死锁问题分析
起因
起因是线上报了一个死锁问题,然后我就去查看下死锁的原因。
思路
死锁问题的排查,
**日常工作中,应对各类线上异常都要有我们自己的 SOP (标准作业流程) ** ,这样不仅能够提高自己的处理问题效率,也有助于将好的处理流程推广到团队,提高团队的整体处理异常能力。
所以,面对线上偶发的 MySQL 死锁问题,我的排查处理过程如下:
线上错误日志报警发现死锁异常
查看错误日志的堆栈信息
查看 MySQL 死锁相关的日志
根据 binlog 查看死锁相关事务的执行内容
根据上述信息找出两个相互死锁的事务执行的 SQL 操作,根据本系列介绍的锁相关理论知识,进行分析推断死锁原因
修改业务代码
根据1,2步骤可以找到死锁异常时进行回滚事务的具体业务,也就能够找到该事务执行的 SQL 语句。然后我们需要通过 3,4步骤找到死锁异常时另外一个事务,也就是最终获得锁的事务所执行的 SQL 语句,然后再进行锁冲突相关的分析。
第一二步的线上错误日志和堆栈信息一般比较容易获得,第五步的分析 SQL 锁冲突原因中涉及的锁相关的理论在系列文章中都有介绍,没有了解的同学可以自行去阅读以下。
下面我们就来重点说一下其中的第三四步骤,也就是如何查看死锁日志和 binlog 日志来找到死锁相关的 SQL 操作。
链接:https://juejin.cn/post/6885315880444657678
这个思路是对的,针对比较常见场景的问题,我们要积累自己的标准作业流程,一套下来直接找到问题。
现场
那我就直接去数据查看下死锁信息。
登入mysql,并使用:
show engine innodb status*;*
大概查看到数据就是这样
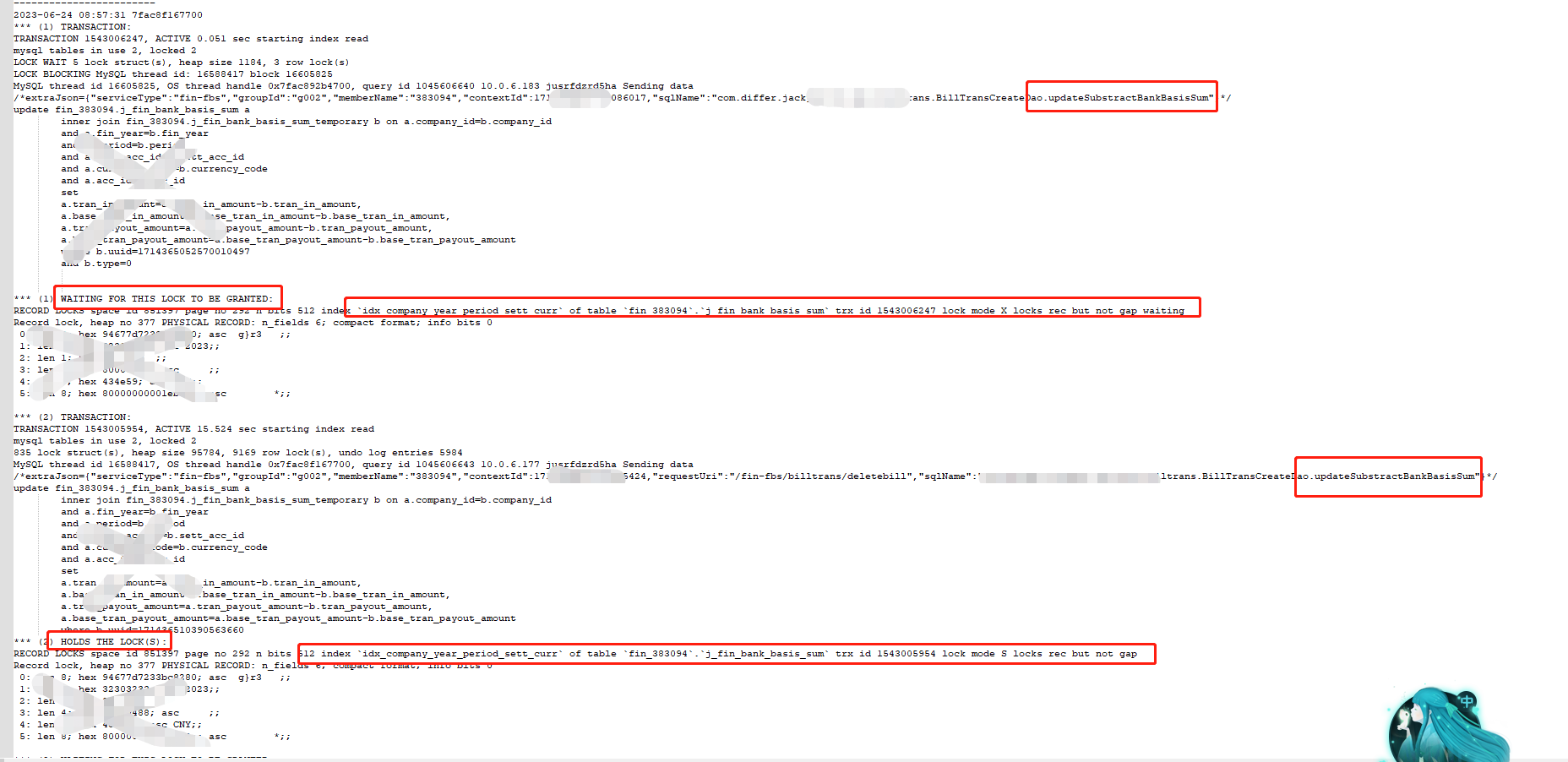
我们查看死锁日志,其实关键信息主要就是,那个dao的方法,然后事务1拿着什么要什么锁,事务2拿着什么要什么锁。
可以看到事务1和事务2都要同一个锁。
这个
死锁产生的必要条件:
互斥。
请求与保持条件。
不剥夺条件。
循环等待。
从日志上来看事务1和事务2都是取争夺同一行的行锁,和前面概念部分提到的三种案例互相循环争夺锁有点不同,怎么看都无法满足循环等待条件。
