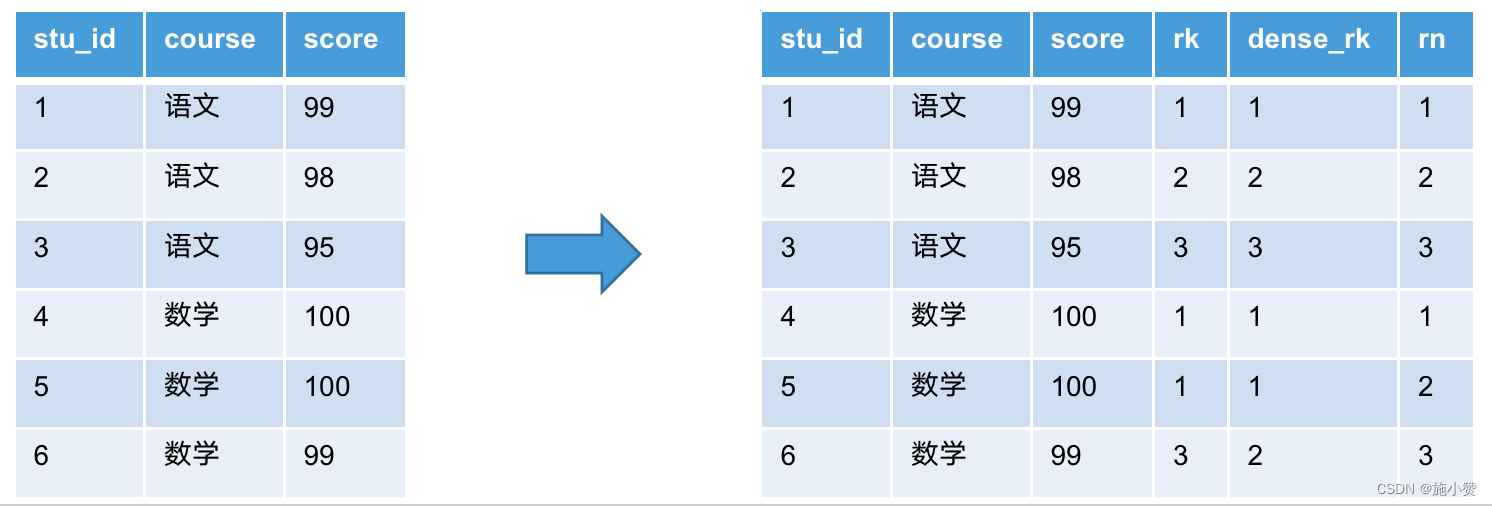
serde库提供序列化(serialize)和反序列化(deserialize)的特征,通过derive生成,可以把rust的自定义类型(struct)转换成多种常用的兼容类型例如JSON、CBOR、bincode,用于在网络间传输,其中JSON是比较常用的类型,特点是兼顾human-readable和machine-readable,另外两种仅仅是machine-readable,Page215给了一个范例;- 检索一个文件的内容采用hexdump的方式,把一系列字节流转化成2个16进制的数字(也就是正好一个字节),这种视图叫做fview(file view文件视图),表7.2展示了一个fview的输入和输出

- 多行字符串作为原始字符串时(raw string)不需要将双引号转义,原始字符串的pattern是前缀
r,分隔符#,还有额外的前缀b表示后面的字符串要看作字节(&[u8])而不是UTF-8字符(&str),下图是一个例子
f.read_exact(&mut buffer)方法把数据从源头f到buffer中,当buffer满的时候才会停止,如果buffer比f中的数据要长,会返回一个error;std::env::args()用于读命令行的参数;std::fs::OpenOptions可以用来创建可写的文件,与File::open和File::create不同,它可以定制化一些功能,open和create的区别如下表所示
- 处理文件路径的时候推荐使用
Path库,有3个好处,a.明确开发者的意图,例如set_extension()方法能设置扩展名;b. 多平台兼容性,不同的操作系统对文件路径的处理不通,例如有的操作系统对文件名的大小写敏感而有的不,还有不同的操作系统对路径分隔符的使用也不同;c. 易于debug,Path库提供了很多好用的API来处理文件路径;下表给出了一个对比std::String和std::path::Path处理文件路径的区别
- 7.5节简单构建了一个内存数据库的项目,介绍了
cargo.toml中lib和bin的使用规则以及调用路径,是一个小而全的软件工程实践项目,对于个人开发rust工具有很大的启发,Page222; - 7.6.1节介绍了条件编译(conditional compilation)的用法,在需要条件编译的语句上方加入
#[cfg(target_os="windows")]可以让该语句仅在windows系统下编译,对于·非·操作,没有!=符号,而是#[cfg(not(...))],可以设置的编译条件还有target_arch、target_env等,详见Page227; std::io::ErrorKind::UnexpectedEof错误是当程序读到文件结尾时报的错误,EOF是一个0字节(0u8),在文件结尾没有一个特殊的标记来表示文件已经结束,因此读到结尾无法再继续读的时候会抛出这个错误;- 7.7.3节介绍了写入二进制数据到磁盘中的顺序问题,可以制定大端/小端写入的方式,注意
i8, u8这样的数据是不用制定大端小端的,因为只有一个字节,像u32, f64这种就可以指定,写入效果可见Page233; - 7.7.3节介绍了写入磁盘的校验方法,常见的3种是奇偶校验法(parity bit)、循环冗余法(CRC32)、加密哈希法(Cryptographic hash function),他们之间的对比如下表所示

