leetcode数据库题第八弹(免费题刷完了)
- 1757. 可回收且低脂的产品
- 1789. 员工的直属部门
- 1795. 每个产品在不同商店的价格
- 1873. 计算特殊奖金
- 1890. 2020年最后一次登录
- 1907. 按分类统计薪水
- 1934. 确认率
- 1965. 丢失信息的雇员
- 1978. 上级经理已离职的公司员工
- 2356. 每位教师所教授的科目种类的数量
- 小结
1757. 可回收且低脂的产品
https://leetcode.cn/problems/recyclable-and-low-fat-products/
一脸疑惑啊,这么简单的也可以放到题库里?多条件查询难道不应该是基础中的基础?
select product_id from products where low_fats='Y' and recyclable = 'Y'
想不明白这个题目到底想干嘛。。。。
1789. 员工的直属部门
https://leetcode.cn/problems/primary-department-for-each-employee/
。。。。又是入门题,如果考虑大量数据,那么就把 or 拆成 union 好了,反正在这里老顾懒得写 union。
select employee_id,department_id
from employee e
where primary_flag='Y' or not exists(select primary_flag from employee where employee_id=e.employee_id and department_id<>e.department_id)
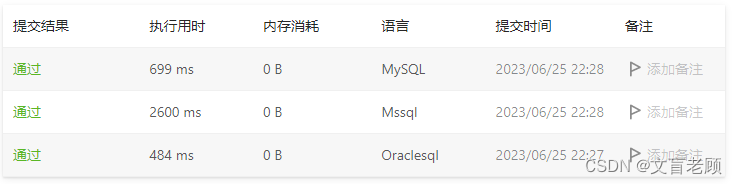
但是,实际看了看用时后,老顾决定还是换个玩法,毕竟这效率不太好。
然后就有看到 mysql 和 mssql 的差异来了,按照 primary_flag 的排序规则居然不一样。。。。汗。。。。
# mssql && oracle
select employee_id,department_id
from (
select e.*
,row_number() over(partition by employee_id order by primary_flag desc) rid
from employee e
) a
where rid=1
# mysql
select employee_id,department_id
from (
select e.*
,row_number() over(partition by employee_id order by primary_flag asc) rid
from employee e
) a
where rid=1
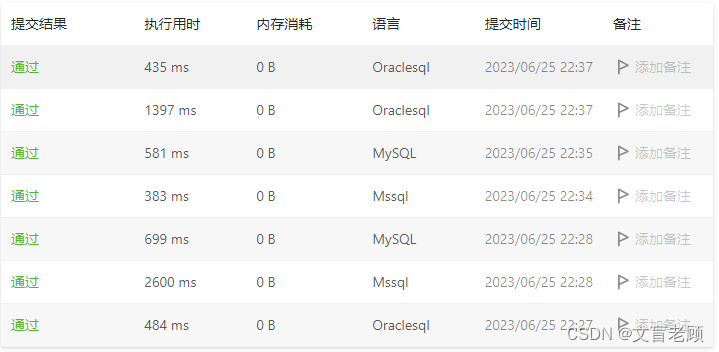
oracle 提升不明显,mssql 提升明显啊。
CSDN 文盲老顾的博客,https://blog.csdn.net/superwfei
1795. 每个产品在不同商店的价格
https://leetcode.cn/problems/rearrange-products-table/
呦,标准的列转行,而且是最简单的那种,没有干扰列。。。。
# mssql
select product_id,store,price
from products
unpivot(price for store in (store1,store2,store3)) p
先来个 mssql 特有的 unpivot,然后,放个通用的,用 union 搞一搞
select product_id,'store1' store,store1 price
from products
where store1 is not null
union all
select product_id,'store2' store,store2 price
from products
where store2 is not null
union all
select product_id,'store3' store,store3 price
from products
where store3 is not null
1873. 计算特殊奖金
https://leetcode.cn/problems/calculate-special-bonus/