因为发生死锁的这段逻辑添加了事务管理,因此去看此段业务代码:
作者:JellyfishMIX
链接:https://juejin.cn/post/6844904138921394190
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
跟这个有点像,既然都争夺一个锁造成了死锁,肯定这个业务代码之前有持有另一个事务要的锁。
然后就去业务代码查看下跟这个表有关的update语句。
然后就查看了这么一段有意思的语句。
其实有两个表,一个parent表,一个son表。
大概业务逻辑就是,更新son表,更新parent表。
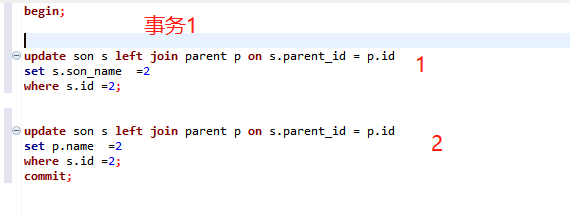
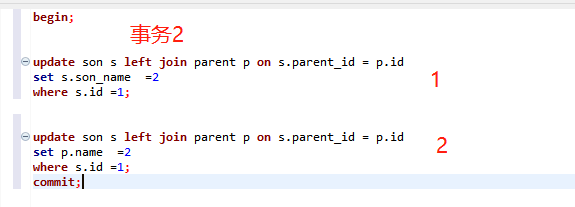
但是这里有意思的是,更新子表的时候,也关联主表,然后更新。
我第一个思路就是,update的话,如果有join,是不是把另一个也锁了,即使没更新另一个表。
模拟
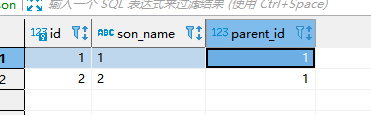
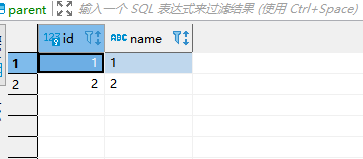
那我直接就本地测试了下,用parent表和son表来模拟。
son表
parent表
然后就很简单了,事务1执行1,事务2执行1.然后事务1执行2的时候,直接就死锁了。
很明显,update的话,如果有join,是不是把另一个也锁了,即使没更新另一个表。估计是一个s锁,如果是x锁,估计事务2执行1就直接阻塞了。
所以我们update的时候,别join,直接
用update son set son_name=2 where son.parent_id in (select id from parent where id=1 )这种。
总结
所以死锁的标准流程也整理出来了。
1.线上报错,有死锁。
2.直接去数据库拿死锁信息。主要看是哪个表哪个索引死锁了。
3.查看业务代码。主要查看这个业务流程中那个dao执行操作被锁表的。
4.分析一下死锁原因并改正。
分享
分享一下几个死锁案例。