文章目录
- 1.RabbitMQ常见的集群模式
- 2.部署基于镜像队列模式的RabbitMQ高可用集群
- 2.1.镜像队列集群原理
- 2.2.分别在两台机器中部署RabbitMQ
- 2.2.1.基础环境配置
- 2.2.2.安装Erlang环境
- 2.2.3.部署RabbitMQ并开启管理界面
- 2.2.4.配置RabbitMQ各节点变量信息
- 2.2.5.访问RabbitMQ后台管理系统
- 2.3.将两个节点配置成集群模式
- 2.4.配置RabbitMQ的镜像队列
- 2.4.1.通过后台管理图形化配置镜像队列
- 2.4.2.通过RabbitMQ命令行配置镜像队列
- 2.5.在集群中创建队列观察镜像队列效果
- 2.5.1.将队列创建在RabbitMQ-1节点上观察效果
- 2.5.2.将队列创建在RabbitMQ-2节点上观察效果
- 2.6.验证RabbitMQ集群的高可用性
- 4.RabbitMQ的集群管理
1.RabbitMQ常见的集群模式
- 主备模式
- 节点提供读写,备用节点不提供读写。如果主节点挂了,就切换到备用节点,原来的备用节点升级为主节点提供读写服务,当原来的主节点恢复运行后,原来的主节点就变成备用节点。
- 远程模式
- 跨地域的让两个 MQ 集群互联,远距离通信和复制。
- 镜像模式
- 百分百保证数据不会丢失,类似于主从复制,但是所有节点都可以提供读写功能,当主节点挂了备用节点继续提供服务
- 多活模式
- 实现异地数据复制的主流模式
2.部署基于镜像队列模式的RabbitMQ高可用集群
2.1.镜像队列集群原理
由于RabbitMQ是使用Erlang语言开发的,天生就具备分布式集群模式,不像ActiveMQ还需要zookeep来实现主备的选举,RabbitMQ自身就可以实现,镜像队列模式是指多个MQ节点之间共同复制消息队列,即使其中一个节点挂了也不会影响程序的使用,在其他的节点中还会存在相同的数据。
RabbitMQ通过进队列就可以实现集群模式,但是当节点很多时,就需要为这些MQ提供一个统一的入口,让消费者和生产者去调用。
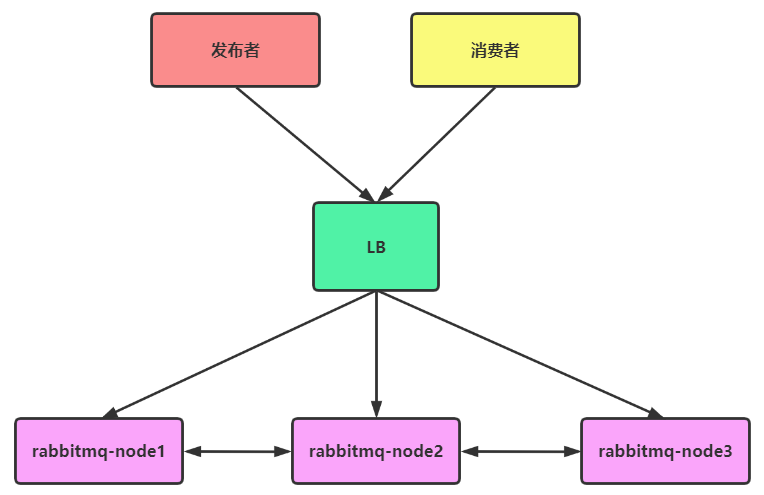
集群规划:
| 角色 | IP | WEB端口 | 通信端口 |
|---|---|---|---|
| rabbitmq-1@rabbitmq-node1 | 192.168.81.210 | 15672 | 5672 |
| rabbitmq-2@rabbitmq-node2 | 192.168.81.220 | 15672 | 5672 |
| haproxy | 192.168.81.230 | 5672 |
2.2.分别在两台机器中部署RabbitMQ
两台机器都按如下步骤进行部署。
2.2.1.基础环境配置
# hostnamectl set-hostname rabbitmq-node1
# hostnamectl set-hostname rabbitmq-node2
# vim /etc/hosts
192.168.81.210 rabbitmq-node1
192.168.81.220 rabbitmq-node2
2.2.2.安装Erlang环境
1.解压源码包
[root@rabbitmq-node1 ~]# tar xf erlang_9.0.tar.gz -C /data
2.配置环境变量
[root@rabbitmq-node1 ~]# vim /etc/profile
ERLANG_HOME=/data/erlang
PATH=$ERLANG_HOME/bin:$PATH
3.加载变量信息
[root@rabbitmq-node1 ~]# source /etc/profile
4.查看erlang版本
[root@rabbitmq-node1 ~]# erl -version
Erlang (SMP,ASYNC_THREADS,HIPE) (BEAM) emulator version 9.0
2.2.3.部署RabbitMQ并开启管理界面
1.部署RabbitMQ
[root@rabbitmq-node1 ~]# tar xf rabbitmq-server-generic-unix-3.6.10.tar.xz -C /data/
[root@rabbitmq-node1 data]# mv rabbitmq_server-3.6.10/ rabbitmq_server
2.开放登陆用户
[root@rabbitmq-node1 ~]# vim /data/rabbitmq_server/ebin/rabbit.app
{loopback_users, [guest]}, #36行,将默认的<<"guest">>改成guest
3.启动RabbitMQ
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmq-server start &
RabbitMQ 3.6.10. Copyright (C) 2007-2017 Pivotal Software, Inc.
## ## Licensed under the MPL. See http://www.rabbitmq.com/
## ##
########## Logs: /data/rabbitmq_server/var/log/rabbitmq/rabbit@rabbitmq.log
###### ## /data/rabbitmq_server/var/log/rabbitmq/rabbit@rabbitmq-sasl.log
##########
Starting broker...
completed with 0 plugins.
