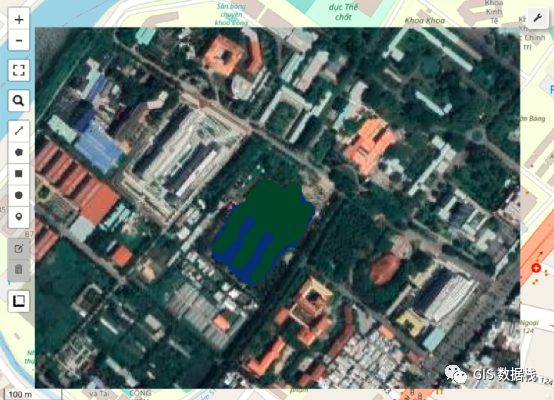
这是LLM系列相关综述文章的第二篇,针对《A Survey on In-context Learning》的翻译。
上下文学习综述
- 摘要
- 1 引言
- 2 概述
- 3 定义和公式
- 4 模型预热
- 4.1 监督上下文训练
- 4.2 半监督上下文训练
- 5 示例设计
- 5.1 示例组织
- 5.1.1 示例选择
- 5.1.2 示例排序
- 5.2 示例形式化
- 5.2.1 指令形式化
- 5.2.2 推理步骤形式化
- 6 评分函数
- 7 分析
- 7.1 什么影响ICL的表现
- 7.2 理解为什么ICL有效
- 8 评估与资源
- 8.1 传统任务
- 8.2 新的挑战任务
- 8.3 开源工具
- 9 超越文本的上下文学习
- 9.1 视觉上下文学习
- 9.2 多模态上下文学习
- 9.3 语音上下文学习
- 10 应用
- 11 挑战与未来的方向
- 11.1 新的预训练策略
- 11.2 ICL能力蒸馏
- 11.3 ICL鲁棒性
- 11.4 ICL效率和扩展性
- 12 结论
摘要
随着大型语言模型(LLM)能力的增强,上下文学习(ICL)已成为自然语言处理(NLP)的一种新范式,其中LLM仅基于通过几个例子增强的上下文进行预测。探索ICL来评估和推断LLM的能力已经成为一种新的趋势。在本文中,我们旨在调查和总结ICL的进展和挑战。我们首先给出了ICL的正式定义,并阐明了其与相关研究的相关性。然后,我们对先进技术进行了组织和讨论,包括训练策略、演示设计策略以及相关分析。最后,我们讨论了ICL面临的挑战,并为进一步的研究提供了潜在的方向。我们希望我们的工作能够鼓励更多关于揭示ICL如何工作和改进ICL的研究。
1 引言
随着模型大小和语料库大小的缩放,大型语言模型(LLM)展示了上下文学习(ICL)能力,即从上下文中的几个例子中学习。许多研究表明,LLM可以通过ICL执行一系列复杂的任务,例如解决数学推理问题。这些强大的能力已被广泛验证为大型语言模型的新兴能力。
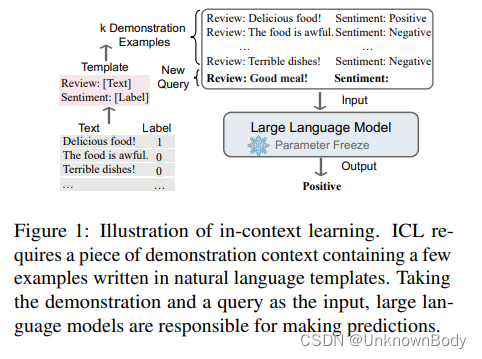
语境学习的核心思想是从类比中学习。图1给出了一个示例,描述了语言模型如何使用ICL进行决策。首先,ICL需要几个例子来形成一个演示上下文。这些例子通常是用自然语言模板编写的。然后,ICL将一个查询问题和一段演示上下文连接在一起形成提示,然后将其输入到语言模型中进行预测。与需要使用后向梯度更新模型参数的训练阶段的监督学习不同,ICL不进行参数更新,而是直接对预训练的语言模型进行预测。该模型被期望学习隐藏在演示中的模式,并相应地做出正确的预测。
ICL作为一种新的范式,具有多种吸引人的优势。首先,由于演示是用自然语言编写的,因此它提供了一个可解释的接口来与LLM通信。这种范式通过改变演示和模板,使人类知识更容易融入LLM。其次,情境学习类似于人类通过类比学习的决策过程。第三,与监督训练相比,ICL是一个无需训练的学习框架。这不仅可以大大降低模型适应新任务的计算成本,还可以使语言模型成为一种服务,并且可以很容易地应用于大规模的现实世界任务。
尽管前景广阔,但ICL中也有一些有趣的问题和有趣的性质需要进一步研究。虽然原始GPT-3模型本身显示出有希望的ICL能力,但几项研究观察到,在预训练过程中,这种能力可以通过适应得到显著提高。此外,ICL的性能对特定设置敏感,包括提示模板、上下文中示例的选择和示例的顺序等。此外,尽管直觉上是合理的,但ICL的工作机制仍不清楚,很少有研究提供初步解释。
