BeautifulSoup
简称:bs4
BeautifulSoup跟lxml 一样,是一个html文档的解析器,主要功能也是解析和提取数据
优缺点
缺点:效率没有lxml的效率高
优点:接口接口人性化,使用方便 延用了css选择器
安装BeautifulSoup
1、安装:pip install bs4
2、导入:from bs4 import BeautifulSoup
3、创建bs4 对象
① 服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(‘utf-8’),‘lxml’)
② 本地文件生成对象 python对open默认打开文档是gbk
soup = BeautifulSoup(open(‘html文档.html’, ’r‘,encoding=‘utf-8’),‘lxml’)
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('1.html','r',encoding='utf-8'))
# 节点定义
# 1、根据标签查找节点
print(soup.img) # 只能找到1.html中第一个img标签元素 <img > </img>
print(soup.img.name) # 返回 img 元素名称
print(soup.img.attrs) # 返回 img的属性,以字典形式输出
# 2、函数式 find find_all search
# find 返回是是一个元素对象
print(soup.find('img')) # 只能找到第一个img元素 对象
print(soup.find('img'),alt='kitty') # 获取 alt=kitty的img元素,也是符号条件的第一个对象
# 如果用class 匹配 要在 class_ 下划线
print(soup.find('img'),class_='kitty') # 获取 alt=kitty的img元素,也是符号条件的第一个对象
# find_all 返回是列表
print(soup.find_all('img')) # 返回所有img元素
print(soup.find_all(['img', 'span']) # 获取 返回所有img和span元素
print(soup.find_all('img'), limit=2) # 返回前面2个 img元素
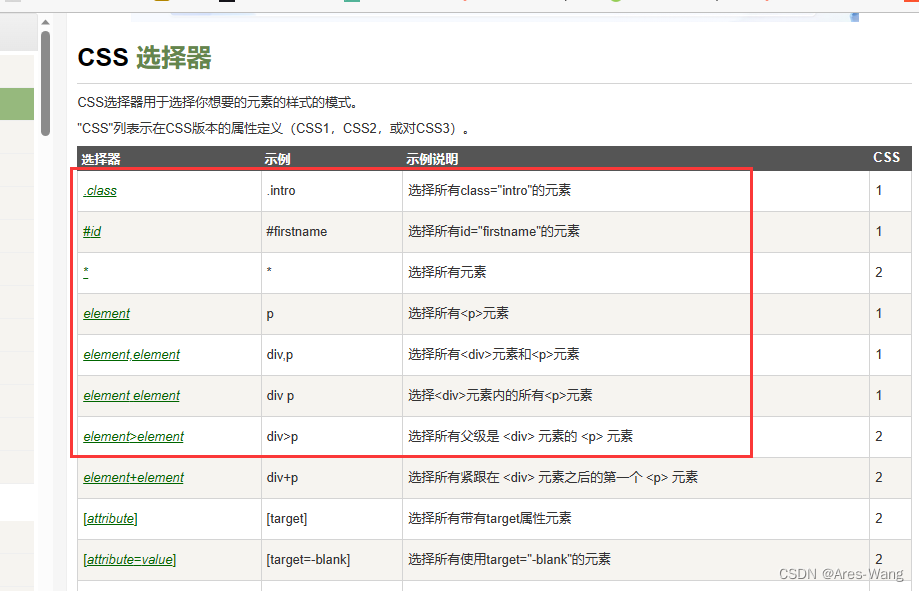
# select 根据选择器得到节点列表对象 跟CSS3 选择器一样
print(soup.select('div')) # 返回 标签是div的所有元素
print(soup.select('#p')) # 返回 id=P的标签元素
print(soup.select('.p')) # 返回 class=p的所有标签元素列表
print(soup.select('div>p')) # 返回 选择所有父级是div的元素的p元素
print(soup.select('div,p')) # 返回 所有div和p的元素列表
print(soup.select('div p')) # 返回 选择div元素内所有p元素
# 属性选择器
print(soup.select('div[id]')) # 返回 选择有属性id的所有div元素列表
print(soup.select('div[id="A2"]')) # 返回 选择属性id="A2"的所有div元素列表
# 节点信息
# string get_text() xpath 用 text()
# 获取节点内容
obj = soup.select('#d1')[0] #select() 返回是列表, 如果要得到第一个元素对象 [0] 才能用 obj.name
# 如果标签对象中 只有内容 string 和 get_text() 效果一样
# 如果标签对象中 出来内容还有标签, string 就获取不到内容了,get_text() 是可以获取得的
print(obj.string)
print(obj.get_text())
# 获取节点属性
obj = soup.find('li') #find() 返回是元素对象 obj.name
print(obj.name) # 获取元素名称
print(obj.attrs) # 将属性值作为一个 字典 返回
print(obj.attrs.get('title')) # 推荐这种
print(obj.get('title')) #
print(obj['title']) #
xpath 、jsonpath、BeautifulSoup
如果是json格式,用 jsonpath
如果是html网页, 首选xpath