目录
前言:
1.单线程执行
2、多线程执行
3.守护线程
4.阻塞线程
前言:
多线程并发是一种处理任务的方式,它可以在同一时间内执行多个任务。多线程并发通常应用于需要同时处理多个任务或同时运行多个程序的情况下。
1.单线程执行
Python的内置模块提供了两个线程模块:threading 和thread。
thread:是原生的
threading:是扩展的
用法:
变量 = threading.Thread(target = 执行函数)
变量.strart()
代码示例:
# -*- coding:utf-8 -*-
# @Time : 2020-06-08
# @Author : Carl_奕然
import threading
#自定义test函数
def test():
print("test threading")
#创建一个单线程,来执行test()函数
t = threading.Thread(target= test)
t.start()运行结果:
test threading2、多线程执行
单线程已经会使用,那么多线程还会远吗?
多线程只需要通过循环创建多个线程,并通过循环启动执行就可以了。
我们来看个例子,为了更直观,我把打印的内容修改成打印时间:
代码示例:
# -*- coding:utf-8 -*-
# @Time : 2020-06-08
# @Author : Carl_奕然
import threading
from datetime import *
#自定义test函数
def test():
now = datetime.now() #获取当前时间
print("打印多线程执行时间:",now)
#自定义thr()函数,来执行多线程
def thr():
threads = [] #自定义一个空的数组,用来存放线程组
for i in range(10): #设置循环10次
t = threading.Thread(target=test)
threads.append(t) #把创建的的线程t,装到threads 数组中
#启动线程
for t in threads:
t.start()
#执行thr()函数进行多并发
if __name__ == "__main__" :
thr()运行结果
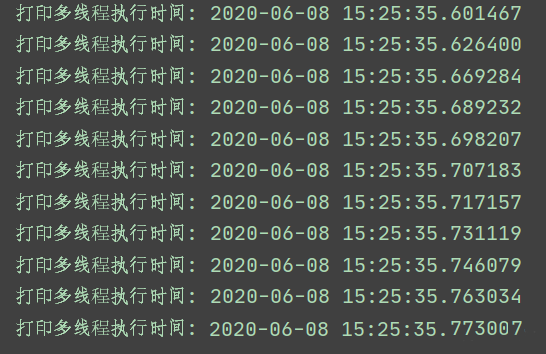
我们可以看到,我循环执行了10次,这时间相差的太小了,可以忽略不计。
如果,我设置1000次,10000次的话,如果还是这样写,是不是需要等待很长时间?服务器的压力会不会增加?资源消耗会不会增加?
那如何优化呢?
来看这个例子:
我们执行1000次并发,把这1000次拆成50个线程,每个线程循环20次,这样是不是就会快很多?
我们来看看执行效率
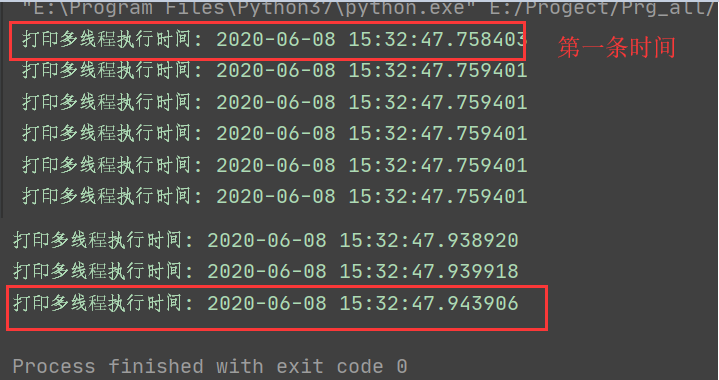
修改代码
# -*- coding:utf-8 -*-
# @Time : 2020-06-08
# @Author : Carl_奕然
import threading
from datetime import *
#自定义test函数
def test():
now = datetime.now() #获取当前时间
print("打印多线程执行时间:",now)
#设置50个线程
def looptest():
for i in range(50):
test()
#自定义thr()函数,来执行多线程
def thr():
threads = [] #自定义一个空的数组,用来存放线程组
for i in range(20): #设置循环10次
t = threading.Thread(target=test)
threads.append(t) #把创建的的线程t,装到threads 数组中
#启动线程
for t in threads:
t.start()
#执行thr()函数进行多并发
if __name__ == "__main__" :
thr()运行结果:
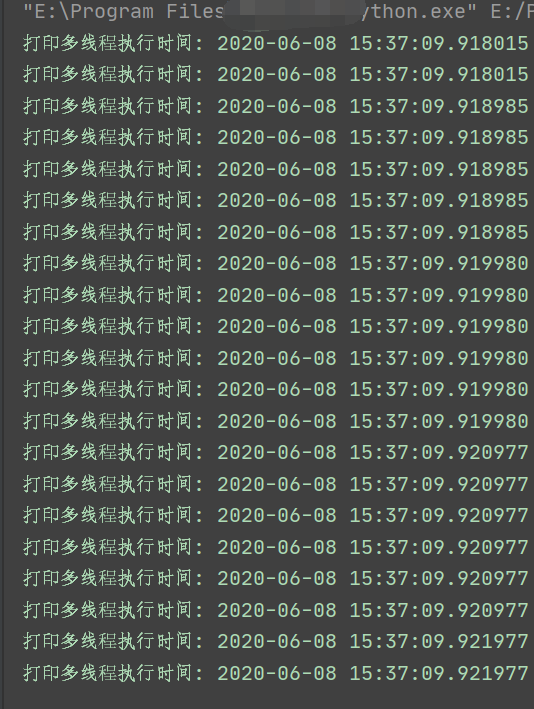
是不是快很多了。
3.守护线程
在了解守护线程之前,先来了解下主线程与子线程的区别。
主线程与子线程的区别:
每个线程都有一个唯一标示符,来区分线程中的主次关系的说法。
线程唯一标示符:Thread.CurrentThread.ManagedThreadID;