4.开启后台管理系统
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmq-plugins enable rabbitmq_management
2.2.4.配置RabbitMQ各节点变量信息
1)RabbitMQ Node1节点配置
1.配置RabbitMQ的变量信息
[root@rabbitmq-node1 ~]# cat /data/rabbitmq_server/etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_NODENAME=rabbitmq-1@rabbitmq-node1 #节点名称
RABBITMQ_NODE_IP_ADDRESS=192.168.81.210 #节点地址
RABBITMQ_NODE_PORT=5672 #使用的端口号
RABBITMQ_MNESIA_BASE=/data/rabbitmq_server/data #数据路径
RABBITMQ_LOG_BASE=/data/rabbitmq_server/logs #日志路径
2.添加RabbitMQ的主配置文件
[root@rabbitmq-node1 ~]# cat /data/rabbitmq_server/etc/rabbitmq/rabbitmq.config
[
{rabbit,
[
{tcp_listeners, [5672]},
{dump_log_write_threshold, [1000]},
{vm_memory_high_watermark, 0.5},
{disk_free_limit, "200MB"},
{hipe_compile,true}
]
}
].
2)RabbitMQ Node2节点配置
1.配置RabbitMQ的变量信息
[root@rabbitmq-node1 ~]# vim /data/rabbitmq_server/etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_NODENAME=rabbitmq-1@rabbitmq-node2 #节点名称
