的最大值,最高位是0,其余都是1)进行的与运算将最高位强制为0

简单来讲就是之前用传统的方式计算hashcode时,由于数组长度没那么长,就导致只有低位参与计算,产生哈希冲突的概率较高,将高位与地位进行异或运算可以使得高位也参与到运算中,尽可能的减少哈希冲突,此外负数在哈希值中有特殊含义(后面会介绍到),因此采用了spread()方法中的方式避免生成负的哈希值
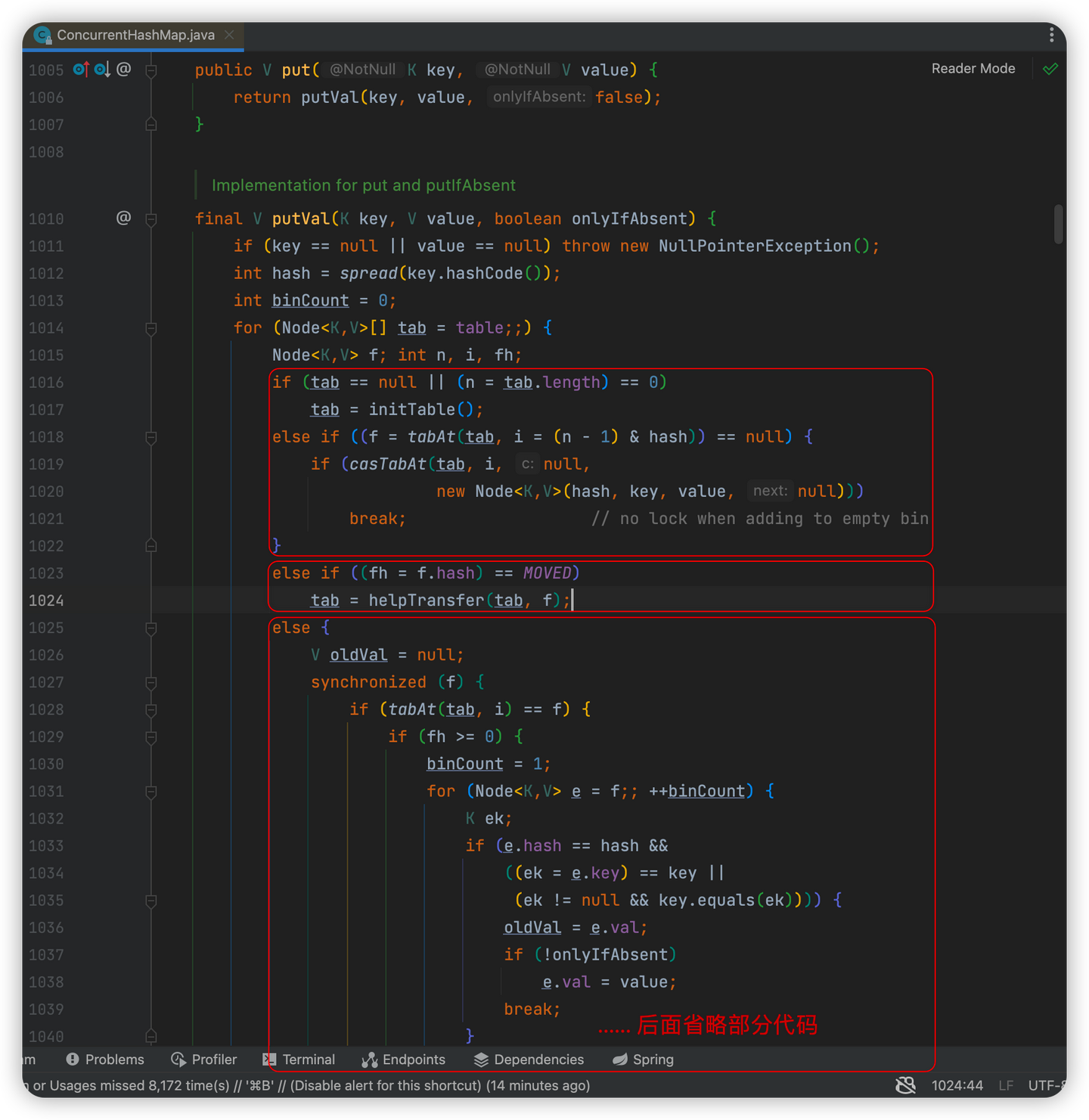
在调用spread()方法计算完哈希值后,进入了一段for循环,循环中先声明了4个变量
-
n:数组长度
-
i:当前Node要存放的索引位置
-
f:当前数组i索引位置上的Node对象
-
fn:当前数组i索引位置上数据的哈希值
接着大致按上图分为了三块逻辑:
-
对是否进行过初始化的处理
-
对是否处于扩容期间的处理
-
对数组下挂的结构已经从链表变成了红黑树情况的处理
详细流程如下:
-
判断数组是否进行过初始化(先看能不能直接放在数组上)
-
没有
-
调用initTable()方法进行初始化
-
- 已初始化
- 基于i = (n - 1) & hash)计算出当前Node需要存放在哪个索引位置
- 通过tabAt()方法获取哈希表i位置上的数据
- 如果该位置为空 -> 该位置没有数据
- 基于CAS方法将数据放在i位置上 -> 成功放置后结束循环
-
-
哈希表i位置不为空(无法直接放在数组上,产生了哈希冲突,继续下面的逻辑)
-
判断当前位置是否在扩容(fh = f.hash) == MOVED
-
如果等于-1,则说明数组正在进行扩容,会调用helpTransfer()方法进行协助扩容(这也就是文章第一部分提到的1.8的新特性之一:协助扩容)
-
-
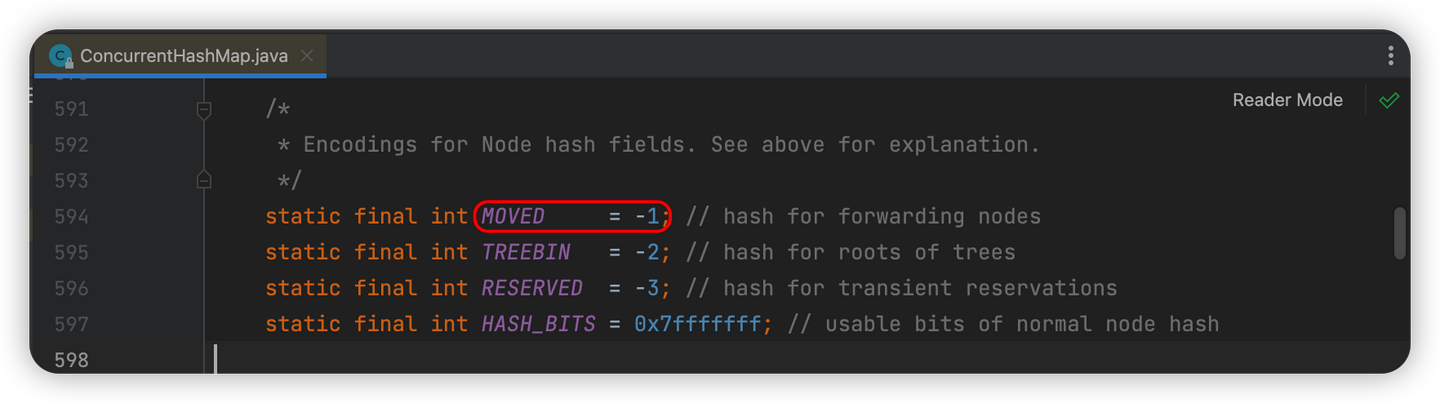
-
如果不等于-1,则说明未在扩容期间,而且此时该位置下挂的不是一个链表,而是一棵红黑树,接下来的逻辑(截图中省略的部分)就是将数据存放到红黑树中的相应位置(其中涉及到红黑树的旋转问题,比较复杂,后后面考虑单独出一篇来分析)
这个方法差不多介绍完了,再问一个☝️问题:知道为什么ConcurrentHashMap的数组长度需要是2^n?