随着ICL研究的快速增长,我们的调查旨在提高社区对当前进展的认识。具体而言,我们提供了一份详细的论文综述和一份将不断更新的论文清单,并对ICL的相关研究进行了深入讨论。我们强调了挑战和潜在的方向,并希望我们的工作可以为对该领域感兴趣的初学者提供有用的路线图,并为未来的研究提供线索。
2 概述
ICL的强大性能依赖于两个阶段:(1)培养LLM的ICL能力的训练阶段,以及(2)LLM根据特定任务演示进行预测的推理阶段。就训练阶段而言,LLM直接针对语言建模目标进行训练,例如从左到右生成。尽管这些模型没有专门针对上下文学习进行优化,但它们仍然表现出ICL的能力。现有的ICL研究基本上是以训练有素的LLM为主干,因此本次综述将不涉及预训练语言模型的细节。在推理阶段,由于输入和输出标签都用可解释的自然语言模板表示,因此有多个方向可以提高ICL的性能。本文将进行详细的描述和比较,例如选择合适的示例进行演示,并为不同的任务设计具体的评分方法。

我们按照上面的分类法组织ICL中的当前进展(如图2所示)。根据ICL的正式定义(§3),我们详细讨论了热身方法(§4)、演示设计策略(§5)和主要评分函数(§6)。§7深入讨论了当前关于揭开ICL背后秘密的探索。我们进一步为ICL提供了有用的评估和资源(§8),并介绍了ICL显示其有效性的潜在应用场景(§10)。最后,我们总结了挑战和潜在的方向(§11),并希望这能为该领域的研究人员铺平道路。
3 定义和公式
根据GPT-3的论文,我们提供了上下文学习的定义:In-context学习是一种允许语言模型学习任务的范式,只给出了几个演示形式的例子。从本质上讲,它通过使用训练有素的语言模型来估计以演示为条件的潜在答案的可能性。
形式上,给定查询输入文本
x
x
x和一组候选答案
Y
=
{
y
1
,
⋯
,
y
m
}
Y=\{y_1,\cdots,y_m\}
Y={y1,⋯,ym}(
Y
Y
Y可以是类标签或一组自由文本短语),预训练的语言模型
M
\mathcal{M}
M以具有最大得分的候选答案作为预测条件,条件是演示集
C
C
C。
C
C
C包含可选的任务指令
I
I
I和
k
k
k个演示示例;因此
C
=
{
I
,
s
(
x
1
,
y
1
)
,
⋯
,
s
(
x
k
,
y
k
)
}
C=\{I,s(x_1,y_1),\cdots,s(x_k,y_k)\}
C={I,s(x1,y1),⋯,s(xk,yk)}或
C
=
{
s
(
x
1
,
y
1
)
,
⋯
,
s
(
x
k
,
y
k
)
}
C=\{s(x_1,y_1),\cdots,s(x_k,y_k)\}
C={s(x1,y1),⋯,s(xk,yk)},其中
s
(
x
k
,
y
k
,
I
)
s(x_k,y_k,I)
s(xk,yk,I)是根据任务用自然语言文本编写的示例。候选答案
y
j
y_j
yj的可能性可以由具有模型
M
\mathcal{M}
M的整个输入序列的评分函数
f
f
f表示:
P
(
y
i
∣
x
)
≜
f
M
(
y
j
,
C
,
x
)
\begin{gather}P(y_i|x)\triangleq f_\mathcal{M}(y_j,C,x) \end{gather}
P(yi∣x)≜fM(yj,C,x)
最终的预测标签
y
^
\hat y
y^是候选答案中概率最高的:
y
^
=
arg max
y
i
∈
Y
P
(
y
j
∣
x
)
.
\begin{gather}\hat y=\argmax_{y_i\in Y}P(y_j|x). \end{gather}
y^=yi∈YargmaxP(yj∣x).