RABBITMQ_NODE_IP_ADDRESS=192.168.81.220 #节点地址
RABBITMQ_NODE_PORT=5672 #使用的端口号
RABBITMQ_MNESIA_BASE=/data/rabbitmq_server/data #数据路径
RABBITMQ_LOG_BASE=/data/rabbitmq_server/logs #日志路径
2.添加RabbitMQ的主配置文件
[root@rabbitmq-node1 ~]# vim /data/rabbitmq_server/etc/rabbitmq/rabbitmq.config
[
{rabbit,
[
{tcp_listeners, [5672]},
{dump_log_write_threshold, [1000]},
{vm_memory_high_watermark, 0.5},
{disk_free_limit, "200MB"},
{hipe_compile,true}
]
}
].
3)配置完成后重启两个节点
# /data/rabbitmq_server/sbin/rabbitmqctl stop
# /data/rabbitmq_server/sbin/rabbitmq-server start
HiPE compiling: |---------------------------------------------------------|
|#########################################################|
Compiled 57 modules in 114s
RabbitMQ 3.6.10. Copyright (C) 2007-2017 Pivotal Software, Inc.
## ## Licensed under the MPL. See http://www.rabbitmq.com/
## ##
########## Logs: /data/rabbitmq_server/logs/rabbitmq-1@rabbitmq-node1.log
###### ## /data/rabbitmq_server/logs/rabbitmq-1@rabbitmq-node1-sasl.log
##########
Starting broker...
completed with 6 plugins.
2.2.5.访问RabbitMQ后台管理系统
访问各节点。
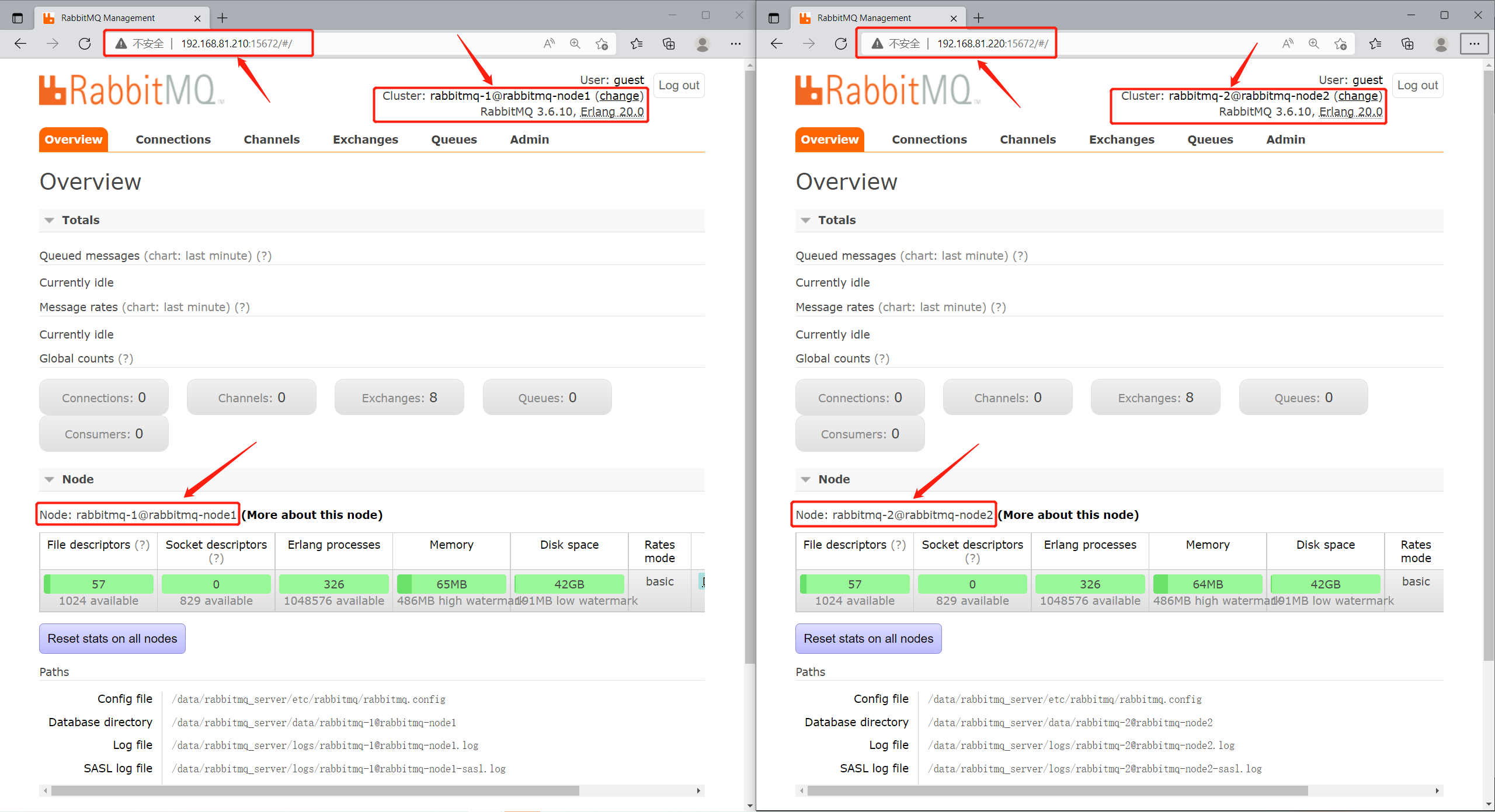
2.3.将两个节点配置成集群模式
rabbitmq-1@rabbitmq-node1为集群中的主节点,rabbitmq-2@rabbitmq-node2加入rabbitmq-1@rabbitmq-node1的集群。
1)RabbitMQ-1节点操作
RabbitMQ第一个节点为集群中的主节点,可以不做数据清理,亦不用执行下面的步骤。
1.停止rabbitmq-1节点
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmqctl stop_app
Stopping rabbit application on node 'rabbitmq-1@rabbitmq-node1'
2.清空数据
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmqctl reset
Resetting node 'rabbitmq-1@rabbitmq-node1'
3.启动rabbitmq-1节点
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmqctl start_app
Starting node 'rabbitmq-1@rabbitmq-node1'