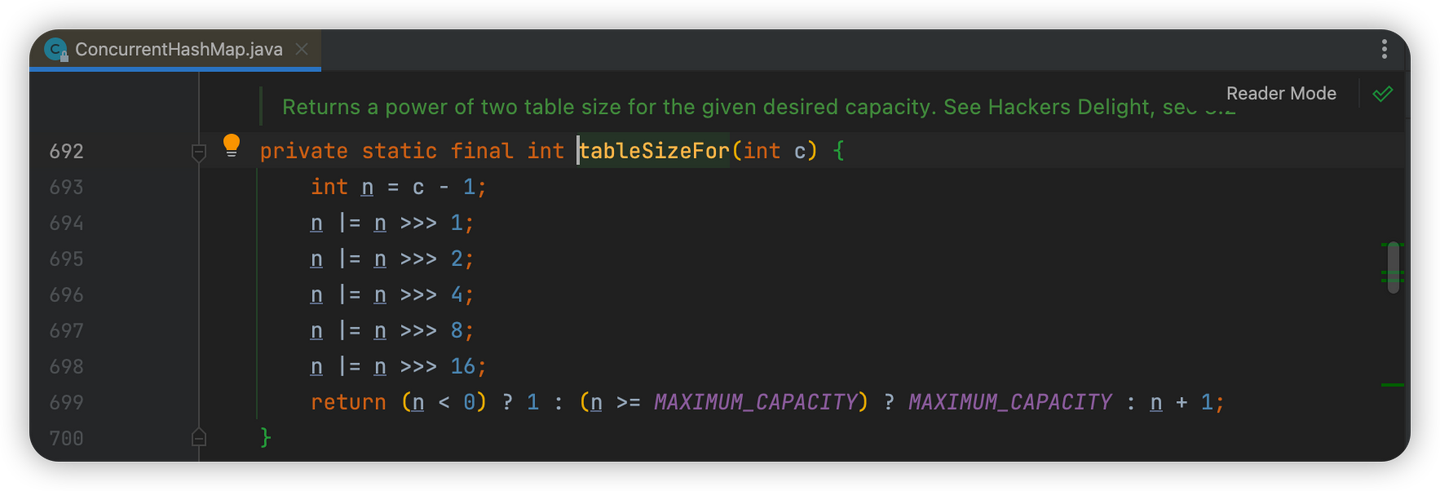
上图中可以看到,在计算当前Node具体存放的索引位置时,使用了n-1,n代表数组长度,即这个索引位置是通过数组长度-1与通过spread()方法返回的哈希值与运算计算出的,当数组长度为2^n时,可以最大程度的避免哈希冲突,因此有着个要求,就算给ConcurrentHashMap传入的大小不是2^n,ConcurrentHashMap也会计算出大于该数的最小2^n,赋值给n。
初始化流程
数组是懒加载的,第一次执行put()方法的时候才会进行初始化
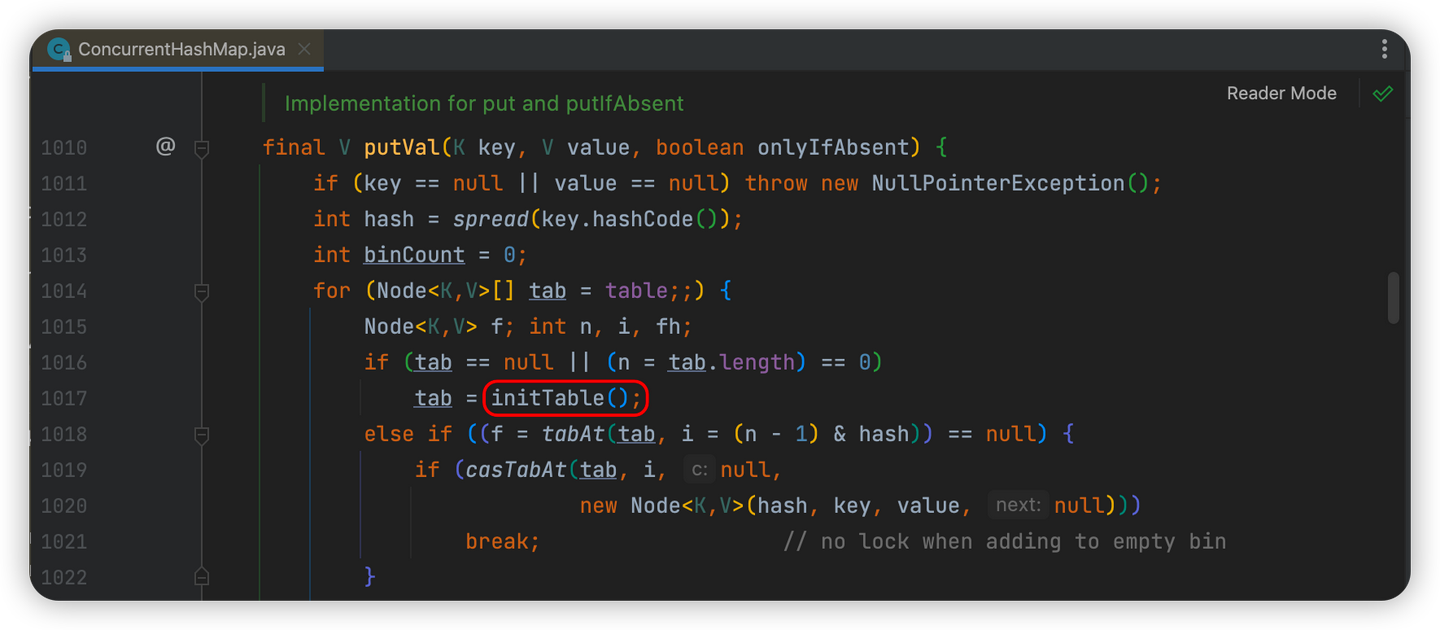
initTable()就是初始化方法,这里面有一个很重要的变量sizeCtl
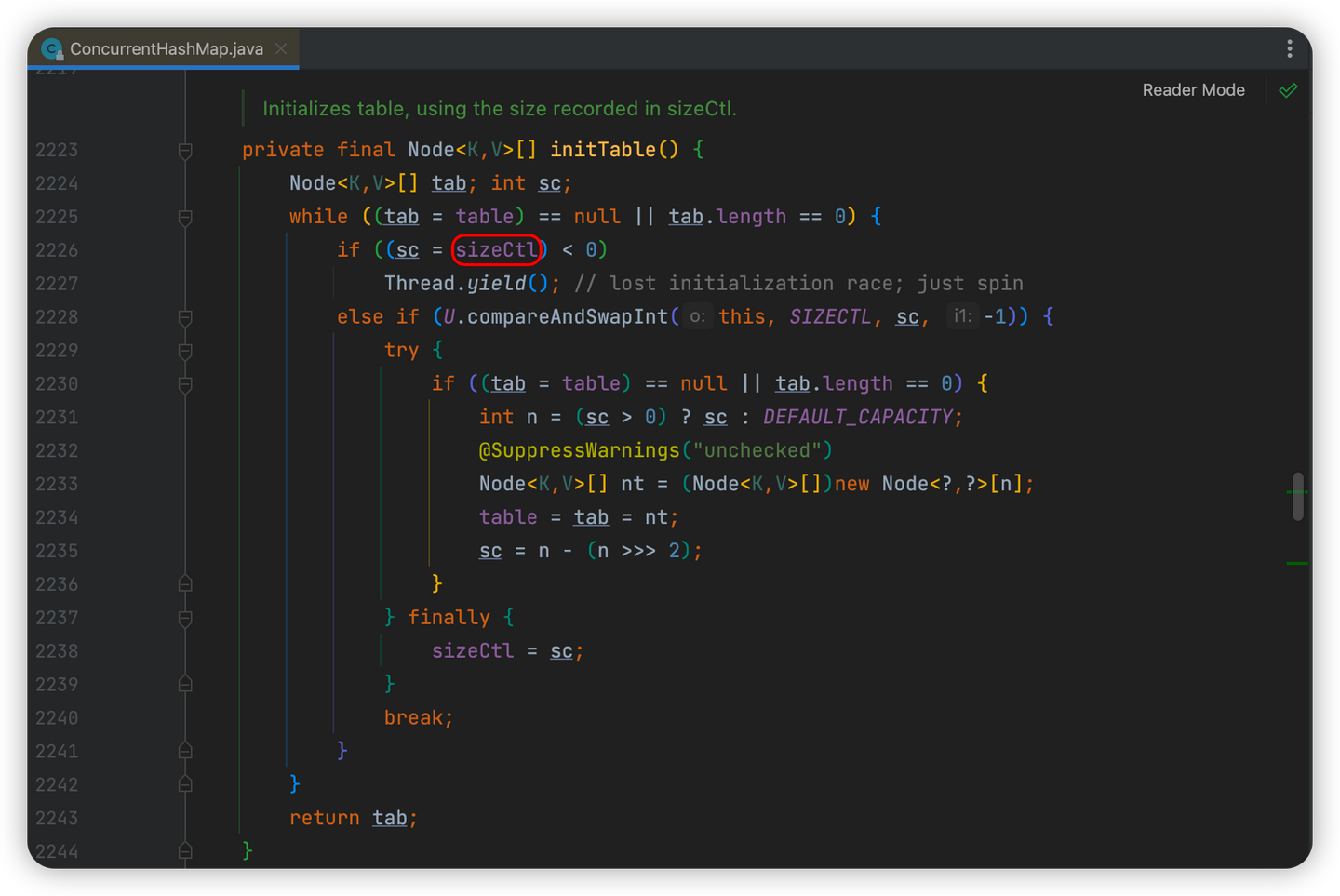
sizeCtl是数组在初始化和扩容操作时的一个控制变量,他的不同值代表不同含义:
-
>0:代表当前数组已经初始化完成,此时sizeCtl的值代表当前数组的扩容阈值,或者数组的初始化大小
-
0:代表当前数组还没初始化
-