评分函数
f
f
f估计给出演示和查询文本的当前答案的可能性。例如,我们可以通过比较否定和肯定的表征概率来预测二元情感分类中的类标签。对于不同的应用,有许多
f
f
f变体,这将在§6中详细阐述。
根据定义,我们可以看到ICL与其他相关概念的区别。(1) 提示学习:提示可以是鼓励模型预测所需输出的离散模板或软参数。严格地说,ICL可以被视为提示调优的一个子类,其中演示是提示的一部分。刘等(2021)对提示学习进行了深入调查。然而,ICL不包括在内。(2) 小样本学习:小样本学习是一种通用的机器学习方法,它使用参数自适应来学习具有有限数量监督示例的任务的最佳模型参数。相反,ICL不需要参数更新,而是直接在预训练的LLM上执行。
4 模型预热
尽管LLM已经显示出很有前途的ICL能力,但许多研究也表明,通过预训练和ICL推理之间的连续训练阶段,ICL能力可以进一步提高,我们简称之为模型预热。预热是ICL的一个可选过程,它在ICL推理之前调整LLM,包括修改LLM的参数或添加额外的参数。与微调不同,预热的目的不是为特定任务训练LLM,而是增强模型的整体ICL能力。
4.1 监督上下文训练
为了增强ICL的能力,研究人员通过构建上下文训练数据和多任务训练,提出了一系列有监督的上下文微调策略。由于预训练目标没有针对上下文学习进行优化,Min等人提出了一种方法MetaICL来消除预训练和下游ICL使用之间的差距。经过预训练的LLM通过演示示例在广泛的任务中不断进行训练,这提高了其小样本的能力。为了进一步鼓励模型从上下文中学习输入标签映射,Wei等人提出了符号调整。这种方法在上下文输入标签对上微调语言模型,用任意符号(例如“foo/bar”)代替自然语言标签(例如“积极/消极情绪”)。因此,符号调整展示了利用上下文信息来覆盖先前语义知识的增强的能力。
此外,最近的工作表明了指令的潜在价值,并且有一个研究方向专注于监督指令调整。指令调整通过任务指令的训练来增强LLM的ICL能力。在通过自然语言指令模板表达的60多个NLP数据集上调整137B LaMDA PT,FLAN提高了零样本和小样本ICL的性能。与为每个任务构造几个演示示例的MetaICL相比,指令调优主要考虑任务的解释,并且更容易扩展。Chung等人和Wang等人提出用1000多条任务指令来扩大指令调整。
4.2 半监督上下文训练
利用原始语料库进行热身,Chen等人提出在下游任务中构建与ICL格式一致的自监督训练数据。他们将原始文本转换为输入输出对,探索四个自我监督的目标,包括掩蔽标记预测和分类任务。或者,PICL也利用了原始语料库,但采用了简单的语言建模目标,促进了基于上下文的任务推理和执行,同时保留了预训练模型的任务泛化能力。因此,PICL在有效性和任务可推广性方面优于Chen等人的方法。
结论:(1)监督训练和自我监督训练都提出在ICL推理之前训练LLM。关键思想是通过引入接近上下文学习的目标,弥合预训练和下游ICL格式之间的差距。与涉及演示的上下文微调相比,没有几个示例作为演示的指令微调更简单、更受欢迎。(2) 在某种程度上,这些方法都通过更新模型参数来提高ICL能力,这意味着原始LLM的ICL能力有很大的改进潜力。因此,尽管ICL并不严格要求模型预热,但我们建议在ICL推理之前添加一个预热阶段。(3) 当越来越多地扩大训练数据时,热身带来的性能提升会遇到一个平稳期。这种现象既出现在有监督的上下文中训练中,也出现在自我监督的上下文训练中,这表明LLM只需要少量的数据就可以适应在热身期间从上下文中学习。
5 示例设计
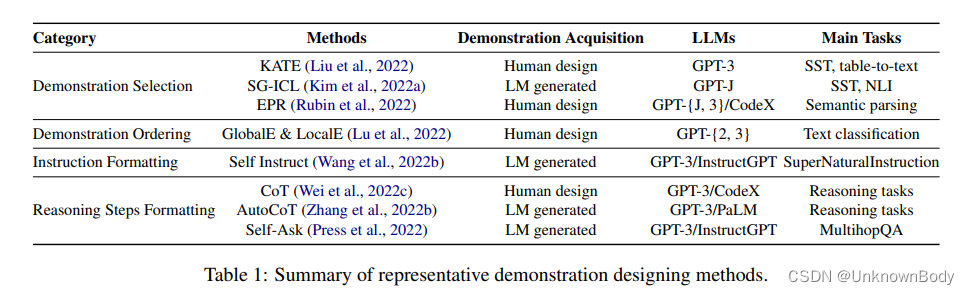
许多研究表明,ICL的性能在很大程度上依赖于演示面,包括演示格式、演示示例的顺序等。由于演示在ICL中发挥着至关重要的作用,在本节中,我们调查了演示设计策略,并将其分为两组:演示组织和演示格式,如表1所示。
5.1 示例组织
给定一组训练示例,演示组织将重点放在如何选择示例子集和所选示例的顺序上。
5.1.1 示例选择
示范选择旨在回答一个基本问题:哪些例子是ICL的好例子?我们将相关研究分为两类,包括基于预定义指标的无监督方法和有监督方法。
无监督方法