字母开头不是m,且id是单数。。。。好吧,oracle 又和别人不一样
# oracle
select employee_id,(case when mod(employee_id , 2) = 1 and lower(substr(name,1,1))<>'m' then salary else 0 end) bonus
from employees
order by employee_id
# mssql && mysql
select employee_id,(case when employee_id % 2 = 1 and lower(substring(name,1,1))<>'m' then salary else 0 end) bonus
from employees
order by employee_id
1890. 2020年最后一次登录
https://leetcode.cn/problems/the-latest-login-in-2020/
嗯。。。。终于有用到日期函数的地方了?不容易啊。
还是同样的问题,oracle 加 to_char 修饰一下
# mysql && mssql
select user_id,max(time_stamp) last_stamp
from logins
where year(time_stamp)=2020
group by user_id
# oracle
select user_id,max(time_stamp) last_stamp
from logins
where to_char(time_stamp,'YYYY')='2020'
group by user_id
当然了,用 row_number 排名函数也是可以的,多套个子查询的问题罢了
1907. 按分类统计薪水
https://leetcode.cn/problems/count-salary-categories/
嗯。。。。这个题目还算有点意思,有超时的风险了,至少老顾的第一版本确实超时了一次
select a.category,ifnull(b.cnt,0) accounts_count
from (
select 'Low Salary' category,'l' lv
union
select 'Average Salary','a'
union
select 'High Salary','h'
) a
left join (
select lv,count(0) cnt
from (
select a.*,(case when income<20000 then 'l' when income>50000 then 'h' else 'a' end) lv
from accounts a
) a
group by lv
) b on a.lv=b.lv
然后发现这个题目,用最直接的办法,oracle 表现良好,mysql 其次,至少都没有超时风险,mssql 就一言难尽了
select 'Low Salary' category,count(0) accounts_count
from accounts
where income < 20000
union all
select 'High Salary' category,count(0) accounts_count
from accounts
where income > 50000
union all
select 'Average Salary' category,count(0) accounts_count
from accounts
where income between 20000 and 50000

而这个指令,在 mssql 居然有很严重的超时风险?
那么,就专门针对 mssql 写一版好了,不考虑通用性,只考虑性能好了。。。。。结果用了将近一个小时,没有把效率提高到安全先以内,任何指令都有超时风险。。。。
最后,老顾把超时的那个数据,扔到自己的服务器上跑了一下。。。嗯,秒出结果。。。。
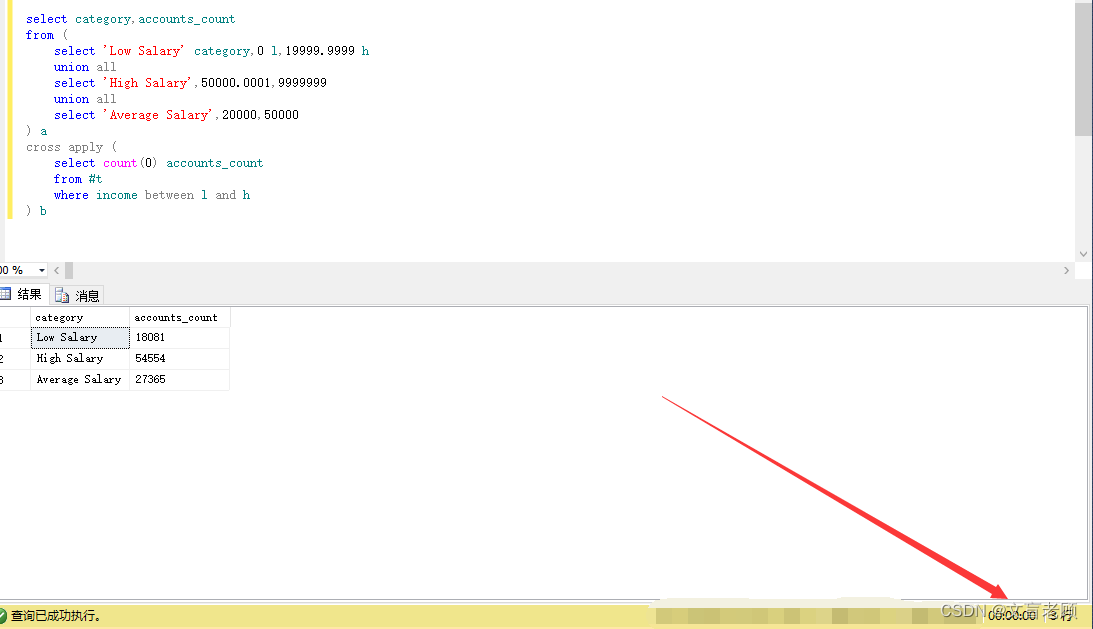
但是,这里要说一句但是,10万条数据,老顾扔到数据库里进行临时表建立,用时却不止6秒,平均8秒左右。。。。所以,亲们,不要再去折腾这个题目了,明显这个耗时,是包含数据插入的时间的,所以。。。太坑了,肯定是力扣的mssql版本的数据插入部分有问题!