-1:代表当前数组正在初始化
-
<-1:低16位代表当前数组正在扩容的线程个数
-
如果是1个线程,值就是-2
-
如果是2个线程,值就是-3
-
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
// 声明标识
Node<K,V>[] tab; int sc;
// 判断有没有初始化
while ((tab = table) == null || tab.length == 0) {
// 判断sizeCtl是否小于0,即是否已经有线程在进行初始化了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 如果sizeCtl等于0表示当前线程为第一个进入map的线程
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// U.compareAndSwapInt(this, SIZECTL, sc, -1) 以CAS的方式sizeCtl的值为-1
// 修改成功则开始初始化
try {
// DCL 再次判断当前数组是否已经初始化完成
if ((tab = table) == null || tab.length == 0) {
// 开始初始化
// sizeCtl>0 就初始化sizeCtl长度的数组
// sizeCtl=0 就初始化默认长度的数组
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 开始初始化
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 将sc赋值为下一次扩容的阈值
// 如果n=16 n>>>2=4 16-4=12
// 其实就是在当前数组的基础上,增加当前数组长度的0.75
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}在开始初始化前,会先判断下sizeCtl的值:
-
sizeCtl>0 就初始化sizeCtl长度的数组
-
sizeCtl=0 就初始化默认长度的数组