刘等人表明,选择最近的邻居作为上下文示例是一个很好的解决方案。距离度量是基于句子嵌入的预定义L2距离或余弦相似性距离。他们提出了KATE,一种基于kNN的无监督检索器,用于选择上下文示例。除了距离度量外,互信息也是一个有价值的选择度量。同样,可以为多语言ICL检索k-NN跨语言演示,以加强源-目标语言对齐。互信息的优点在于,它不需要标记的示例和特定的LLM。此外,Gonen等人试图选择困惑度较低的提示。Levy等人考虑了演示的多样性,以提高构造的泛化能力。他们选择不同的演示来涵盖不同类型的训练演示。与这些从人类标记数据中选择实例的研究不同,Kim等人提出从LLM本身生成演示。
其他一些方法利用LMs
P
(
y
∣
C
,
x
)
P(y|C,x)
P(y∣C,x)的输出分数作为无监督指标来选择演示。Wu et al.根据数据传输的码长选择kNN示例的最佳子集置换来压缩给定
x
x
x和
C
C
C的标签y,Nguyen和Wong通过计算演示子集
{
C
∣
x
i
∈
C
}
\{C|x_i\in C\}
{C∣xi∈C}和
{
C
∣
x
i
∉
C
}
\{C|x_i\notin C\}
{C∣xi∈/C}的平均性能之间的差异来测量演示
x
i
x_i
xi的影响。此外,李和邱(2023a)使用了infoscore,即具有多样性正则化的验证集中所有
(
x
,
y
)
(x,y)
(x,y)对的
P
(
y
∣
x
i
,
y
i
,
x
)
−
P
(
y
∣
x
)
P(y|x_i,y_i,x)-P(y|x)
P(y∣xi,yi,x)−P(y∣x)的平均值。
监督方法
Rubin等人提出了一种两阶段检索方法来选择演示。对于特定的输入,它首先构建了一个无监督检索器(例如,BM25)来回忆类似的例子作为候选者,然后构建了一种有监督检索器EPR来从候选者中选择演示。评分LM用于评估每个候选示例和输入的连接。高分的考生被标记为正面榜样,而低分的考生则被标记为硬性反面榜样。李等人通过采用统一的演示检索器来统一不同任务的演示选择,进一步增强了EPR。Ye等人检索了整个演示集,而不是单个演示,以建模演示之间的相互关系。他们通过对比学习训练DPP检索器与LM输出分数保持一致,并在推理时获得了具有最大后验性的最优证明集。
基于提示调整,Wang等人将LLM视为主题模型,可以从少量演示中推断概念
θ
\theta
θ,并基于概念变量
θ
\theta
θ生成词元。他们使用与任务相关的概念标记来表示潜在的概念。学习概念表征以使
P
(
y
∣
x
,
θ
)
P(y|x,\theta)
P(y∣x,θ)最大化。他们选择了最有可能根据
P
(
θ
∣
x
,
y
)
P(\theta|x,y)
P(θ∣x,y)推断概念变量的演示。此外,张等人还介绍了强化学习。以实例选择为例。他们将演示选择公式化为马尔可夫决策过程,并通过Q学习选择演示。动作是选择一个例子,奖励被定义为标记验证集的准确性。
5.1.2 示例排序
对选定的示范示例进行排序也是示范组织的一个重要方面。Lu等人已经证明,排序敏感性是一个常见的问题,并且对于各种模型总是存在。为了解决这个问题,先前的研究已经提出了几种无训练的方法来对演示中的示例进行排序。刘等人根据示例到输入的距离对其进行了适当的排序,因此最右边的演示是最接近的示例。Lu等人定义了全局和局部熵度量。他们发现熵度量和ICL性能之间存在正相关。他们直接使用熵度量来选择示例的最佳排序。
5.2 示例形式化
格式化演示的一种常见方式是将示例 ( x 1 , y 1 ) , ⋯ , ( x k , y k ) (x_1,y_1),\cdots,(x_k,y_k) (x1,y1),⋯,(xk,yk)通过模板 T \mathcal{T} T直接连接起来。然而,在一些需要复杂推理的任务中(例如,数学单词问题、常识推理),仅用k个演示就很难学习从 x i x_i xi到 y i y_i yi的映射。尽管在提示方面已经研究了模板工程,但一些研究人员旨在通过使用指令 I I I(§5.2.1)描述任务并在 x i x_i xi和 y i y_i yi之间添加中间推理步骤(§5.2.2)来设计更好的ICL演示格式。
5.2.1 指令形式化
除了精心设计的演示示例外,准确描述任务的良好指令也有助于推理性能。然而,与传统数据集中常见的演示示例不同,任务指令在很大程度上依赖于人工书写的句子。Honovich等人发现,给定几个演示示例,LLM可以生成任务指令。根据LLM的生成能力,周等人提出了用于指令自动生成和选择的自动提示工程师。为了进一步提高自动生成指令的质量,Wang等人提出使用LLM来引导自己的生成。现有的工作在自动生成指令方面取得了良好的效果,这为未来将人类反馈与自动生成指令相结合的研究提供了机会。