如果一个节点上存在多个应用,则需要使用-n指定当前mq应用的名称,例如`/data/rabbitmq_server/sbin/rabbitmqctl -n rabbitmq-2 reset`
stop_app停止的并不是RabbitMQ服务,而是停止的由erlang运行的服务
2)RabbitMQ-2节点操作
由于RabbitMQ第二个节点要加入第一个节点的集群,因此必须要清空数据。
1.停止rabbitmq-2节点
[root@rabbitmq-node2 ~]# /data/rabbitmq_server/sbin/rabbitmqctl -n stop_app
Stopping rabbit application on node 'rabbitmq-2@rabbitmq-node2'
2.清空数据
[root@rabbitmq-node2 ~]# /data/rabbitmq_server/sbin/rabbitmqctl reset
Resetting node 'rabbitmq-2@rabbitmq-node2'
3.加入rabbitmq-1节点组成集群
[root@rabbitmq-node2 ~]# /data/rabbitmq_server/sbin/rabbitmqctl join_cluster --ram rabbitmq-1@rabbitmq-node1
Clustering node 'rabbitmq-2@rabbitmq-node2' with 'rabbitmq-1@rabbitmq-node1'
rabbitmq-1@rabbitmq-node1 @符号后面的是第一个节点的主机名,主机名不要随意更改
当加入集群的命令执行成功后,在RabbitMQ第一个节点的控制台就可以看到已经有第二个节点加入了,现处于未启动状态。
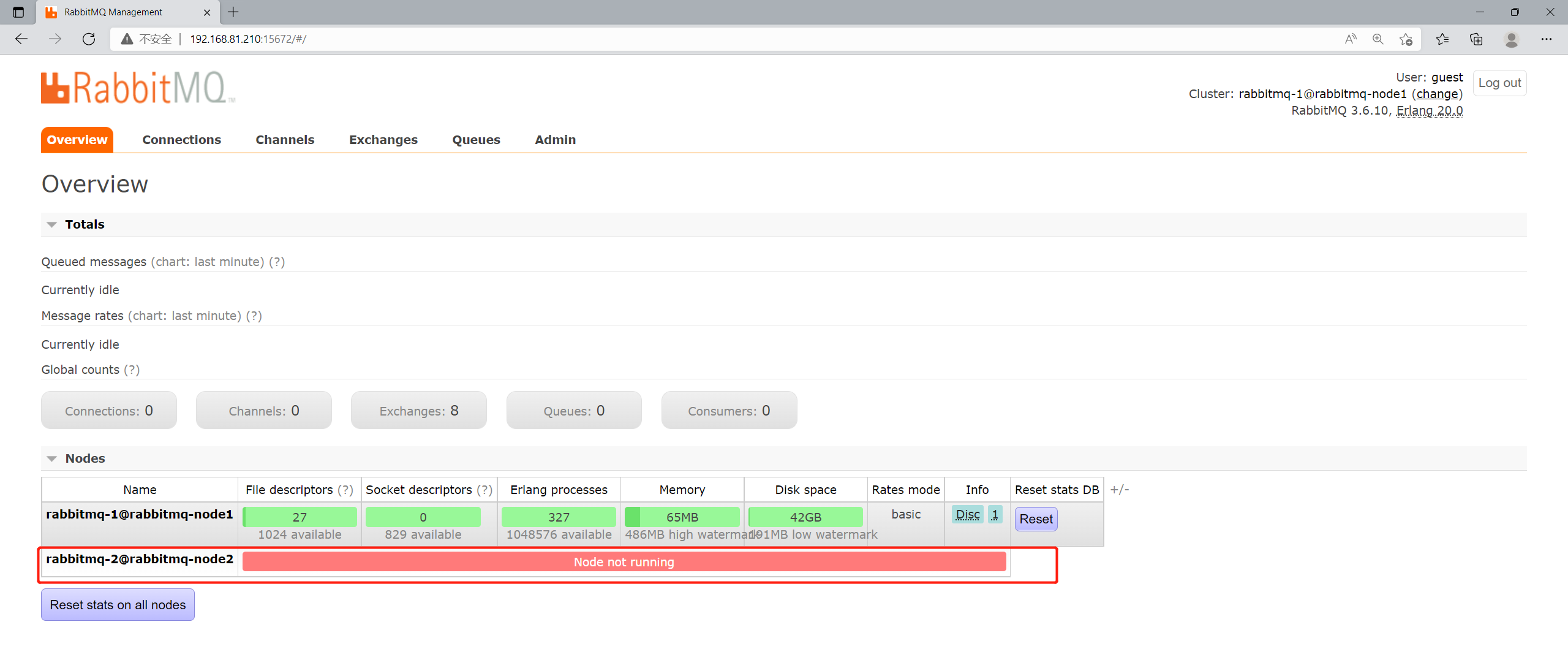
4.启动第二个节点