实际真正初始化的过程就是new Node<?,?>[n],然后赋值给成员变量,接着还会通过sc = n - (n >>> 2)计算下一次扩容的阈值,举个例子,如果n=16,n>>>2的值就是4,然后16-4就等于12,也就是说,下次再需要扩容,就会在原来的基础上增加12,其实也就是增加当前数组长度的0.75。
我们根据对上面源码的分析,梳理下初始化的大致流程:
基于一个while循环,先去判断数组初始化了没有,如果没有,会再次比较sizeCtl的情况,如果正在初始化,则会通过Thread.yield()让出CPU资源,如果没有初始化,则会通过CAS的方式修改sizeCtl的值为-1,修改过后还会再次判断数组是否被初始化了(DCL,以免在当前线程修改sizeCtl的值的时候,已经有别的线程对当前数组完成了初始化),如果当前数组仍然没有被初始化,才会真正开始初始化。
扩容流程
主要有3种方式会触发扩容
1. 执行treeifyBin()方法进行链表转红黑树前,会先尝试通过tryPresize()方法进行数组扩容
当链表长度>8时,会尝试将链表转为红黑树(文章第一部分提到的1.8的结构优化)
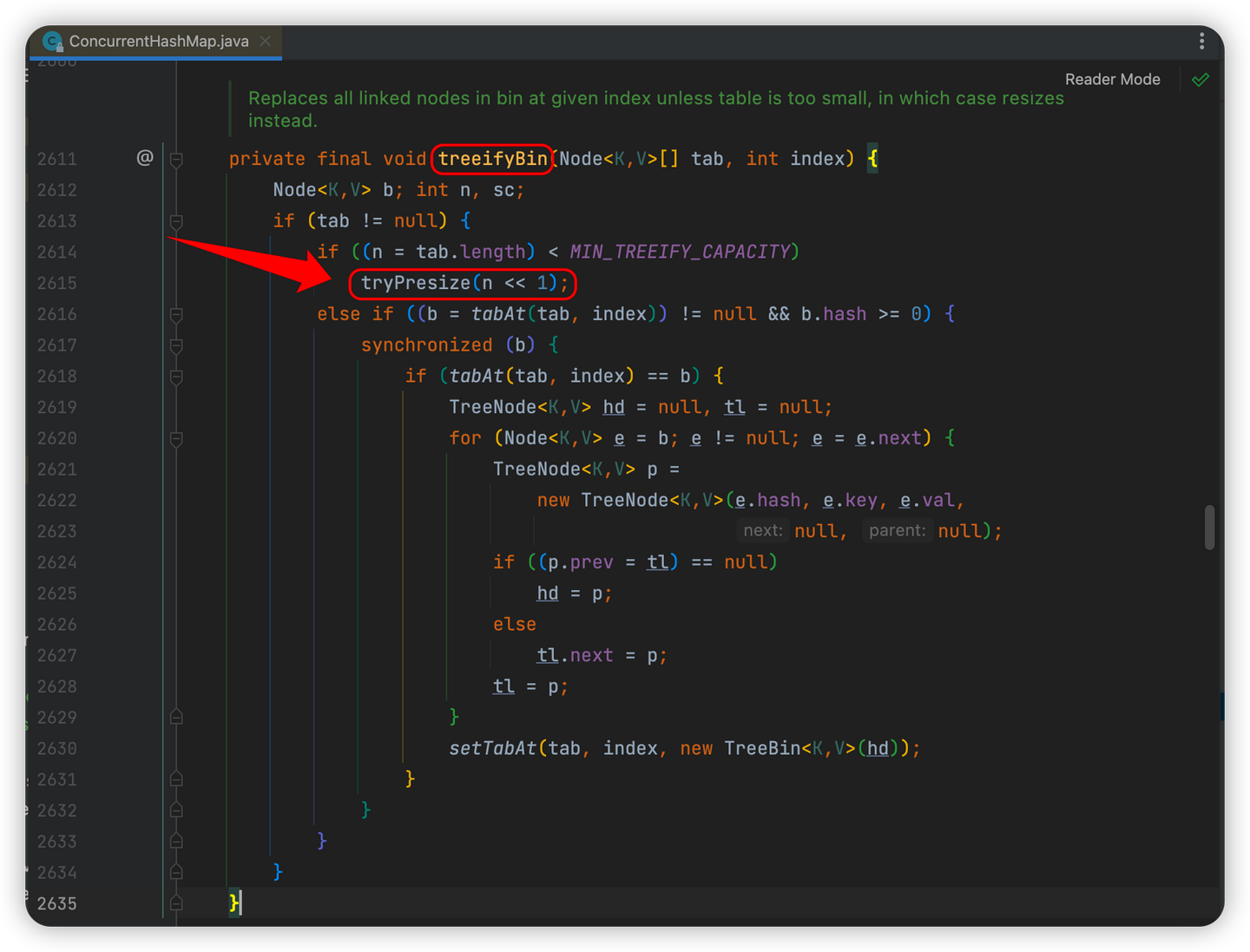
由上面的方法可以看到,在真正进行链表 -> 红黑树前,会先判断数组长度是否小于MIN_TREEIFY_CAPACITY即64