5.2.2 推理步骤形式化
Wei等人在输入和输出之间添加了中间推理步骤,以构建演示,称为思想链(CoT)。使用CoT,LLM预测推理步骤和最终答案。CoT提示可以通过将输入输出映射分解为许多中间步骤来学习复杂的推理。关于CoT提示策略的研究有很多,包括提示设计和过程优化。在本文中,我们主要关注CoT的设计策略。
与示范选择类似,CoT设计也考虑了CoT的选择。与Wei等人手动编写CoT不同,AutoCoT使用LLM和Let’s think step by step生成CoT。此外,傅等人提出了一种基于复杂性的演示选择方法。他们选择了具有更多推理步骤的演示来进行CoT提示。
由于输入输出映射被分解为逐步推理,一些研究人员将多阶段ICL应用于CoT提示,并为每个步骤设计CoT演示。多阶段ICL在每个推理步骤中使用不同的演示来查询LLM。Self-Ask允许LLM为输入生成后续问题,并问自己这些问题。然后,问题和中间答案将添加到CoT中。iCAP提出了一种上下文感知提示器,该提示器可以动态调整每个推理步骤的上下文。最少到最多提示是一个两阶段的ICL,包括问题约简和子问题求解。第一阶段将一个复杂的问题分解为子问题;在第二阶段,LLM依次回答子问题,之前回答的问题和生成的答案将添加到上下文中。
徐等人将特定任务中的小型LM作为插件进行微调,以生成伪推理步骤。给定一个输入输出对
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),SuperICL通过连接
(
x
i
,
y
i
′
,
c
i
,
y
i
)
(x_i,y'_i,c_i,y_i)
(xi,yi′,ci,yi)将输入
x
i
x_i
xi的小LM的预测
y
i
′
y'_i
yi′和置信
c
i
c_i
ci视为推理步骤。
要点:(1)示范选择策略提高了ICL的性能,但大多数都是实例级的。由于ICL主要在小样本设置下进行评估,因此语料库级别的选择策略更为重要,但尚未得到充分探索。(2) LLM的输出分数或概率分布在实例选择中起着重要作用。(3) 对于k个演示,排列的搜索空间的大小是
K
!
K!
K!。如何有效地找到最佳排序,或者如何更好地近似最优排名,也是一个具有挑战性的问题。(4) 添加思想链可以有效地将复杂的推理任务分解为中间推理步骤。在推理过程中,为了更好地生成CoT,采用了多阶段的演示设计策略。如何提高LLM的CoT提示能力也值得探索(5)除了人类书面演示外,LLM的生成性也可以用于演示设计。LLM可以生成指令、演示、探测集、思想链等等。通过使用LLM生成的演示,ICL可以在很大程度上摆脱编写模板的人工工作。
6 评分函数

评分函数决定了我们如何将语言模型的预测转化为特定答案可能性的估计。直接估计方法(direct)采用了候选答案的条件概率,该概率可以用语言模型词汇表中的标记表示。选择概率较高的答案作为最终答案。然而,这种方法对模板设计提出了一些限制,例如,答案标记应该放在输入序列的末尾。困惑度(PPL)是另一个常用的度量,它计算整个输入序列
S
j
=
{
C
,
s
(
x
,
y
i
,
I
)
}
S_j=\{C,s(x,y_i,I)\}
Sj={C,s(x,yi,I)}的句子困惑度,该序列由演示示例C、输入查询
x
x
x和候选标签
y
j
y_j
yj的标记组成。当PPL评估整个句子的概率时,它消除了标记位置的限制,但需要额外的计算时间。注意,在机器翻译等生成任务中,ICL通过解码具有最高句子概率的词元,结合波束搜索或Top-p和Top-k采样算法等多样性促进策略来预测答案。
与先前在给定输入上下文的情况下估计标签的概率的方法不同,Min等人提出利用信道模型(channel)来计算反向的条件概率,即,估计给定标签的输入查询的可能性。通过这种方式,需要语言模型来生成输入中的每一个词元,这可以在不平衡的训练数据机制下提高性能。我们在表2中总结了所有三个评分函数。由于ICL对演示很敏感(更多详细信息,请参见§5),通过在输入为空之前减去模型依赖项来规范化获得的分数,对于提高稳定性和整体性能也很有效。
另一个方向是结合超出上下文长度约束的信息来校准分数。结构化提示提出用特殊的位置嵌入单独编码演示示例,然后用重新缩放的注意力机制将其提供给测试示例。kNN Promoting首先用分布式表示的训练数据查询LLM,然后通过简单地引用具有封闭表示的最近邻居和存储的锚表示来预测测试实例。
