背景
随着数据量的增大,数据库需要进行水平切分,例如通过业务主键id取模,使得数据均匀分布到不同的库中,随之而来的问题就出现跨库如何进行分页查询。
举例
select * from t_user order by time offset 200 limit 100当在单库单表进行查询的时候,是拥有全局视野的,当进行了水平切分后,就失去了全局视野,数据按照time局部排序之后,不管哪个分库的第3页数据,都不一定是全局排序的第3页数据。
全局视野法
由于失去了全局视野,怎么重新获取全局视野呢,每个库都返回3页数据,所得到的数据在服务层进行内存排序,得到数据全局视野,再取第3页数据,便能够得到想要的全局分页数据。
步骤:
- 将order by time offset X limit Y,改写成order by time offset 0 limit X+Y
- 服务层将改写后的SQL语句发往各个分库:即例子中的各取3页数据
- 假设共分为N个库,服务层将得到N*(X+Y)条数据:即例子中的6页数据
- 服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录,就是全局视野所需的一页数据
方案优点:通过服务层修改SQL语句,扩大数据召回量,能够得到全局视野,业务无损,精准返回所需数据。
方案缺点
- 每个分库需要返回更多的数据,增大了网络传输量(耗网络);
- 除了数据库按照time进行排序,服务层还需要进行二次排序,增大了服务层的计算量(耗CPU);
- 最致命的,这个算法随着页码的增大,性能会急剧下降,这是因为SQL改写后每个分库要返回X+Y行数据:返回第3页,offset中的X=200;假如要返回第100页,offset中的X=9900,即每个分库要返回100页数据,数据量和排序量都将大增,性能平方级下降。
业务折中法
全局视野法虽然深分页时候性能较差,但是返回数据准确,有没有性能更优的方案呢,业务需求的折中能够极大的简化技术方案。
业务折中-禁止跳页查询
在数据量很大,翻页数很多的时候,很多产品并不提供“直接跳到指定页面”的功能,而只提供“下一页”的功能,这一个小小的业务折衷,就能极大的降低技术方案的复杂度。
- 将查询order by time offset 0 limit 100,改写成order by time where time>0 limit 100
- 上述改写和offset 0 limit 100的效果相同,都是每个分库返回了一页数据
- 服务层得到2页数据,内存排序,取出前100条数据,作为最终的第一页数据,这个全局的第一页数据,一般来说每个分库都包含一部分数据
- 点击“下一页”时,需要拉取第二页数据,在第一页数据的基础之上,能够找到第一页数据time的最大值,将查询order by time offset 100 limit 100,改写成order by time where time>$time_max limit 100,这下不是返回2页数据了(“全局视野法,会改写成offset 0 limit 200”),每个分库还是返回一页数据
- 服务层得到2页数据,内存排序,取出前100条数据,作为最终的第2页数据,这个全局的第2页数据,一般来说也是每个分库都包含一部分数据,如此往复,查询全局视野第100页数据时,不是将查询条件改写为offset 0 limit 9900+100(返回100页数据),而是改写为time>$time_max99 limit 100(仍返回一页数据),以保证数据的传输量和排序的数据量不会随着不断翻页而导致性能下降。
业务折中-允许数据精度损失
全局视野法能够返回业务无损的精确数据,在查询页数较大,例如第100页时,会有性能问题,如果业务上面能够接收返回数据不是那么精准,允许有一些数据偏差,那么可以大大减少技术的实现难度。
例如使用业务主键id取模,理论上在各个分库上的数据分布,统计概率情况是一致的。
利用这一原理,要查询全局100页数据,offset 9900 limit 100改写为offset 4950 limit 50,每个分库偏移4950(一半),获取50条数据(半页),得到的数据集的并集,基本能够认为,是全局数据的offset 9900 limit 100的数据,当然,这一页数据的精度,并不是精准的。
总结:业务折中法需要需求上面进行相应让步,可以搭配上各种搜索条件,能够提高相应精度,也是可以满足多数场景的。
二次查询法
二次查询法能够满足业务的精确需要,无需业务折中,又高性能的方法。