如果数组长度<64,会先尝试扩容操作
2. 执行putAll()方法时,会尝试通过tryPreSize()方法对数组进行扩容
putAll()方法会传入一个新Map,原先的数组很可能会不够用,因此出发扩容
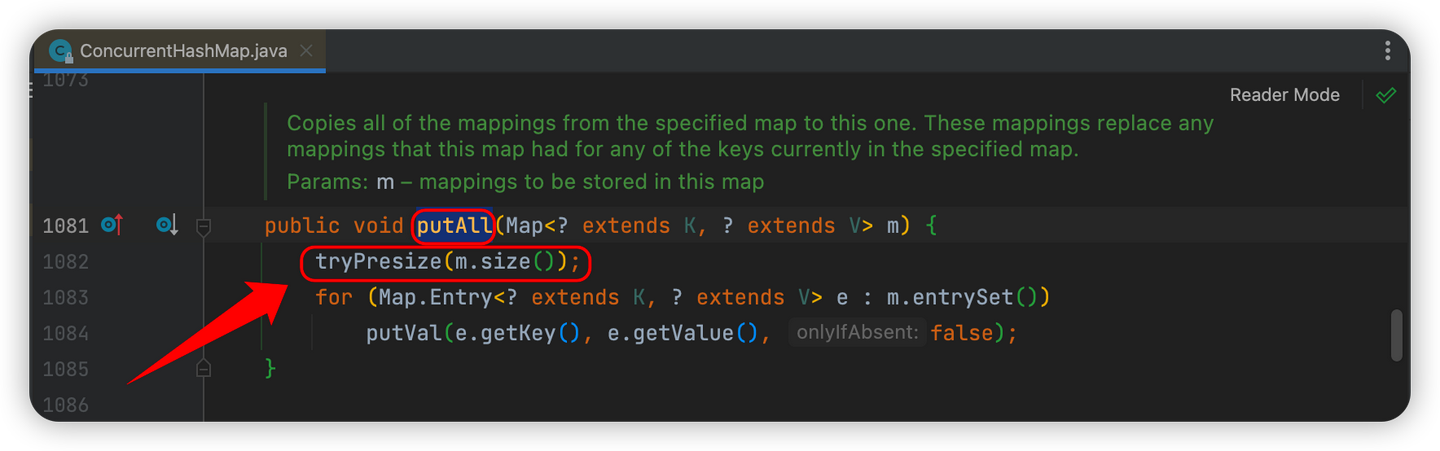
向tryPresize()中传入需要添加的Map的size
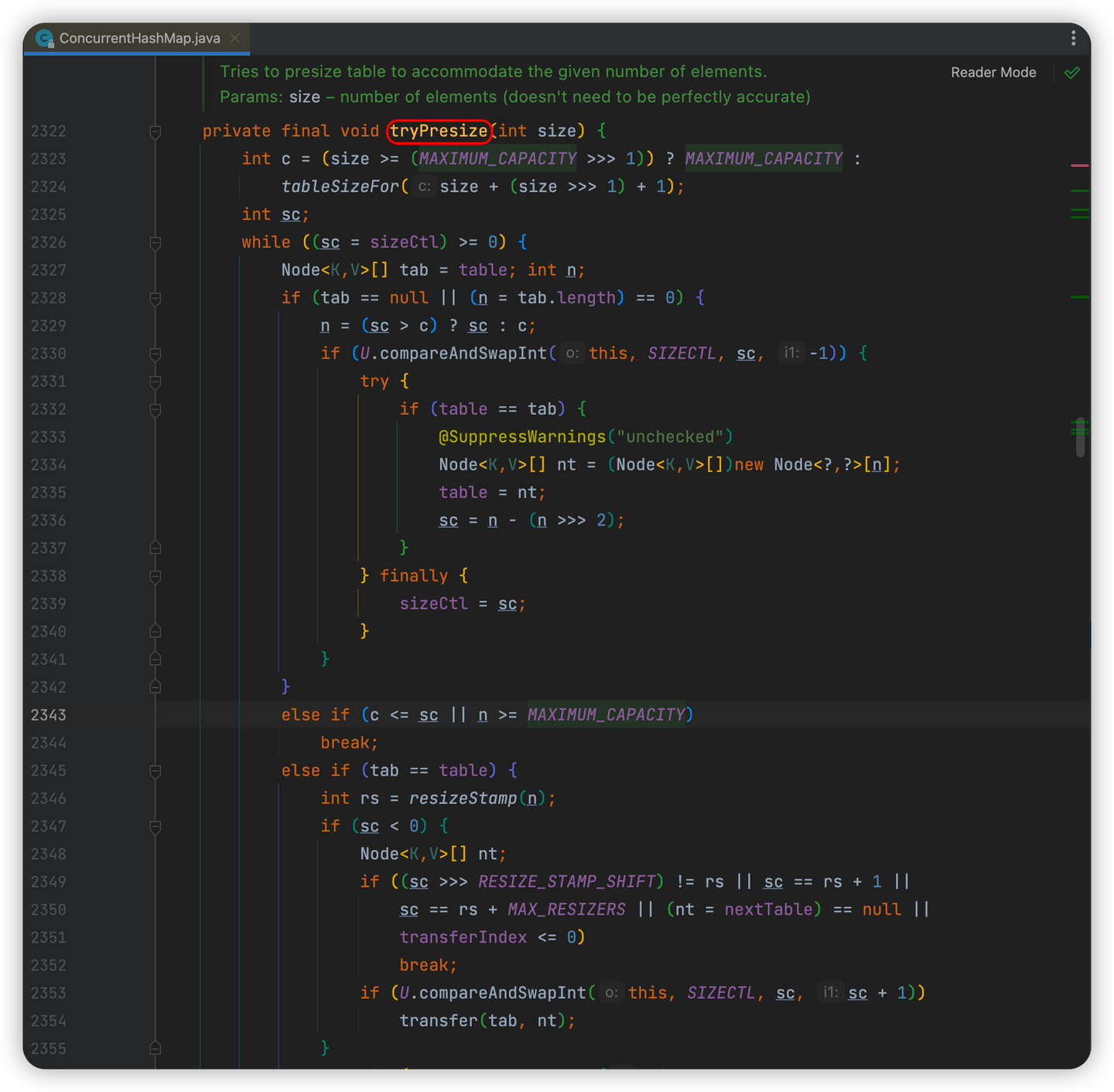
首先要确定扩容的大小

大于最大值就取最大值(MAXIMUM_CAPACITY),不是2^n就计算大于它且离他最近的2^n
接着就进入了while循环,这段循环内大致有3块逻辑
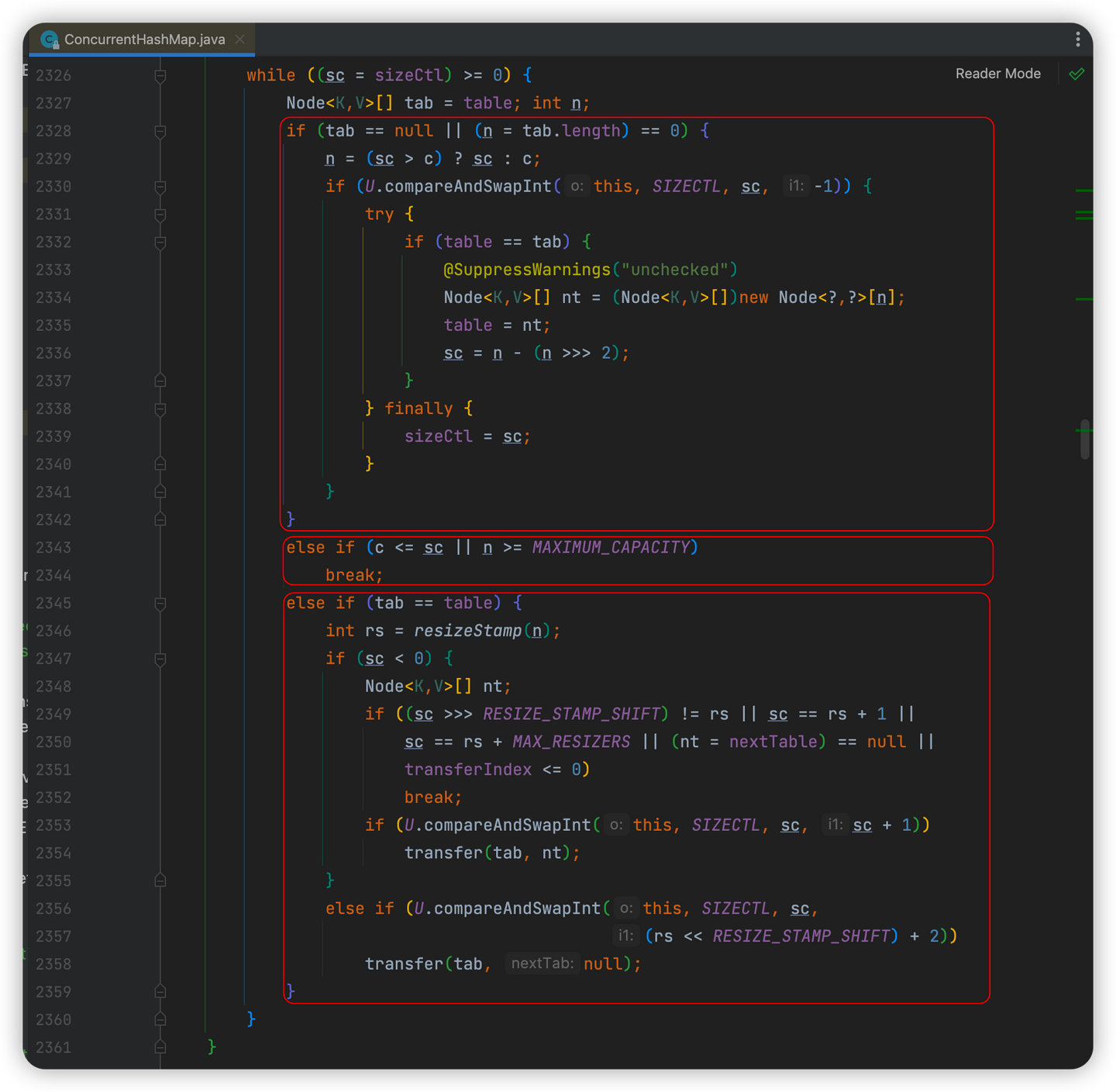
-
类似初始化的操作,可以参考上一部分初始化的代码分析
-
越界处理
-
扩容操作
-
计算扩容标识戳(用于协助扩容)
-
通过CAS修改sizeCtl的值来表示当前数组正在扩容中
-
transfer()实现扩容操作
-
3. 执行add()操作时,如果当前元素个数达到了扩容阈值,也会进行扩容
