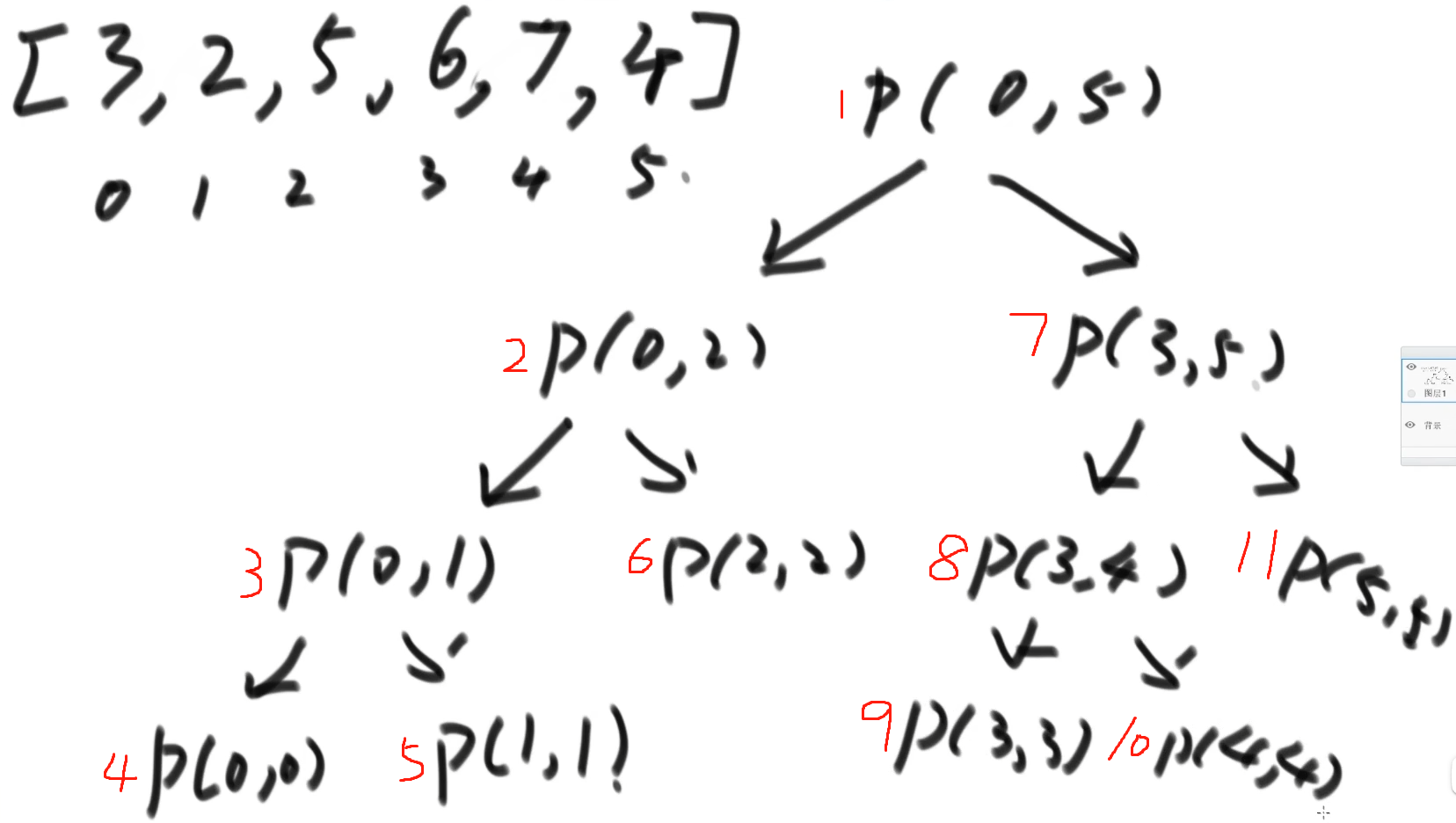文章目录
- 一、数据读取和处理
- 1.Pub/Sub
- 代码实践
- Publishing
- Subscribing
- 2. Dataflow
- 使用Python搭建Pipeline
- 3. Dataproc
- 4. Cloud Data Fusion
- 5. 其他工具
- Cloud Composer (Apache Airflow)
- Cloud Scheduler
- 二、可视化与分析
- 1. Looker
- 2. Looker Studio
- 3. BigQuery
- 三、预处理和后处理
- 1. 数据传输
- 2. Dataprep
- 四、机器学习
- 1. BigQuery ML
- 2. Pre-built API
- 3. AutoML
- 4. Vertex AI
- 五、大数据和数据库的一些简单概念
我们可以将GCP大数据和机器学习服务分为以下四类:数据读取和处理、存储、分析、机器学习,一个完整的工作流程如下图所示
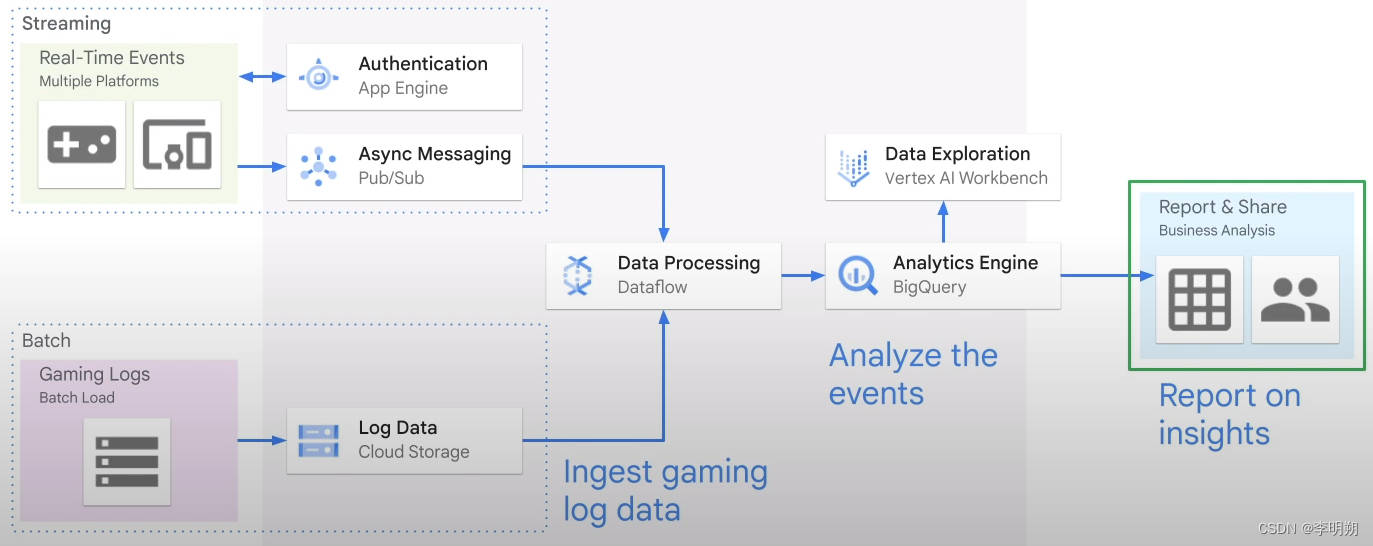
一、数据读取和处理
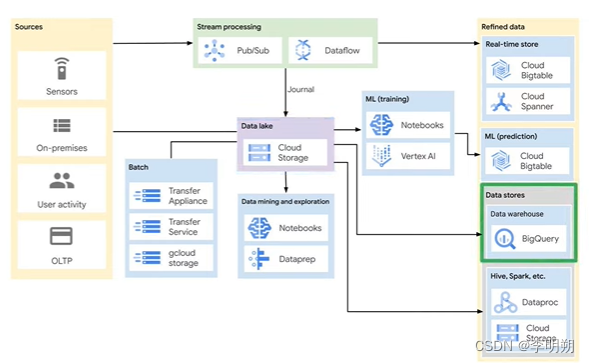
数据读取和处理服务包括:Pub/Sub、 Dataflow、 Dataproc、 Cloud Data Fusion。
数据质量的五个指标包括:
- valid:数据和商业规则不匹配。使用SQL中的过滤方法(WHERE、HAVING)来筛选数据。
- accurate:数据的值不正确。使用SQL创建测试例子(新列)来检查数据是否准确。
- complete:创建/保存数据集失败,多数由于缺失值。使用SQL中IFNULL等方法查找空值。
- consistent:数据计算错误,多数由于重复值。使用SQL中的COUNT方法寻找重复值。
- uniform:同一列不同行的值含义不同。使用SQL中UNIFORM或者CAST方法来转换数据类型。
Batch Processing:在一组存储数据上进行处理和分析,例如支付系统
Streaming Data processing:由数据源产生的流式数据,数据的处理随着数据在系统中的流动,产生对数据的分析,这意味着流式数据几乎是实时分析
加载数据的方式取决于数据需要进行多少转换,包括
- EL:从Cloud Storage抽取数据,加载到BigQuery,可以通过Cloud Function或者定时查询方式来引发。要求数据已经是干净、准确的
- ELT:EL与上面相同,加载完毕后使用BigQuery view来进行数据转换。数据需要进行简单的转换例如scaling,可以在SQL中处理
- ETL :在数据管线中进行转换,之后再从数据管线写入数据仓库
ETL的几种方案:
- Dataflow to BigQuery:常用方案
- Dataflow to Bigtable:低延迟、throughput
- Dataproc:使用Spark管线