Rust in Action笔记 第七章 文件和存储
news2026/2/12 14:02:43
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/688176.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

多商户商城系统源码-加速度jsudo
为了能顺应时代的改变,很多企业都想要搭建一个类似天猫京东类型的b2b2c商城平台,但苦于没有专业的技术,所以他们都会选择成熟的b2b2c商城系统,但市面上的商城系统如此的多,如何选择呢?下面jsudo小编就来教…

函数式编程相关概念介绍
什么是函数式编程
函数式编程(Functional Programming)也称函数程序设计是一种编程范式,它将电脑运算视为函数运算,并且避免使用程序状态以及可变物件。 在js中,函数是一等公民,函数本身既可以作为其他函数…
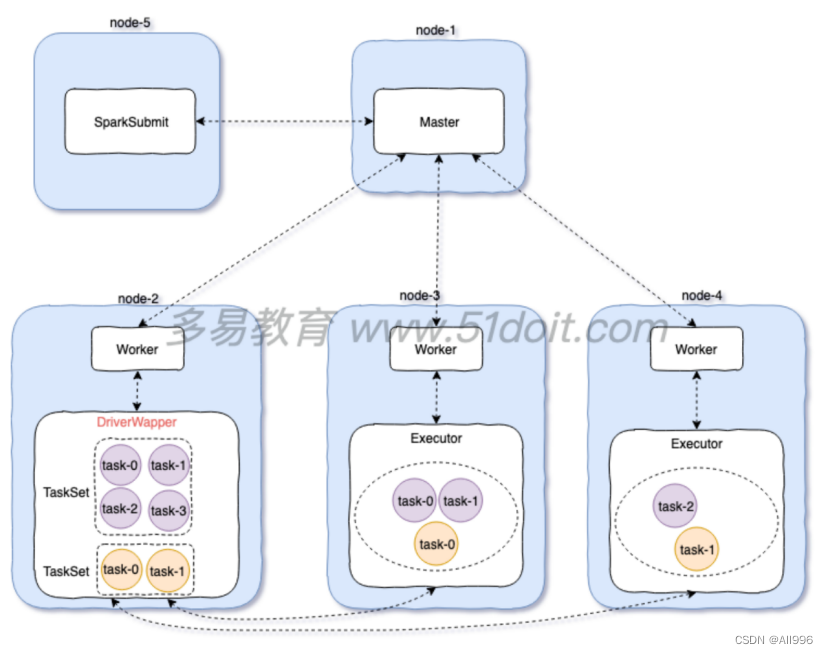
spark12-13-14
12. Task线程安全问题
12.1 现象和原理
在一个Executor可以同时运行多个Task,如果多个Task使用同一个共享的单例对象,如果对共享的数据同时进行读写操作,会导致线程不安全的问题,为了避免这个问题,可以加锁ÿ…
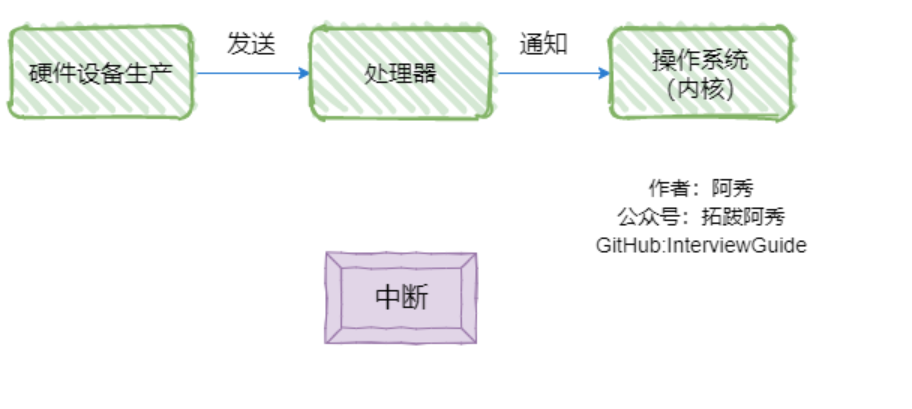
操作系统—中断和异常、磁盘调度算法、操作系统其他内容
异常
时常由CPU*执行指令的内部事件引起,比如非法操作码、地址越界、算术溢出等,还有缺页异常、除0异常。同时,他会发送给内核,要求内核处理这些异常。
外中断
狭义上的中断指的就是外中断。由CPU执行指令以外的事件引起&#…