读取数据流程
ConcurrentHashMap的数据查询都是以get()方法为入口的,我们直接来看看这个get()方法
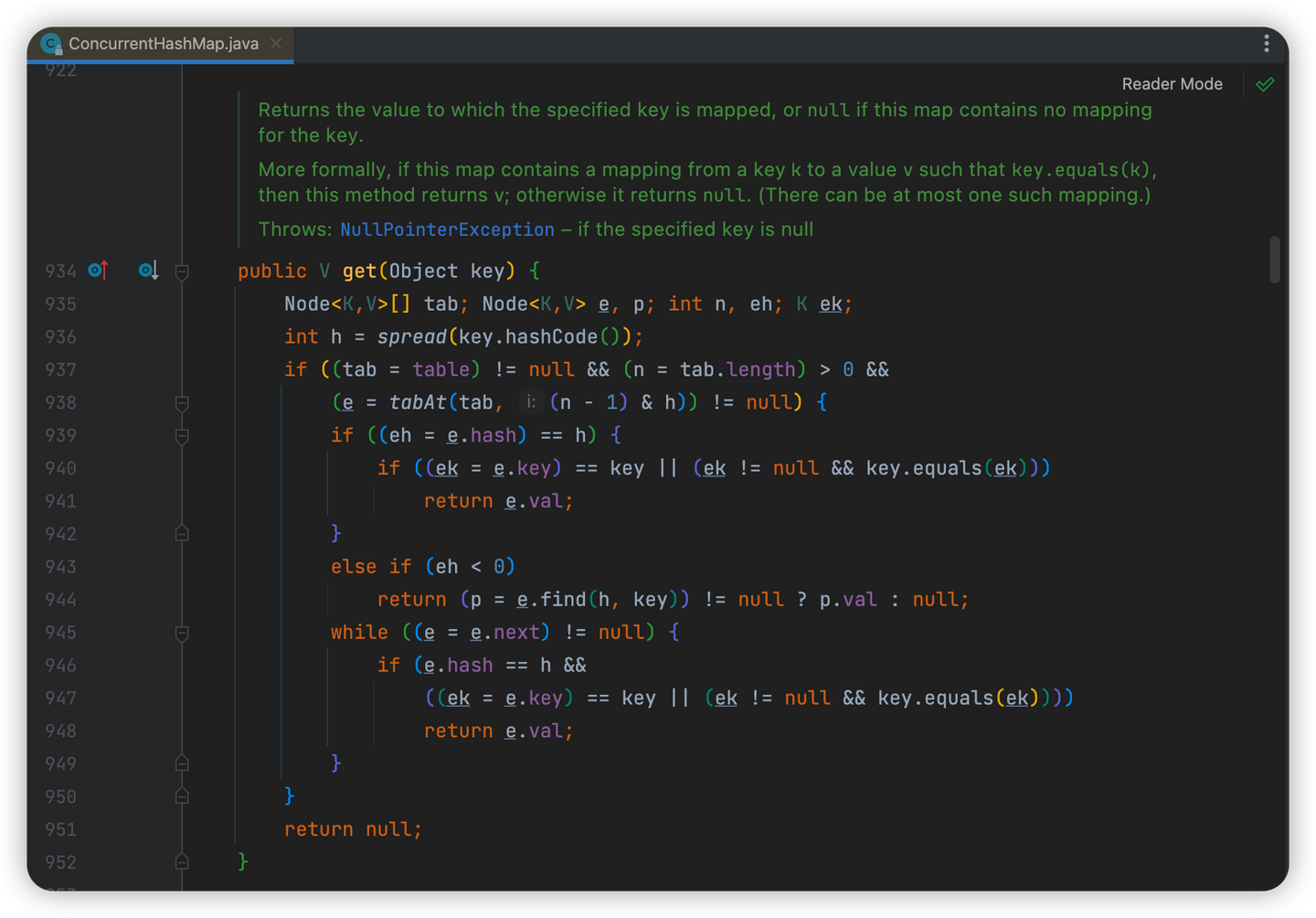
按上述源码,我们总结下查询流程:
-
先判断当前key对应的value是否在数组上(基于key计算hash值)
-
该位置数据为🈳️,数据不存在
-
返回null
-
-
该位置数据不为🈳️,数据存在
-
直接查询对应数组的位置上的数据
-
hash值一致 + key一致 -> 返回该value
-
hash值<0(特殊情况,会通过find()方法进行value的获取)
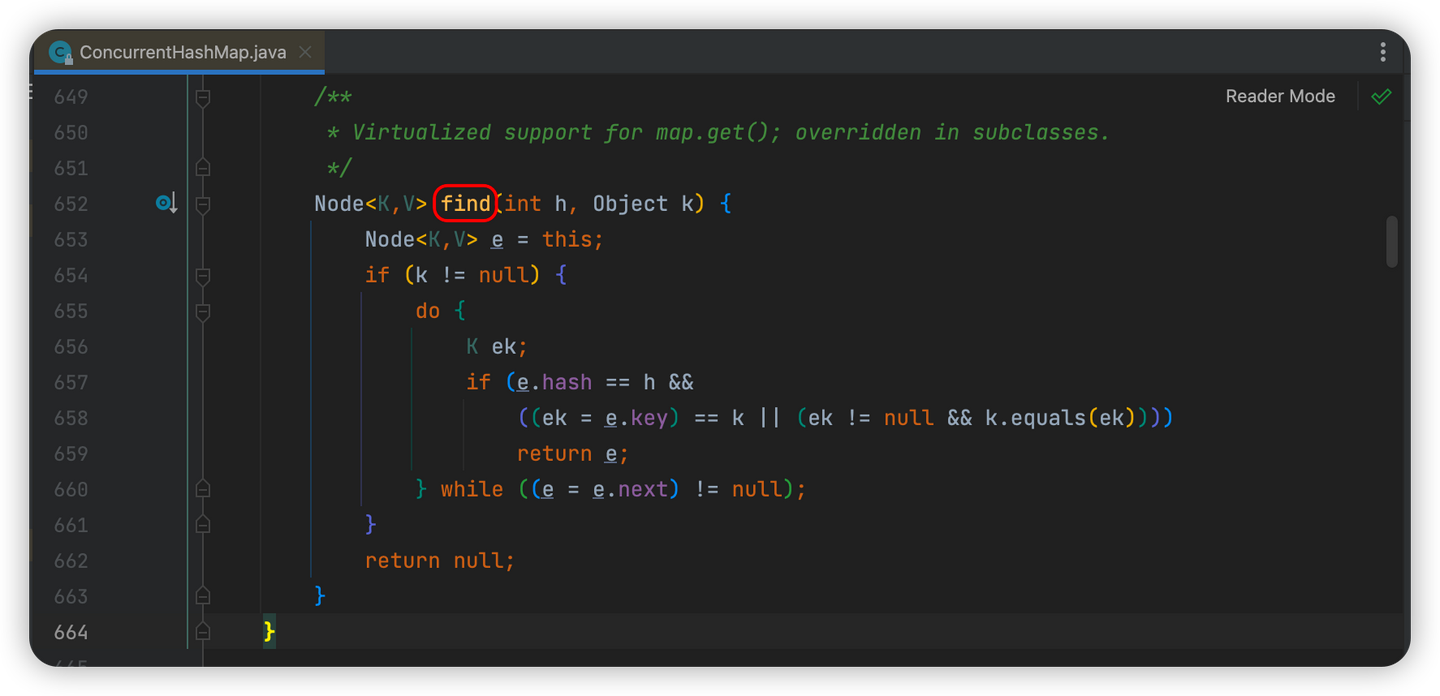
-
数据被迁移走了,此时会走ForwardingNode中对于find()方法的实现,方法中会到新数组nextTable中查询是否存在该value(逻辑类似)

-
节点位置被占
-
红黑树
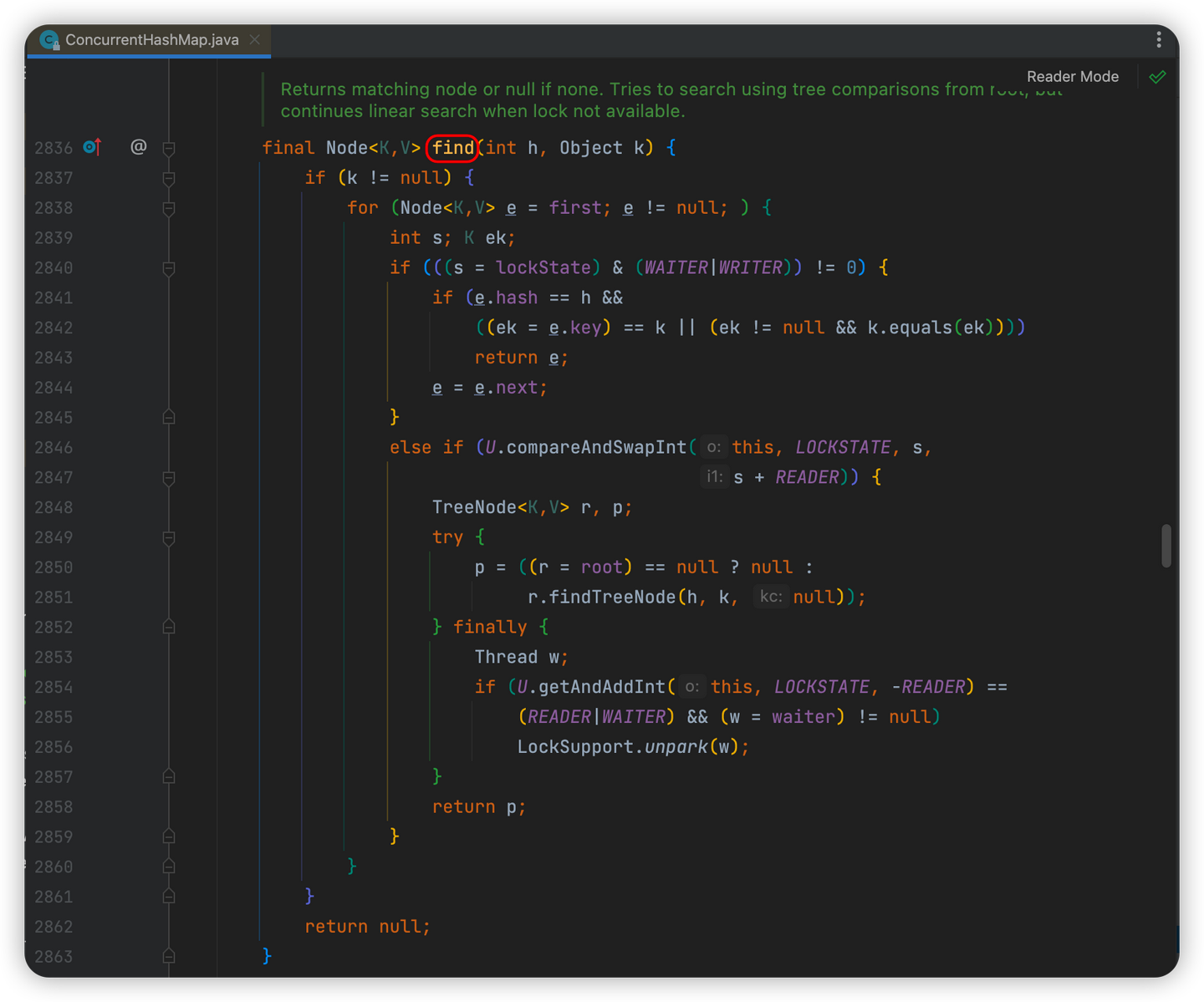
-
-
-
-
-
其他情况:数据在链表上