要点:(1)我们在表2中总结了三种广泛使用的评分函数的特征。尽管直接采用候选答案的条件概率是有效的,但这种方法仍然对模板设计造成了一些限制。困惑也是一个简单而广泛的评分函数。该方法具有通用性,包括分类任务和生成任务。然而,这两种方法仍然对演示表面敏感,而Channel是一种补救措施,尤其适用于不平衡的数据制度。(2) 现有的评分函数都直接根据LLM的条件概率来计算分数。关于通过评分策略校准偏差或减轻敏感性的研究有限。例如,一些研究添加了额外的校准参数来调整模型预测。
7 分析

为了理解ICL,许多分析研究试图调查哪些因素可能影响性能,并旨在找出ICL工作的原因。我们在表3中总结了与ICL性能具有相对较强相关性的因素,以便于参考。
7.1 什么影响ICL的表现
预训练阶段
我们首先介绍LLM预训练阶段的影响因素。Shin等人研究了预训练语料库的影响。他们发现,领域来源比语料库大小更重要。将多个语料库放在一起可能会产生突发的ICL能力,对与下游任务相关的语料库进行预训练并不总是能提高ICL性能,困惑度较低的模型在ICL场景中也不总是表现得更好。魏等人研究了许多大型模型在多个任务上的涌现能力。他们认为,当预训练的模型达到大规模的预训练步骤或模型参数时,它会突然获得一些突发的ICL能力。Brown等人还表明,随着LLM参数从1亿增加到1750亿,ICL能力也在增长。
推理阶段
在推理阶段,演示样本的特性也会影响ICL的性能。Min等人研究了演示样本的影响来自四个方面:输入标签配对格式、标签空间、输入分布和输入标签映射。他们证明了所有的输入标签配对格式、标签空间的暴露和输入分布对ICL性能有很大贡献。与直觉相反,输入标签映射对ICL来说无关紧要。就输入标签映射的影响而言,Kim等人得出了相反的结论,即正确的输入标签映射确实会影响ICL的性能,这取决于具体的实验设置。Wei等人进一步发现,当一个模型足够大时,它将表现出学习输入标签映射的突发能力,即使标签被翻转或语义无关。从组成概括的角度来看,An等人验证了ICL演示应该是多样的、简单的,并且在结构方面与测试示例相似。鲁等人指出,示范样本顺序也是一个重要因素。此外,刘等人发现,嵌入距离查询样本较近的演示样本通常比嵌入距离较远的演示样本带来更好的性能。
7.2 理解为什么ICL有效
训练数据的分布
集中在预训练数据上,Chan等人表明ICL能力是由数据分布特性驱动的。他们发现,当训练数据中有集群中出现的例子并且有足够的稀有类时,ICL能力就会出现。谢等人将ICL解释为隐式贝叶斯推理,并构建了一个合成数据集来证明当预训练分布遵循隐马尔可夫模型的混合时,ICL能力就会出现。
学习机制
通过学习线性函数,Garg等人根据演示样本证明了Transformers可以编码有效的学习算法来学习看不见的线性函数。他们还发现,ICL模型中编码的学习算法可以实现与最小二乘估计器相当的误差。李等人将ICL抽象为一个算法学习问题,并表明Transformers可以通过隐式经验风险最小化来实现适当的函数类。潘等人将ICL能力解耦为任务识别能力和任务学习能力,并进一步展示了它们如何利用演示。从信息论的角度来看,Hahn和Goyal在语言驱动的假设下展示了ICL的误差界,以解释下一个表征预测如何带来ICL能力。Si等人发现,大型语言模型表现出先前的特征偏差,并展示了一种使用干预来避免ICL中意外特征的方法。
另一系列工作试图在ICL和梯度下降之间建立联系。以线性回归为出发点,Akyürek等人发现,基于Transformer的上下文学习器可以隐式地实现标准微调算法,von Oswald等人表明,只有线性注意力的Transformer与手动构建的参数和通过梯度下降学习的模型高度相关。基于softmax回归,李等人发现,仅自我注意的Transformer与通过梯度下降学习的模型表现出相似性。戴等人发现了Transformer注意力和梯度下降之间的双重形式,并进一步提出将ICL理解为隐式微调。此外,他们比较了基于GPT的ICL和对实际任务的显式微调,发现从多个角度来看,ICL的行为确实与微调类似。
功能组件
专注于特定的功能模块,Olsson等人发现Transformer中存在一些感应头,它们复制以前的模式来完成下一个词元。此外,他们将感应头的功能扩展到更抽象的模式匹配和完成,这可能会实现ICL。王等人重点研究了Transformer中的信息流,发现在ICL过程中,演示标签词充当锚,为最终预测聚合和分发关键信息。