为了方便举例,假设一页只有5条数据,查询第200页的SQL语句为select * from T order by time offset 1000 limit 5
步骤一:查询改写
将select * from T order by time offset 1000 limit 5
改写为select * from T order by time offset 500 limit 5
并投递给所有的分库,注意,这个offset的500,来自于全局offset的总偏移量1000,除以水平切分数据库个数2。
如果是3个分库,则可以改写为select * from T order by time offset 333 limit 5
假设这三个分库返回的数据(time, uid)如下:
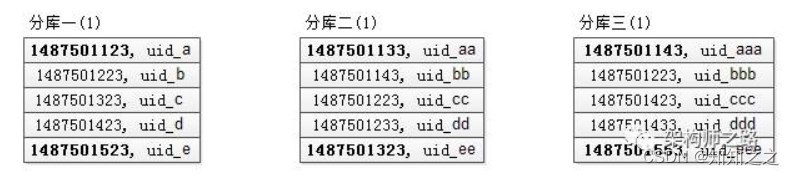
可以看到,每个分库都是返回的按照time排序的一页数据。
步骤二:找到所返回3页全部数据的最小值
第一个库,5条数据的time最小值是1487501123
第二个库,5条数据的time最小值是1487501133
第三个库,5条数据的time最小值是1487501143

故,三页数据中,time最小值来自第一个库,time_min=1487501123,这个过程只需要比较各个分库第一条数据,时间复杂度很低
步骤三:查询二次改写
第一次改写的SQL语句是select * from T order by time offset 333 limit 5
第二次要改写成一个between语句,between的起点是time_min,between的终点是原来每个分库各自返回数据的最大值:
第一个分库,第一次返回数据的最大值是1487501523
所以查询改写为select * from T order by time where time between time_min and 1487501523
第二个分库,第一次返回数据的最大值是1487501323
所以查询改写为select * from T order by time where time between time_min and 1487501323
第三个分库,第一次返回数据的最大值是1487501553
所以查询改写为select * from T order by time where time between time_min and 1487501553
相对第一次查询,第二次查询条件放宽了,故第二次查询会返回比第一次查询结果集更多的数据,假设这三个分库返回的数据(time, uid)如下:

可以看到:
由于time_min来自原来的分库一,所以分库一的返回结果集和第一次查询相同(所以其实这次访问是可以省略的);
分库二的结果集,比第一次多返回了1条数据,头部的1条记录(time最小的记录)是新的(上图中粉色记录);
分库三的结果集,比第一次多返回了2条数据,头部的2条记录(time最小的2条记录)是新的(上图中粉色记录);
步骤四:在每个结果集中虚拟一个time_min记录,找到time_min在全局的offset
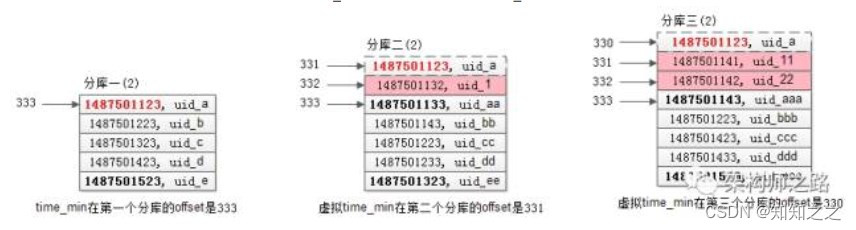
在第一个库中,time_min在第一个库的offset是333
在第二个库中,(1487501133, uid_aa)的offset是333(根据第一次查询条件得出的),故虚拟time_min在第二个库的offset是331
在第三个库中,(1487501143, uid_aaa)的offset是333(根据第一次查询条件得出的),故虚拟time_min在第三个库的offset是330
综上,time_min在全局的offset是333+331+330=994
步骤五:既然得到了time_min在全局的offset,就相当于有了全局视野,根据第二次的结果集,就能够得到全局offset 1000 limit 5的记录
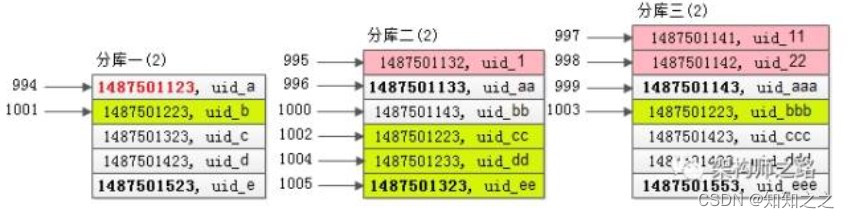
第二次查询在各个分库返回的结果集是有序的,又知道了time_min在全局的offset是994,一路排下来,容易知道全局offset 1000 limit 5的一页记录(上图中黄色记录)。
这种方法的优点是:可以精确的返回业务所需数据,每次返回的数据量都非常小,不会随着翻页增加数据的返回量。
不足是:需要进行两次数据库查询,实现复杂。