- Cloud Data Fusion:可视化管线搭建
1.Pub/Sub
Pub/Sub全称为Publisher/Subscriber,是一个分布式消息服务,可以从多个设备流中读取数据例如IOT设备,默认为Global,提供端到端编码。可能存在延迟、乱序、重复等问题。
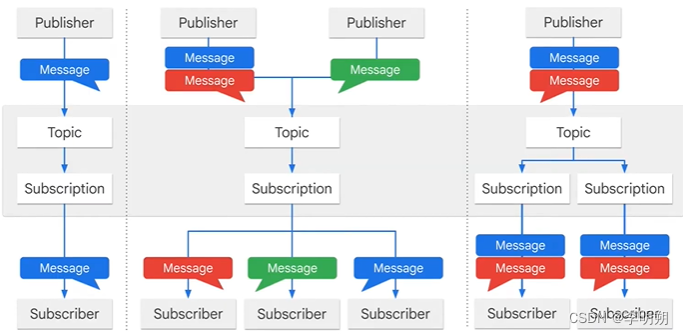
Pub/Sub的工作流程如下图
Pub/Sub的工作流程:
- 发布者向topic发送消息
- 消息存储在消息存储中,直到它们被订阅者传递和确认
- Pub/Sub 将消息从topic转发给订阅者。 消息可以由 Pub/Sub 推送给订阅者或由订阅者从 Pub/Sub 中拉取
- 订阅者从订阅中接收待处理消息并确认发布/订阅
- 订阅者确认消息后,它会从订阅者的消息队列中删除。
发布/订阅的模式可分为以下几种:
- 1对1:1个发布者发布的topic被1个订阅者订阅
- 负载均衡,多个发布者发布相同的topic,多个订阅者接收相同的订阅
- fan out:数据被发送到多个订阅者
Push和Pull两种发送方式:
- Pull:订阅者会周期性的寻找信息,Pub/Sub会发送信息,最后返回ACK。信息会存储7天。
- Push:通常是HTTP终端,Pub/Sub会发送最新信息,之后返回ACK。
每次订阅都需要返回ACK,超过限制时间消息会重新发送。
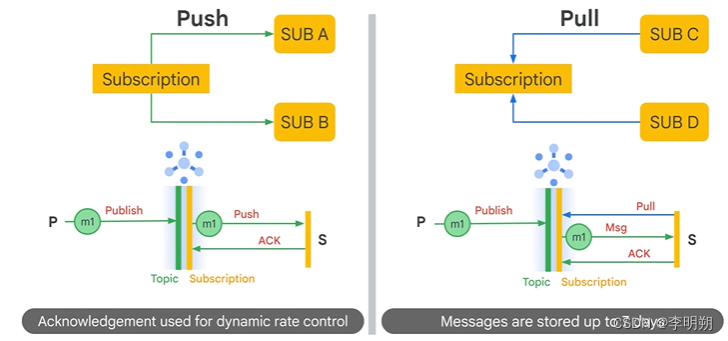
Pub/Sub的一些特点:
- streaming resilience:将信息发送效率限制在系统可以处理的速度上
- dead letter sinks、 error logging:Pub/Sub 可以将无法传送的消息转发到dead letter(是一种订阅主题),可以配置传送尝试次数上限等。
- exponential back off:重新尝试之前不断增加尝试间隔
- 消息重放机制:通过配置主题的message_retention_duration可以保留订阅和主题消息。可以通过快照来还原至主题的任何订阅。
- 消息排序:发布者指定排序键,键的作用是同一个键的消息都要排序。订阅者要打开排序特性。这样做会对性能产生损伤。
Pub/Sub去重
- 维护一个数据库表来存储每个数据条目的哈希值和其他元数据。
- Cloud Pub/Sub 为每条消息分配一个唯一的 message_id,可用于检测订阅者收到的重复消息。
- 在以下情况下可能会发生大量重复消息: 端点未在确认期限内确认消息
代码实践
Publishing
# create topic
gcloud pubsub topics create sandiego
# publish to topic
gcloud pubsub topics publish sandiego --message "hello"
# Create a client
import os
from google.cloud import pubsub_v1
publisher = pubsub_v1.PublisherClient()