下边是实测用时记录,10万数据转换用了7687毫秒,查询只用了57毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
表 'Worktable'。扫描计数 0,逻辑读取 19 次,物理读取 0 次,预读 0 次,lob 逻辑读取 6715 次,lob 物理读取 0 次,lob 预读 1680 次。
SQL Server 执行时间:
CPU 时间 = 4633 毫秒,占用时间 = 7687 毫秒。
(100000 行受影响)
SQL Server 分析和编译时间:
CPU 时间 = 89 毫秒,占用时间 = 89 毫秒。
(3 行受影响)
表 '#t__________________________________________________________________________________________________________________000000F4444D'。扫描计数 3,逻辑读取 633 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 47 毫秒,占用时间 = 57 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。
1934. 确认率
https://leetcode.cn/problems/confirmation-rate/
嗯,这个题目比上个题目简单吗?感觉是一样的,不过这次没有大数据集,所以感觉不出来
# mysql && oracle
select s.user_id,round(sum(case when action='confirmed' then 1.0 else 0.0 end) / count(0),2) confirmation_rate
from signups s
left join confirmations c on s.user_id=c.user_id
group by s.user_id
# mssql
select s.user_id,convert(decimal(5,2),sum(case when action='confirmed' then 1.0 else 0.0 end) / count(0)) confirmation_rate
from signups s
left join confirmations c on s.user_id=c.user_id
group by s.user_id
1965. 丢失信息的雇员
https://leetcode.cn/problems/employees-with-missing-information/
????两个表,并集一下,然后出现次数为1次的就是有丢失信息的人了。。。。
select employee_id
from (
select employee_id
from employees
union all
select employee_id
from salaries
) a
group by employee_id
having(count(0) = 1)
order by employee_id
1978. 上级经理已离职的公司员工
https://leetcode.cn/problems/employees-whose-manager-left-the-company/
逻辑捋一下,条件列清楚就好,一共三个条件
第一,薪水
第二,有领导
第三,领导离职
select e.employee_id
from employees e
left join employees p on e.manager_id=p.employee_id
where e.salary<30000 and e.manager_id is not null and p.employee_id is null
order by e.employee_id
2356. 每位教师所教授的科目种类的数量
https://leetcode.cn/problems/number-of-unique-subjects-taught-by-each-teacher/
额,有过类似的题目啊,不过这次还是稍微有点不一样,貌似数据集大了一些,结果就有了差异
select teacher_id,count(distinct subject_id) cnt
from teacher
group by teacher_id
那就换个写法好了
select teacher_id,count(0) cnt
from (
select distinct teacher_id,subject_id
from teacher
) a
group by teacher_id
小结
那么,到目前为止,力扣的所有免费的数据库题目就已经刷完了。
当然,这里没有太多的考虑效率问题,除非有超时风险的才会有不同写法。
在数据库中,同样的条件,可以使用的查询方式却可以有很多种方式来达成条件。对于不同的写法,会有不同的执行计划,效率也会产生差异。
对于数据库维护人员来说,先了解自己的指令到底有什么优点,有什么缺点,哪些地方可以通过一些外在手段减低消耗,提高效率,是一个需要长期摸索和尝试的内容。