-
hash值一致 + key一致 -> 返回该value
-
-
上面的情况都不满足,返回null
计数器的实现
计数器是用来统计ConcurrentHashMap的元素个数的,通过addCount()方法实现 可以看到addCount()方法中有2个重要的对象:CounterCell[]数组和baseCount变量

他们是记录📝数据的两个位置:
-
并发量不高时,会通过baseCount进行追加
-
并发量较高时,CAS试图操作baseCount失败后,会切换到CounterCell[]数组来计数,有多个CounterCell可供不同的线程进行选择
当我们需要获取ConcurrentHashMap的元素个数时,会调用size()方法
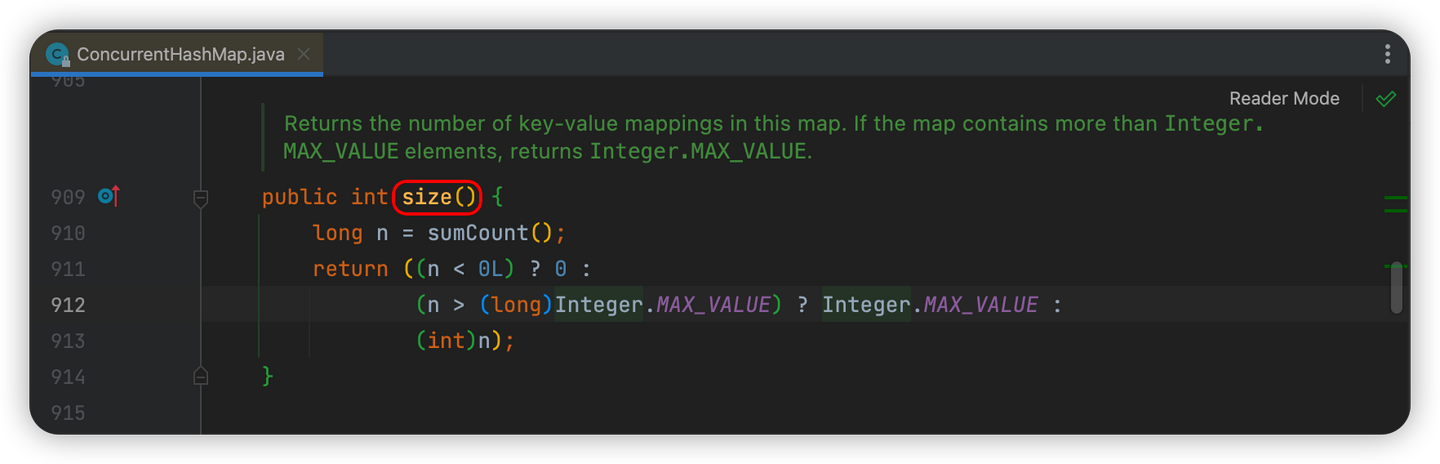
而size()方法中调用了sumCount()方法
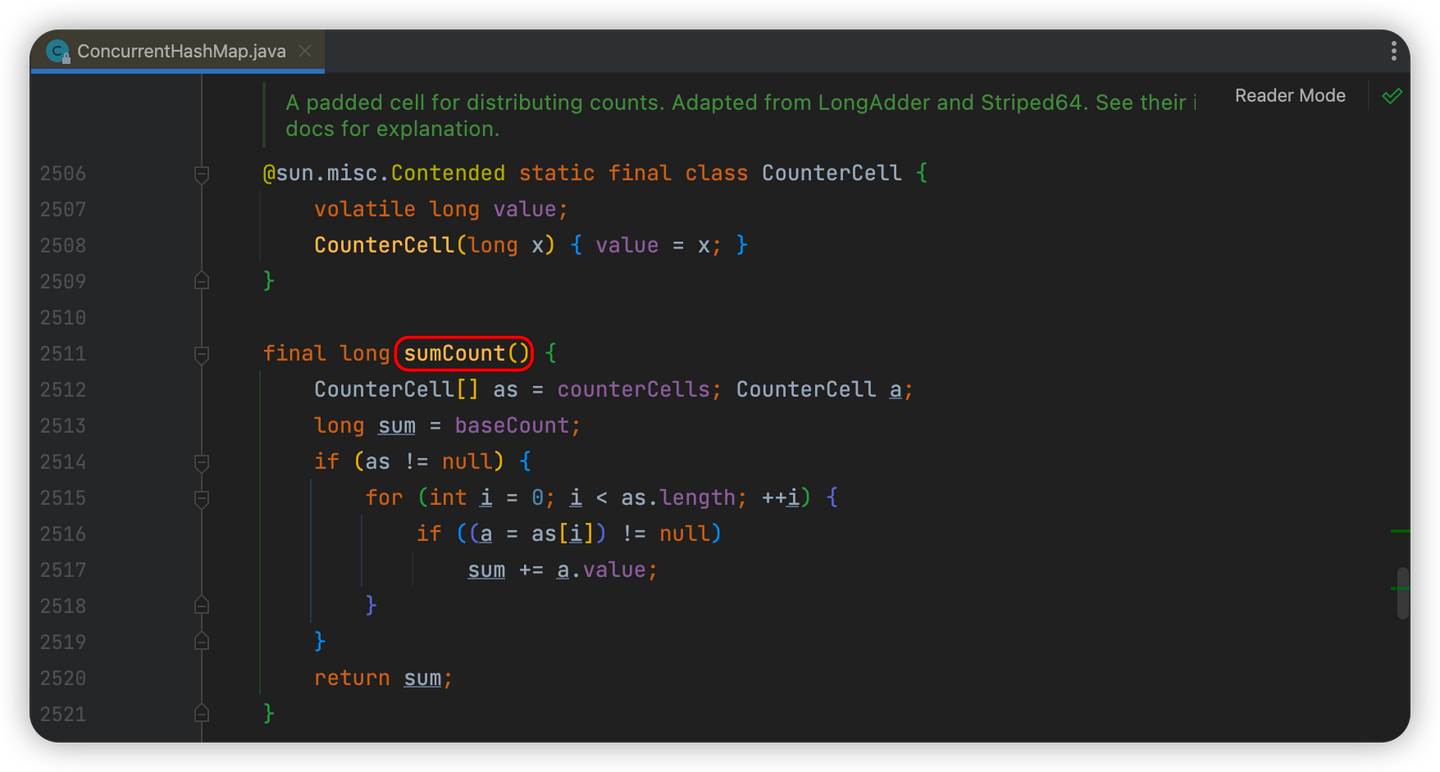
在sumCount()对baseCount还有数组CounterCell[]中的每一个记录进行累加,返回最终值
搞定( ̄∇ ̄)/🎉~~~~~