要点:(1)了解和考虑ICL的工作方式可以帮助我们提高ICL的性能,表3列出了与ICL性能密切相关的因素。(2) 尽管一些分析研究已经为解释ICL迈出了初步的一步,但它们大多局限于简单的任务和小模型。对大量任务和大型模型进行扩展分析可能是需要考虑的下一步。此外,在现有的工作中,用梯度下降解释ICL似乎是一个合理、普遍和有前景的未来研究方向。如果我们在ICL和基于梯度下降的学习之间建立明确的联系,我们可以借鉴传统深度学习的历史来改进ICL。
8 评估与资源
8.1 传统任务
作为一种通用的学习范式,ICL可以在各种传统数据集和基准上进行检查,例如SuperGLUE、SQuAD。Brown等人在SuperGLUE上用32个随机采样的例子实现ICL。发现,GPT3在COPA和ReCoRD上可以获得与最新状态(SOTA)微调性能相当的结果,但在大多数NLU任务上仍然落后于微调。Hao等人显示了扩大示范示例数量的潜力。然而,缩放带来的改进是非常有限的。目前,与微调相比,ICL在传统的NLP任务上仍有一些空间。
8.2 新的挑战任务
在具有上下文学习能力的大型语言模型时代,研究人员更感兴趣的是在没有下游任务微调的情况下评估大型语言模型的内在能力。
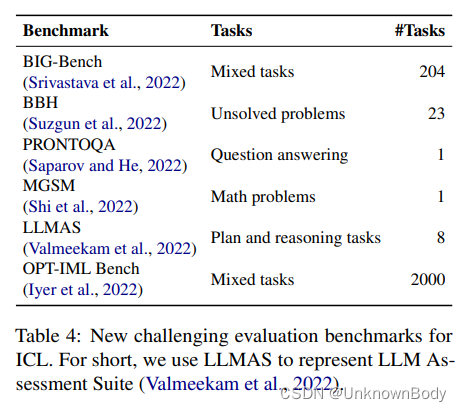
为了探索LLM在各种任务上的能力限制,Srivastava等人提出了BIG Bench,这是一个涵盖广泛任务的大型基准,包括语言学、化学、生物学、社会行为等。通过ICL,在65%的BIG Bench任务中,最佳模型已经超过了平均报告的人工评分结果。为了进一步探索当前语言模型实际上无法解决的任务,Suzgun等人提出了一个更具挑战性的ICL基准,即BIG Bench Hard(BBH)。BBH包括23个未解决的任务,通过选择最先进的模型性能远低于人类性能的具有挑战性的任务来构建。此外,研究人员正在搜索逆缩放任务,也就是说,当放大模型大小时,模型性能会降低的任务。这些任务也突出了ICL当前范式的潜在问题。为了进一步探索模型的泛化能力,Iyer等人提出了OPT-IML Bench,由8个现有基准的2000个NLP任务组成,特别是ICL在保留类别上的基准。
具体而言,一系列研究集中在探索ICL的推理能力。Saparov和He从一阶逻辑中表示的合成世界模型中生成了一个例子,并将ICL生成解析为符号证明,用于形式分析。他们发现LLM可以通过ICL做出正确的个人推断步骤。施等人构建了MGSM基准来评估LLM在多语言环境中的思维链推理能力,发现LLM表现出跨多种语言的复杂推理。为了进一步探索LLM更复杂的规划和推理能力,Valmickam等人提供了多个测试案例,用于评估行动和变化的各种推理能力,其中现有的LLM ICL方法表现出较差的性能。
8.3 开源工具
注意到ICL方法通常以不同的方式实现,并使用不同的LLM和任务进行评估,Wu等人开发了OpenICL,这是一个开源工具包,能够实现灵活统一的ICL评估。凭借其适应性强的体系结构,OpenICL促进了不同组件的组合,并提供了最先进的检索和推理技术,以加速ICL与高级研究的集成。
要点:(1)由于ICL对演示示例数量的限制,传统的评估任务必须适应小样本设置;否则,传统的基准无法直接评估LLM的ICL能力。(2) 由于ICL是一种在许多方面不同于传统学习范式的新范式,因此对ICL的评价提出了新的挑战和机遇。面对挑战,现有评估方法的结果是不稳定的,尤其是对演示示例和说明敏感。Chen等人观察到,现有的准确性评估低估了ICL对指令扰动的敏感性。进行一致的ICL评估仍然是一个悬而未决的问题,而OpenICL代表了应对这一挑战的宝贵初步尝试。对于评估的机会,由于ICL只需要几个实例进行演示,它降低了评估数据构建的成本。
9 超越文本的上下文学习
ICL在NLP中的巨大成功激发了研究人员在不同模式下探索其潜力,包括视觉、视觉+语言和语音任务。
9.1 视觉上下文学习

Bar等人使用掩码自动编码器(MAE)在网格状图像中使用图像块填充任务来训练其模型。在推理阶段,该模型生成与所提供的新输入图像的输入输出示例一致的输出图像,展示了ICL在图像分割等看不见的任务中有希望的能力。Painter通过结合多个任务来构建多面手模型,扩展了这种方法,与特定任务模型相比,实现了有竞争力的性能。在此基础上,SegGPT将不同的分割任务集成到一个统一的框架中,并从空间和特征的角度研究集成技术,以提高提示示例的质量。王等人提出利用额外的文本提示来引导生成模型综合生成所需图像。由此产生的提示扩散模型是第一个表现出ICL能力的基于扩散的模型。图3说明了用于上下文中视觉学习的仅图像提示和上下文中增强的文本提示之间的关键区别。