[root@rabbitmq-node2 ~]# /data/rabbitmq_server/sbin/rabbitmqctl start_app
Starting node 'rabbitmq-2@rabbitmq-node2'
集群组件完成。
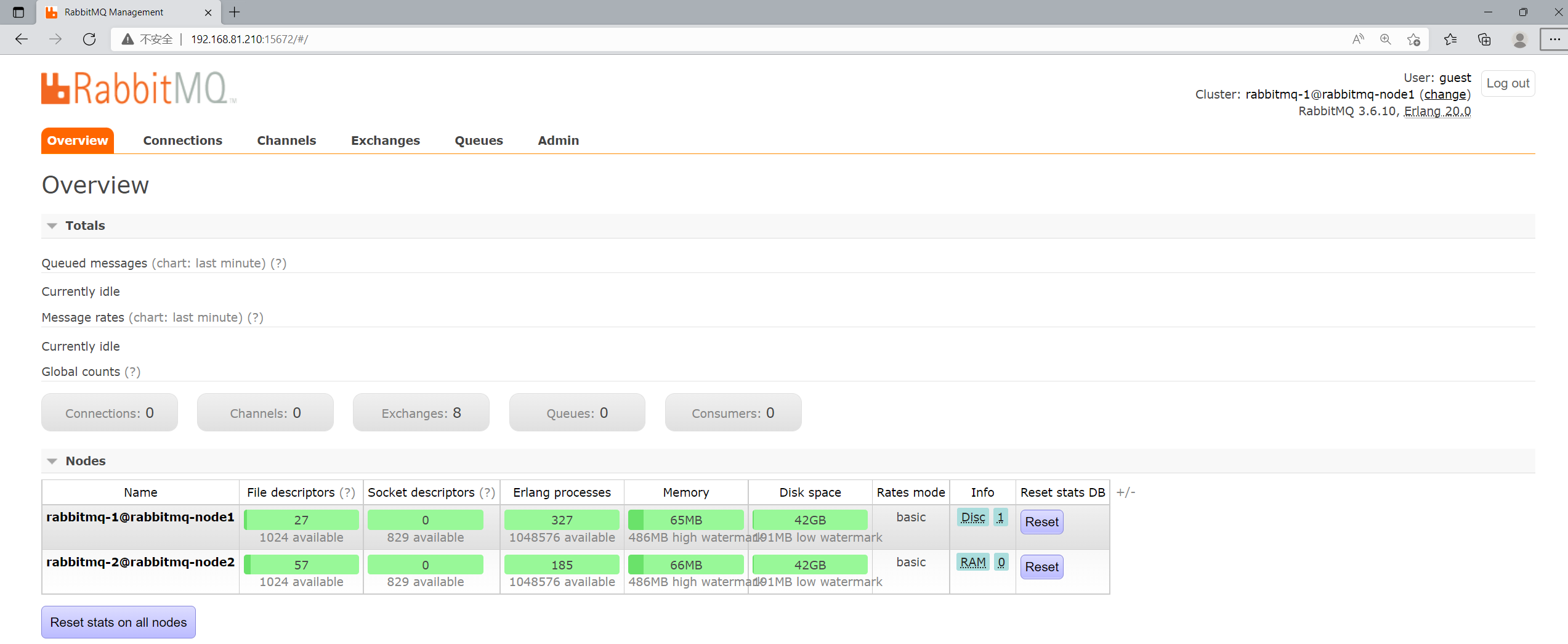
3)查看集群的状态
可以看到集群及诶单的信息等等。
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmqctl cluster_status
Cluster status of node 'rabbitmq-1@rabbitmq-node1'
[{nodes,[{disc,['rabbitmq-1@rabbitmq-node1']},
{ram,['rabbitmq-2@rabbitmq-node2']}]},
{running_nodes,['rabbitmq-2@rabbitmq-node2','rabbitmq-1@rabbitmq-node1']},
{cluster_name,<<"rabbitmq-1@rabbitmq-node1">>},
{partitions,[]},
{alarms,[{'rabbitmq-2@rabbitmq-node2',[]},{'rabbitmq-1@rabbitmq-node1',[]}]}]
2.4.配置RabbitMQ的镜像队列
在上一步中,RabbitMQ集群已经搭建完成了,但是并不能保证消息队列的高可用,尽管交换机和队列都可以绑定和复制到任何一个节点中,在每个节点都会显示,但是数据时不会复制的,当我们在rabbitmq-1节点上创建的队列,产生的消息数据,在第二个节点上只能看到这个队列的状态,当第一个节点挂了之后,数据就无法读取了,仅显示有这个队列存在并且状态是down。
基于上述问题,想要在某个节点挂掉之后,还可以正常的使用,我们就需要配置镜像队列功能,将MQ中的什么数据进行镜像复制的功能,也就是实时同步这些数据到另外的节点,即使rabbitmq-1节点挂掉了,数据在rabbitmq-2节点上还有一份存在,不影响用户的使用。
