12. Task线程安全问题
12.1 现象和原理
在一个Executor可以同时运行多个Task,如果多个Task使用同一个共享的单例对象,如果对共享的数据同时进行读写操作,会导致线程不安全的问题, 为了避免这个问题,可以加锁,但效率变低了 ,因为在一个Executor中同一个时间点只能有一个Task使用共享的数据,这样就变成了串行了,效率低!
12.2 案例
定义一个工具类object,格式化日期,因为SimpleDateFormat线程不安全,会出现异常
Scala parse (e)println (res.toBuffer)
Scala sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")sdf .parse(str).getTime
上面的程序会出现错误,因为多个Task同时使用一个单例对象格式化日期,报错,如果加锁,程序会变慢,改进后的代码:
Scala println (res.toBuffer)
Scala sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")sdf .parse(str).getTime
改进后,一个Task使用一个DateUtilClass实例,不会出现线程安全的问题。
13. 累加器
累加器是Spark中用来做计数功能的,在程序运行过程当中,可以做一些额外的数据指标统计
需求:在处理数据的同时,统计一下指标数据,具体的需求为:将RDD中对应的每个元素乘以10,同时在统计每个分区中偶数的数据
13.1 不使用累加器的方案
需要多次触发Action,效率低,数据会被重复计算
Scala /** * 不使用累加器,而是触发两次Action */ List (1,2,3,4,5,6,7,8,9), 2)println (c)
13.2 使用累加器的方法
触发一次Action,并且将附带的统计指标计算出来,可以使用Accumulator进行处理,Accumulator的本质数一个实现序列化接口class,每个Task都有自己的累加器,避免累加的数据发送冲突
Scala List (1,2,3,4,5,6,7,8,9), 2)println (accumulator.count)
14. StandAlone的两种执行模式
spark自动的StandAlone集群有两种运行方式,分别是client模式和cluster模式,默认使用的是client模式 。两种运行模式的本质区别是,Driver运行在哪里了
14.1 什么是Driver
Driver本意是驱动的意思(类似叫法的有MySQL的连接驱动),在就是与集群中的服务建立连接,执行一些命令和请求的。但是在Spark的Driver指定就是SparkContext和里面创建的一些对象 ,所有可以总结为,SparkContext在哪里创建,Driver就在哪里。Driver中包含很多的对象实例,有SparkContext,DAGScheduler、TaskScheduler、ShuffleManager、BroadCastManager等,Driver是对这些对象的统称。
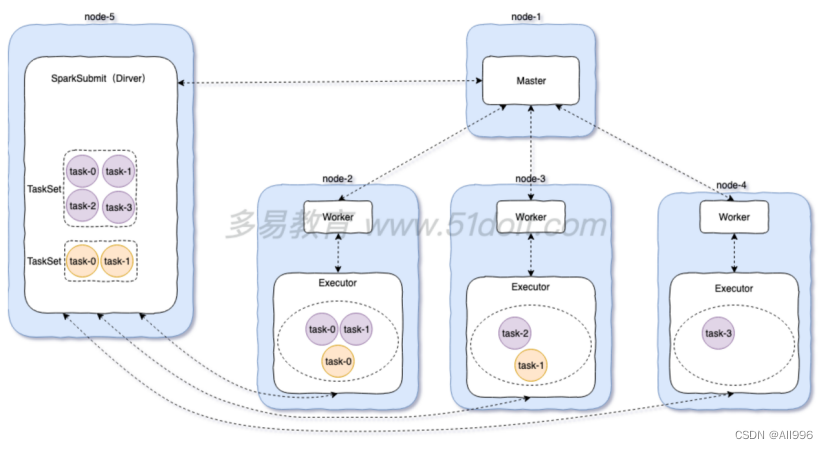
14.2 client模式
Driver运行在用来提交任务的SparkSubmit进程中,在Spark的stand alone集群中,提交spark任务时,可以使用cluster模式即--deploy-mode client (默认的)
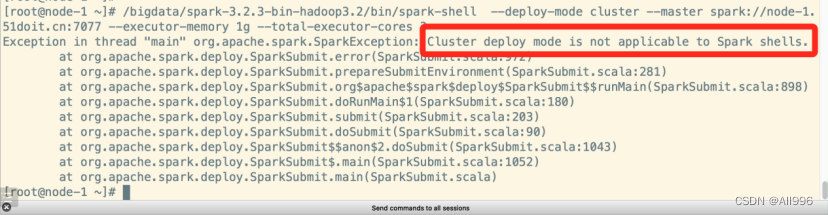
注意:spark-shell只能以client模式运行,不能以cluster模式运行,因为提交任务的命令行客户端和SparkContext必须在同一个进程中。
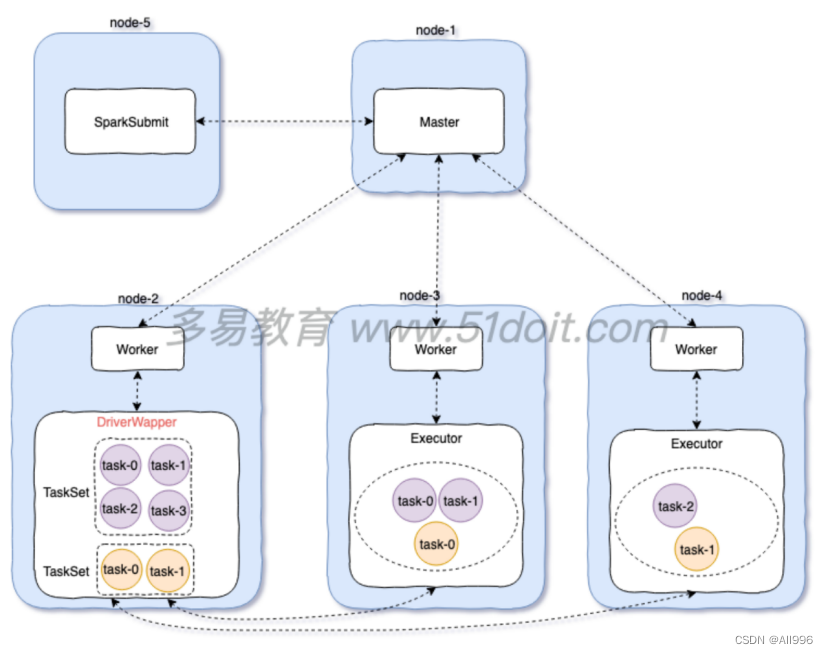
14.3 cluster模式
Driver运行在Worker启动的一个进程中,这个进程叫DriverWapper,在Spark的stand alone集群中,提交spark任务时,可以使用cluster模式即--deploy-mode cluster
特点:Driver运行在集群中,不在SparkSubmit进程中, 需要将jar包上传到hdfs中
Shell --deploy-mode cluster hdfs://node-1.51doit.cn:9000/jars/spark10-1.0-SNAPSHOT.jar hdfs://node-1.51doit.cn:9000/wc hdfs://node-1.51doit.cn:9000/out002
cluster模式的特点:可以给Driver更灵活的指定一些参数,可以给Driver指定内存大小,cores的数量
如果一些运算要在Driver进行计算,或者将数据收集到Driver端,这样就必须指定Driver的内存和cores更大一些
Shell