与NLP中的ICL类似,视觉上下文学习的有效性受到上下文演示图像的选择的显著影响。为了解决这一问题,张等人研究了两种方法:(1)使用现成模型选择最近样本的无监督检索器,以及(2)训练额外检索器模型以最大化ICL性能的有监督方法。检索到的样本显著提高了性能,表现出与查询的语义相似性,以及在视点、背景和外观方面更紧密的上下文对齐。除了提示检索之外,Sun等人进一步探索了一种用于改进结果的提示融合技术。
9.2 多模态上下文学习
在视觉语言领域,Tsimpoukeli等人利用视觉编码器将图像表示为前缀嵌入序列,该前缀嵌入序列在配对的图像字幕数据集上训练后与冻结的语言模型对齐。由此产生的模型Frozen能够执行多模态小样本学习。此外,Alayrac等人介绍了Flamingo,它将视觉编码器与LLM相结合,并采用LLM作为通用接口,在许多多模式任务上执行上下文学习。他们表明,在具有任意交错文本和图像的大规模多模态网络语料库上进行训练是赋予它们上下文小样本学习能力的关键。Kosmos-1是另一种多模式LLM,显示出很有前途的零样本、小样本甚至多模式思维链提示能力。Hao等人介绍了METALM,一种跨任务和模式建模的通用接口。METALM以半因果语言建模为目标,经过预训练,在各种视觉语言任务中表现出强大的ICL性能。
通过指令调优进一步增强ICL能力是很自然的,这一想法也在多模式场景中进行了探索。最近的探索首先生成指令调整数据集,转换现有的视觉语言任务数据集或具有GPT-4等强大LLM,并将LLM与这些多模态数据集上的BLIP-2等强大视觉基础模型连接起来。
9.3 语音上下文学习
在语音领域,王等人将文本到语音的合成视为一项语言建模任务。他们使用音频编解码器代码作为中间表示,并提出了第一个具有强大上下文学习能力的TTS框架。随后,VALLE-X将该思想扩展到多语言场景,在零样本跨语言文本到语音合成和零样本语音转换任务中表现出卓越的性能。
要点:(1)最近的研究探索了自然语言之外的语境学习,取得了可喜的成果。正确格式化的数据(例如,用于视觉语言任务的交错图像-文本数据集)和架构设计是激活上下文学习潜力的关键因素。在更复杂的结构化空间(如图形数据)中探索它是具有挑战性和前景的。(2) 语境中的文本学习示范设计和选择的发现不能简单地转移到其他模式。需要进行特定领域的调查,以充分利用各种形式的情境学习的潜力。
10 应用
ICL在传统的NLP任务和方法上表现出优异的性能,如机器翻译、信息提取和文本到SQL。特别是,通过明确指导推理过程的演示,ICL在需要复杂推理的任务上表现出显著的效果和合成概括。
此外,ICL为元学习和指令优化等流行方法提供了潜力。Chen等人将ICL应用于元学习,适应具有冻结模型参数的新任务,从而解决了复杂的嵌套优化问题。(Ye等人)通过将非文本学习应用于教学学习,增强了预处理模型和教学网络模型的零样本任务泛化性能。
具体而言,我们探讨了ICL的几个新兴和流行的应用,在以下段落中展示了它们的潜力。
数据工程
ICL已经显示出在数据工程中广泛应用的潜力。得益于强大的ICL能力,使用GPT-3的标签比使用人类的标签进行数据注释的成本低50%至96%。将GPT-3的伪标签与人类标签相结合,可以以较小的成本获得更好的性能。在更复杂的场景中,如知识图谱构建,Khorashadizadeh等人已经证明,ICL有潜力显著提高知识图谱的自动构建和完成的技术水平,从而以最小的工程工作量降低人工成本。因此,在各种数据工程应用程序中利用ICL的功能可以产生显著的好处。与人工注释(例如,众包)或嘈杂的自动注释(例如远程监督)相比,ICL以低成本生成相对高质量的数据。然而,如何使用ICL进行数据注释仍然是一个悬而未决的问题。例如,Ding等人进行了全面分析,发现基于生成的方法在使用GPT-3时比通过ICL注释未标记的数据更具成本效益。
模型增强
ICL的上下文灵活性显示了增强检索增强方法的巨大潜力。通过保持LM架构不变并为输入准备基础文档,在上下文中,RALMRam等人有效地利用了现成的通用检索器,从而在各种模型大小和不同的语料库中获得了显著的LM增益。此外,用于检索的ICL也显示出提高安全性的潜力。除了效率和灵活性外,ICL还显示出安全性潜力,(Meade等人)使用ICL进行检索演示,以引导模型朝着更安全的生成发展,减少模型中的偏差和毒性。