镜像队列就是在普通集群模式之上,填写一些策略,完成数据的同步。
配置镜像队列的方式有两种:后台管理系统图形化配置、通过命令配置。
2.4.1.通过后台管理图形化配置镜像队列
点击Admin—>Policies—>Add a Policy—>填写策略的名称:image_queue_ha—>设置正则表达式:^(匹配所有)---->选择要将那些数据进行同步 选择上交换机和对列—>设置模式ha-mode=all
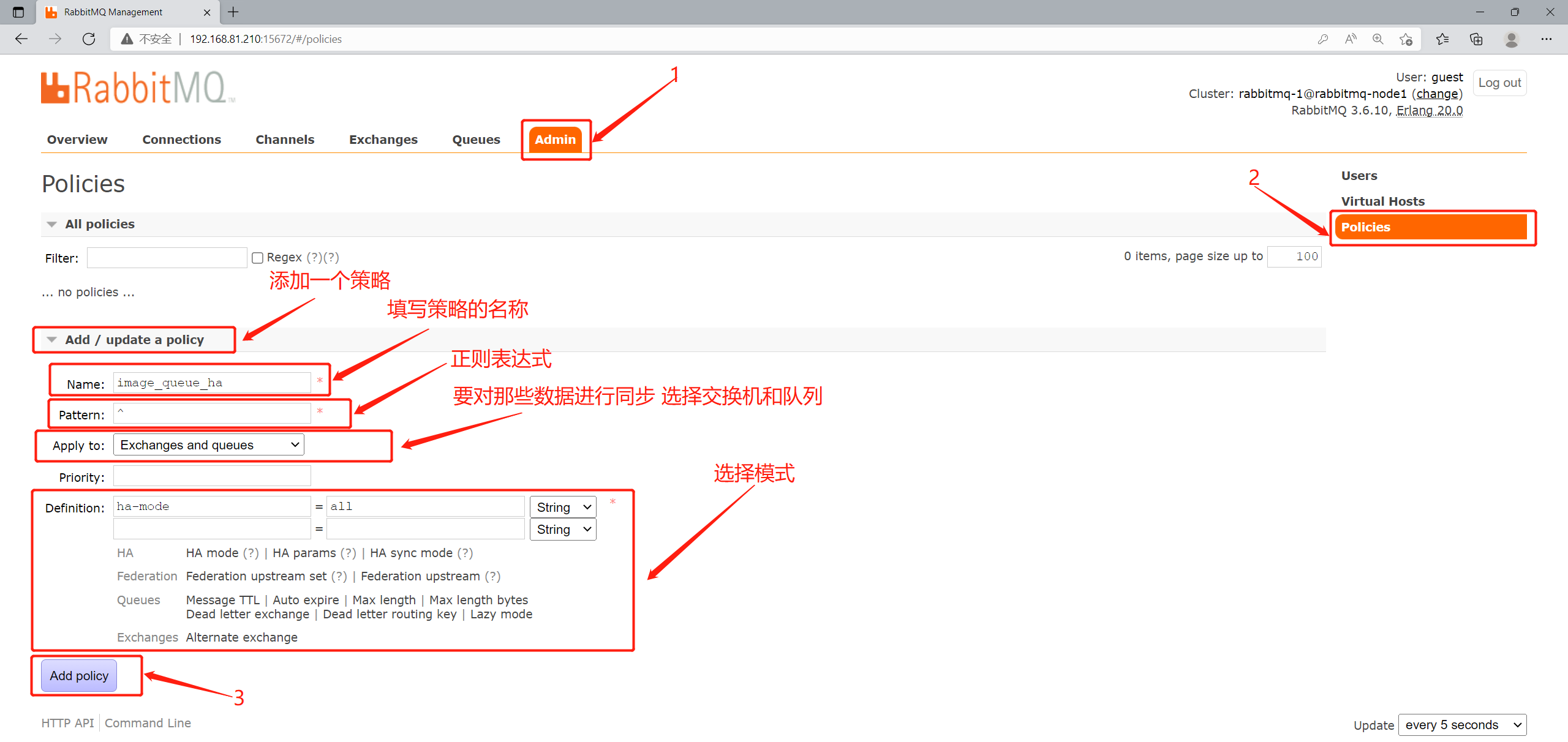
2.4.2.通过RabbitMQ命令行配置镜像队列
rabbitmqctl set_policy image_queue_ha "^" '{"ha-mode":"all"}'
在哪一个节点上添加都可以,都会复制。
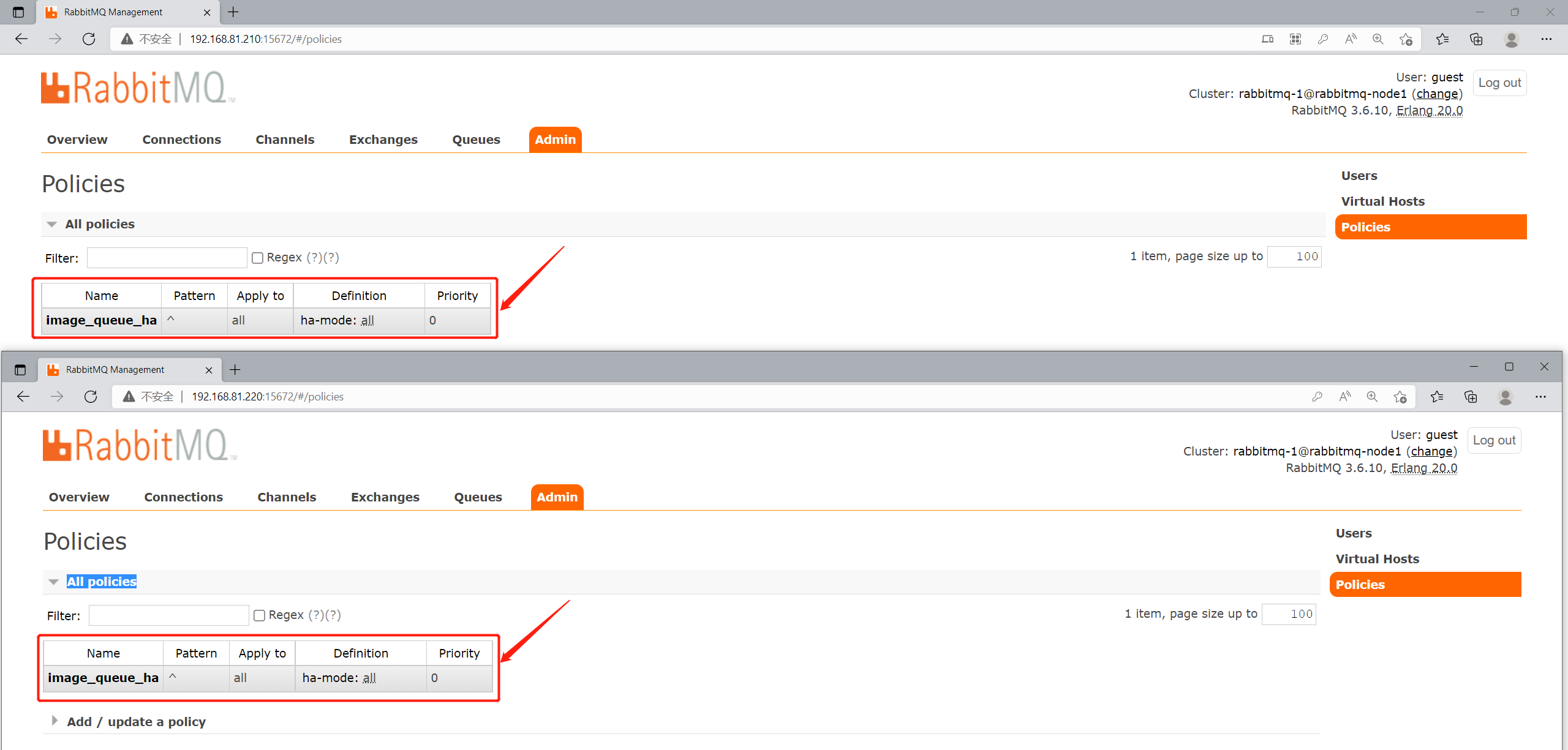
2.5.在集群中创建队列观察镜像队列效果
最终结论:再哪一个节点上创建的队列,哪一个节点就是该队列的主节点。
2.5.1.将队列创建在RabbitMQ-1节点上观察效果
1)创建队列选择第一个节点。
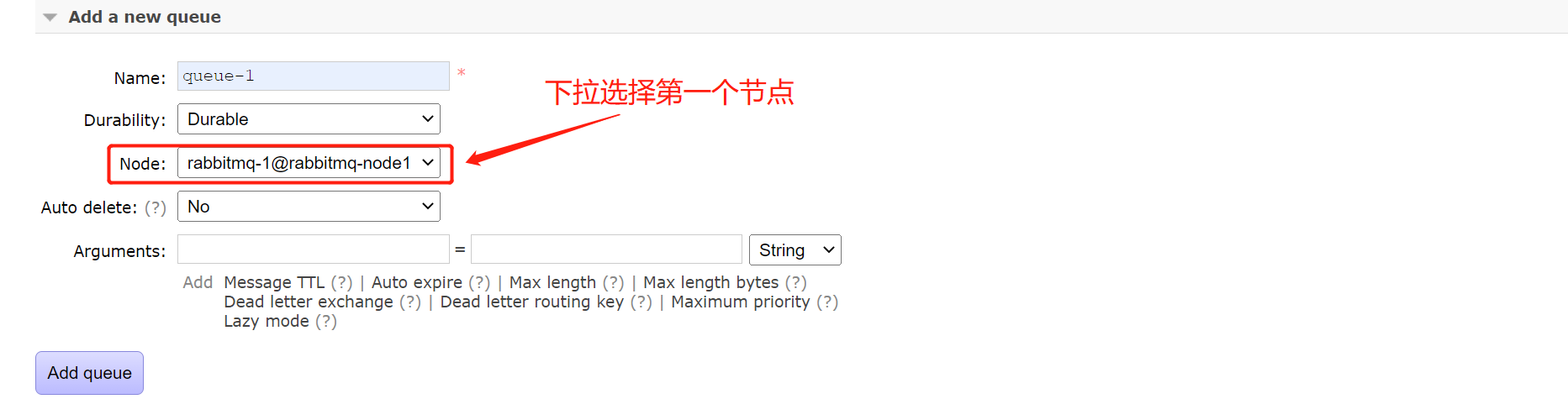
2)可以看到创建的队列在节点列表中会多了个+1。
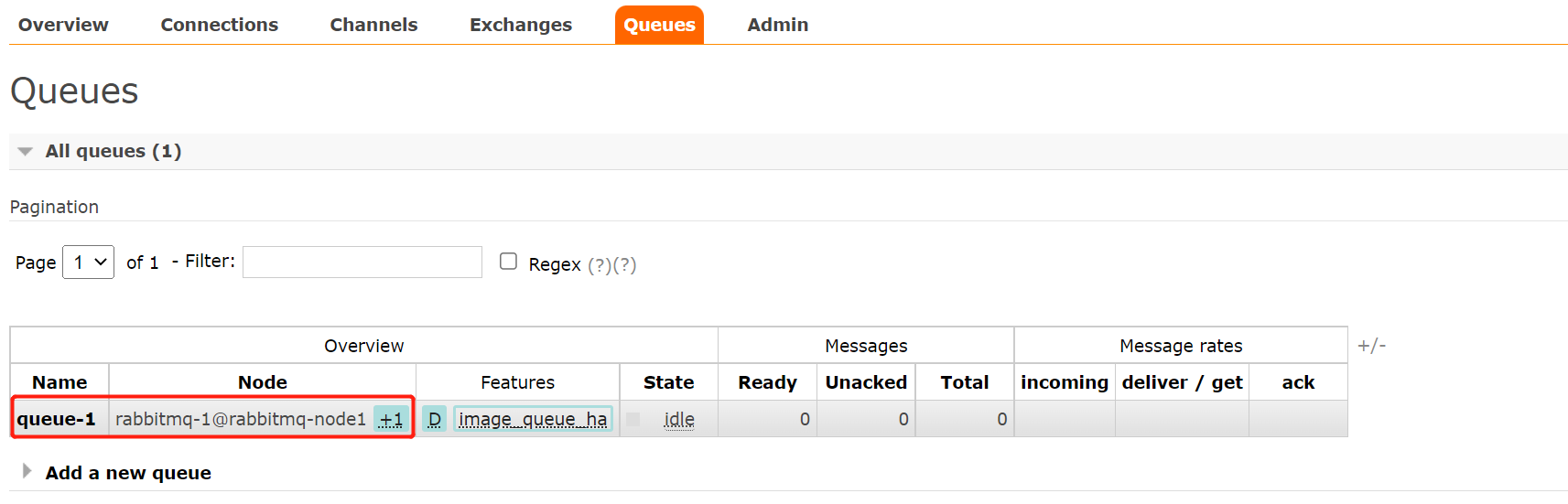
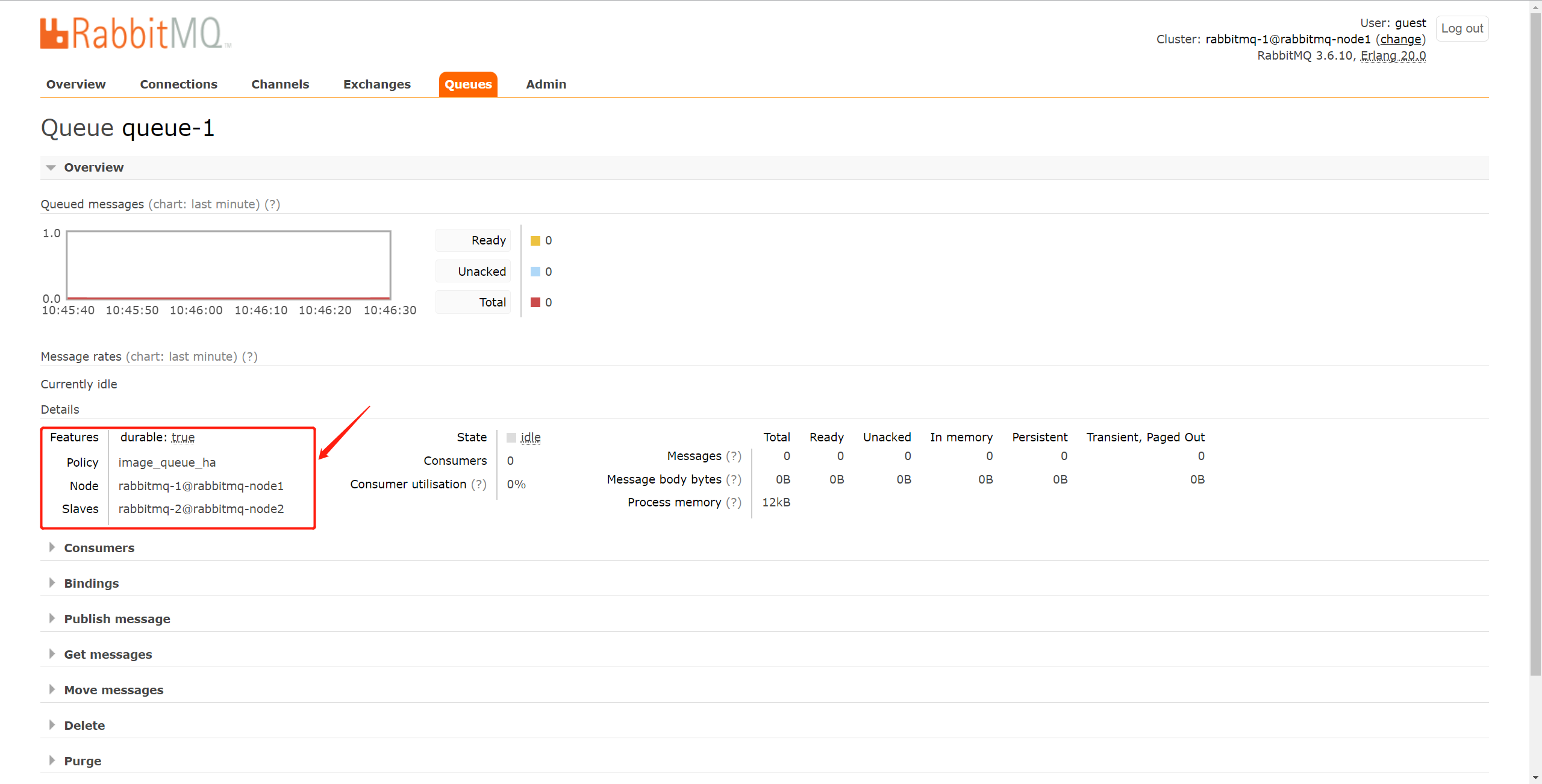
3)点击队列名称查看详细的信息。
可以看到这个队列引用了我们创建的镜像队列的策略,并且主节点是rabbitmq-1,备用节点是rabbitmq-2。
2.5.2.将队列创建在RabbitMQ-2节点上观察效果
1)将队列创建的第二个节点上。

2)同样也会在节点列表中显示+1

3)查看队列的详细信息。
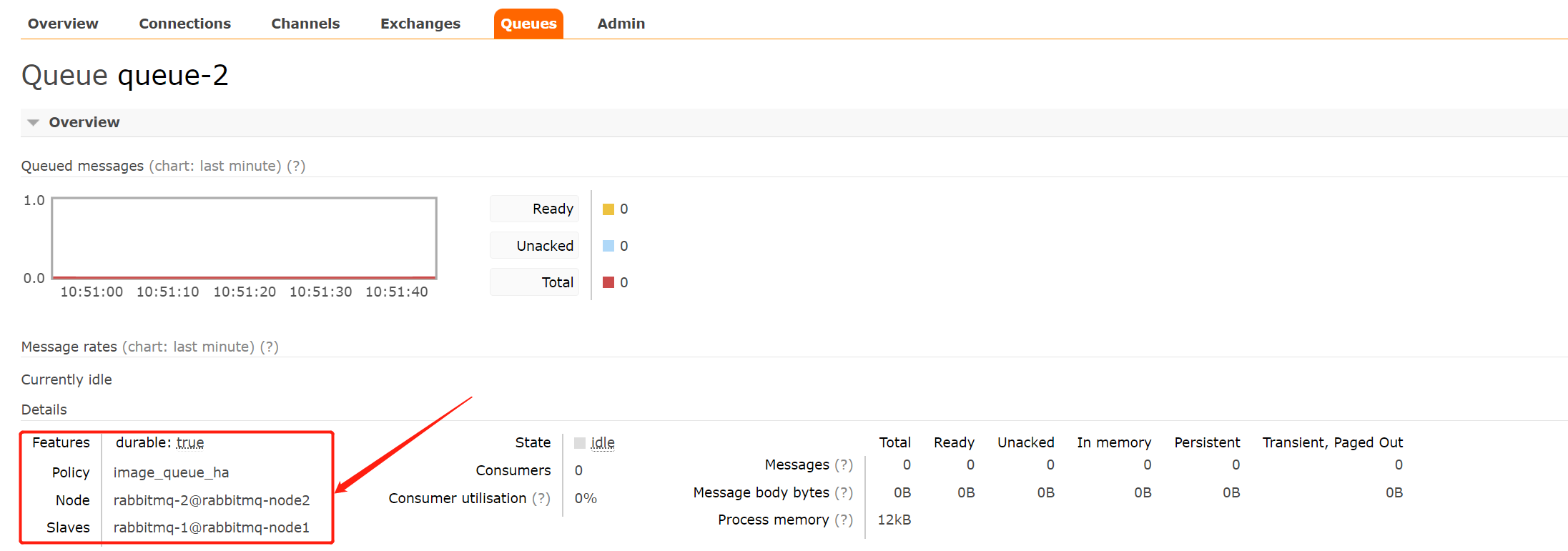