linux高并发网络编程开发(广播-组播-本地套接字)14_tcp udp使用场景,广播通信流程,组播通信流程,本地套接字通信流程,epoll反应堆模型
01 tcp udp使用场景
1.tcp使用场景
对数据安全性要求高的时候 登录数据的传输 文件传输http协议 传输层协议-tcp
2.udp使用场景
效率高-实时性要求比较高 视频聊天 通话有实力的大公司 使用upd 在应用层自定义协议,做数据校验
02 广播通信流程
广播…

LLM 开发实战系列 | 01:API进行在线访问和部署
在本文中,我们将使用Python编程语言来展示如何调用OpenAI的GPT-3.5模型。在开始之前,请确保您已经注册了OpenAI API并获得了访问凭证。
环境准备
下载python
方法1:官网 www.python.org 从最开始的开始,先到Python官网下载一个…

零基础自学:2023年的今天,请谨慎进入网络安全行业
前言
2023年的今天,慎重进入网安行业吧,目前来说信息安全方向的就业对于学历的容忍度比软件开发要大得多,还有很多高中被挖过来的大佬。
理由很简单,目前来说,信息安全的圈子人少,985、211院校很多都才建…

Linux中安装部署docker
目录 什么是docker系统环境要求安装和使用docker 什么是docker
Docker是一个开源的容器化平台,用于帮助开发者更轻松地构建、打包、分发和运行应用程序。它基于容器化技术,利用操作系统层级的虚拟化来隔离应用程序和其依赖的环境。通过使用Docker&#…
javaEE进阶 -初识框架
目录
1.为什么要学框架?
框架的优点展示
2、项目的开发
2.1 Servlet 项目的开发
2.2 Spring Boot 项目开发
3 、Spring Boot编写代码
4、 Spring Boot 运行项目
5、验证程序
6、发布项目
主要讲解 四个框架。 1、Spring 2、Spring Boot 3、Spring NVC 4、…

别只盯着Docker了,这十大容器运行时错过后悔
文章目录 一、Docker二、Containerd三、CRI-O四、Firecracker五、gVisor六、Kata七、Lima八、Lxd九、rkt十、runC如何选择适合自己的容器运行时? MCNU云原生,文章首发地,欢迎微信搜索关注,更多干货,第一时间掌握&#…

Apikit 自学日记:数据结构
您可以将API文档中的重复部分提取出来成为数据结构,方便其他文档中复用。当数据结构发生改变时,所有引用了该数据结构的API文档会同步发生改变。
创建数据结构
进入数据结构管理页面,点击 添加数据结构 按钮,输入相关内容并保存…

XXL-JOB任务调度
简介: XXL-JOB 是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。 官网:https://www.xuxueli.com/xxl-job/
以下业务场景可用任务解决
某电商平台需要每天上午10点,下午3点,晚上8点发…

2023 高质量 Java 面试题集锦:高级 Java 工程师面试八股汇总
人人都想进大厂,当然我也不例外。早在春招的时候我就有向某某某大厂投岗了不少简历,可惜了,疫情期间都是远程面试,加上那时自身也有问题,导致屡投屡败。突然也意识到自己肚子里没啥货,问个啥都是卡卡卡卡&a…
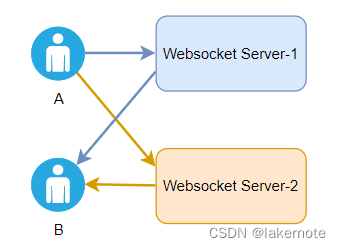
炫技亮点 Websocket集群解决方案汇总
文章目录 问题方案方案一:~~Session共享~~(不可行)方案二:负载均衡器(状态路由)方案三:广播机制(异步方式 - 建议)方案四:路由转发(同步方式&…

【JS经验分享】你真的会写JS吗?满满干货,建议读三遍(2)
大家好,最近准备总结一下JS的经验,分享分享,有不对的欢迎讨论哈~ JS作为前端的基础技能,每一位前端开发都要运用熟练,但你真的会写JS吗?js全称JavaScript,是运行在浏览器上的脚本语言࿰…
【高危】Nuxt.js <3.4.3 远程代码执行漏洞(POC公开)
漏洞描述
Nuxt.js(简称 Nuxt)是一个基于 Vue.js 的通用应用框架,用于构建服务端渲染的应用程序(SSR)和静态生成的网站。
Nuxt.js 3.4.3之前版本中的 test-component-wrapper 组件的动态导入函数存在代码注入漏洞,当服务器在开发…