・UI界面和Main函数均为主线程。
・被Thread包含的“方法体”或者“委托”均为子线程。
・委托可以包含多个方法体,利用this.Invoke去执行。
・也可以定义多种方法体,放在Thread里面去执行。则此方法・体均为子线程。注意如果要修改UI界面的显示。则需要使用this.Invoke,否则会报异常。
・Main函数为主线程,id标示符与UI界面主线程相等。
对照上面的代码,main()就是主线程,thr()就是子线程。
>>即先启动main(),然后执行thr()启动子线程。
那么,什么是守护线程呢?
>>即当主线程执行完毕后,所有的子线程也被关闭(无论子线程是否执行完成)。默认是不设置守护线程的。
但是我们又为什么要用守护线程呢?
>>说的直接,就是为了防止死循环。
>>因为一个死循环如果不手动停止,我们都知道会一直的循环下去,直到资源耗尽。
那么守护线程的用法是什么呢?
>>setDaemon():默认是 False, 需要改成True才能启用。
代码示例:
# -*- coding:utf-8 -*-
# @Time : 2020-06-08
# @Author : Carl_奕然
import threading
from datetime import *
#自定义test函数
def test():
x=0
while (x ==0): #修改成死循环
print(datetime.now())
#自定义thr()函数,来执行多线程
def thr():
threads = [] #自定义一个空的数组,用来存放线程组
for i in range(20): #设置循环10次
t = threading.Thread(target=test)
threads.append(t) #把创建的的线程t,装到threads 数组中
t.setDaemon(True) # 设置守护线程
#启动线程
for t in threads:
t.start()
#执行thr()函数进行多并发
if __name__ == "__main__" :
thr()
print("守护线程功能启用,end")运行结果:
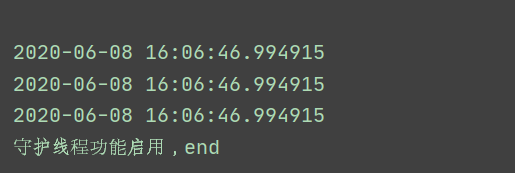
4.阻塞线程
强制程序停止,除了运用守护线程,还可以用到 阻塞线程,
如果说前者是强硬派,那么后者就属于温柔派。
那么我们再来看看阻塞线程;
阻塞线程:通过子线程 join()方法来阻塞线程,
让主线程等待子线程完成之后再往下执行,
等主线程执行完毕后在挂你吧所有子线程。
代码示例:
# -*- coding:utf-8 -*-
# @Time : 2020-06-08
# @Author : Carl_奕然
import threading
from datetime import *
def test():
x =0
while(x ==0):
print(datetime.now())
def thr():
threads = []
for i in range(10):
t = threading.Thread(target=test)
threads.append(t)
t.setDaemon(True)
for t in threads:
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
thr()
print("阻塞线程功能启动,end")这段代码,是不是让你有一种想喝(灭)水(火)的冲动??
那就对了,因为不能停止吗~ ~ ~ ~
那,这和什么都不设置不是一样???
莫着急,其实还是有一点区别的:
>>什么都不设置的情况下主线程是执行完的,仅等待子线程执行完,所以会打印end信息
>>而两个都设置的情况下,主线程会因为等待子线程结束而不往下执行,主线程无法执行完成,所以也就是无法关闭子线程,不会打印end信息
对于死循环这种情况,可以在join()设置timeout来控制
即,我们来设置个2秒钟,
for t in threads:
t.join(2)但是你执行之后,会发现,为啥不是2秒停止,而是20秒才停止,是因为我们执行了10个线程, 而每个线程执行2秒,故10个线程timeout时间就是20秒。
是不是不太讲究,哎~~没办法,就顺了吧!!
那么阻塞线程的意义是啥呢?
>>阻塞线程的意义在于控制子线程与主线程的执行顺序!
![]()