2.6.验证RabbitMQ集群的高可用性
任意关掉集群中的一个节点,我们来查看数据是否还在,我们来关闭第一个节点。
[root@rabbitmq-node1 ~]# /data/rabbitmq_server/sbin/rabbitmqctl stop_app
Stopping rabbit application on node 'rabbitmq-1@rabbitmq-node1'
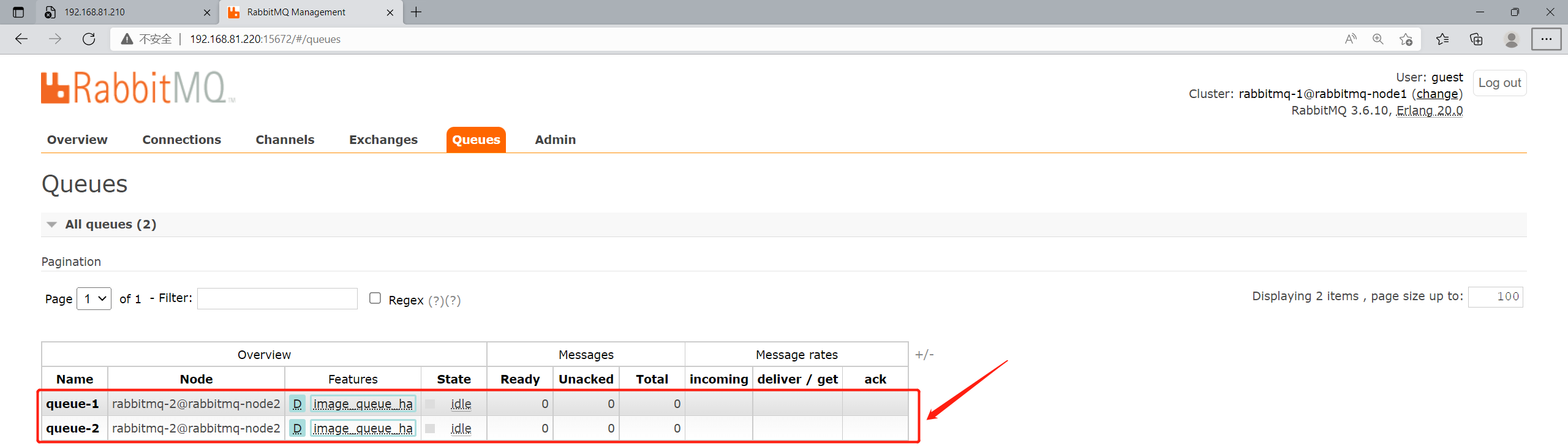
第一个节点已经停止服务,后台管理系统也已经挂掉,我们进入第二个节点的控制台,观察队列是否存在异常。
可以看到所有队列中的节点列表,都已经变成了rabbitmq-2,并且没有了+1的展示,这是因为第一个节点挂了,现在一个
4.RabbitMQ的集群管理
将节点加入指定的集群中,执行命令前需要停止RabbitMQ应用并重置节点数据。
rabbitmqctl join_cluster {cluster_node} [-ram]
显示集群的状态
rabbitmqctl cluster_status
修改集群节点的类型
rabbitmqctl change cluster_node_type {dusc|ram}
将节点从集群中删除
rabbitmqctl forget cluster_node [-offline]
刷新集群的信息
刷新集群的应用场景:当A节点和B节点组成一个集群,A节点因为某种异常离线了,B节点和C节点此时又组成了这个集群,当B节点从这个集群中下线时,A节点恢复了,A节点就会尝试连接B节点,为了避免此种问题,可以刷新集群的信息。
rabbitmqctl update_cluster_nodes {clusternode}
取消镜像队列的同步操作
rabbitmqctl canncel_sync_queue [-p vhost] {queue}
设置集群的名称
rabbitmqctl set_cluster_name {name}