Java集合流式编程
一、简介
1、什么是集合流式编程 集合流式编程(Stream API)是Java 8引入的一个功能强大的特性,它提供了一种更简洁、更高效的方式来操作集合数据。它的设计目标是让开发者能够以一种更声明式的风格来处理集合数据,减少了显式的迭…

Ubuntu部署jmeter与ant
为了整合接口自动化的持续集成工具,我将jmeter与ant都部署在了Jenkins容器中,并配置了build.xml
一、ubuntu部署jdk
1:先下载jdk-8u74-linux-x64.tar.gz,上传到服务器,这里上传文件用到了ubuntu 下的 lrzsz。
ubunt…
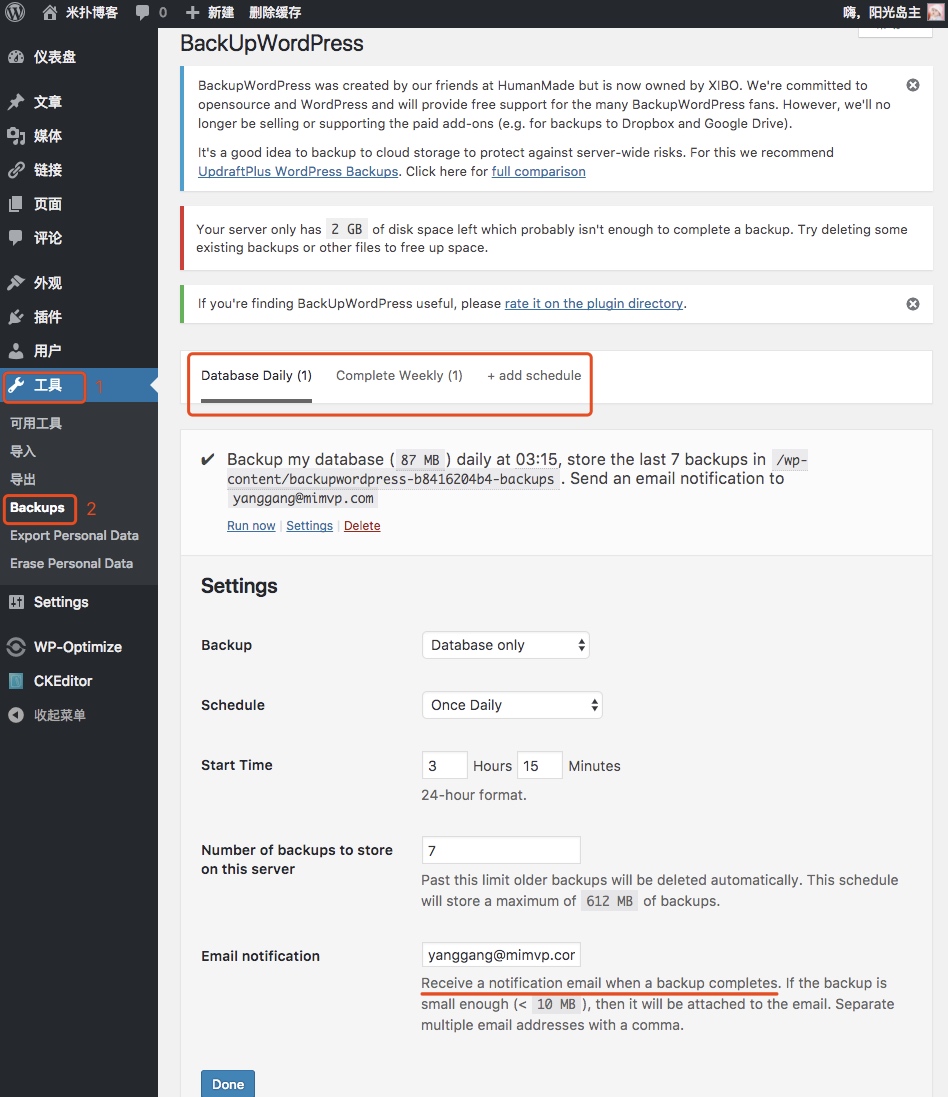
WordPress 备份插件 BackUpWordPress
WordPress备份是一件必不可少的事情,毕竟自己辛辛苦苦花了很多时间精力写得博客,经验总结,必须保留传承。WordPress备份可以在发生灾难性情况(比如劫持或意外锁定)下迅速恢复,确保了网站安全。
BackUpWord…