topic_name ='projects/{project_id}/topics/{topic}'.format(
project_id=os.getenv('GOOGLE_CLOUD_PROJECT'),
topic='MY_TOPIC_NAME',
)
publisher.create_topic(topic_name)
publisher.publish(topic_name, b'My first message!', author='dylan')
Subscribing
async pull
import os
from google.cloud import pubsub_v1
subscriber = pubsub_v1.SubscriberClient()
topic_name ='projects/{project_id}/topics/{topic}'.format(
project_id=os.getenv('GOOGLE_CLOUD_PROJECT'),
topic='MY_TOPIC_NAME',
)
subscription_name ='proiects/{proiect_id}/subscriptions/{sub})'format(
proiect_id=os.getenv('GOOGLE_CLOUD_PROJECT'),
Sub='MY_SUBSCRIPTION_NAME'
)
subscriber.create_subscription(
name=subscription_name, topic=topic_name)
def callback(message):
print(message.data)
message.ack()
future = subscriber.subscribe(subscription_name, callback)
synchronous pull
# Create subscription
gcloud pubsub subscriptions create --topic sandiego mySub1
# Pull subscription
gcloud pubsub subscriptions pull --auto-ack mySub1
# Create a client
import time
from google.cloud import pubsub_v1
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project_id,subscription_name)
NUM_MESSAGES =2
ACK_DEADLINE = 30
SLEEP_TIME 10
# The subscriber pulls a specific number of messages
response = subscriber.pull(subscription_path,max_messages=NUM_MESSAGES)
2. Dataflow
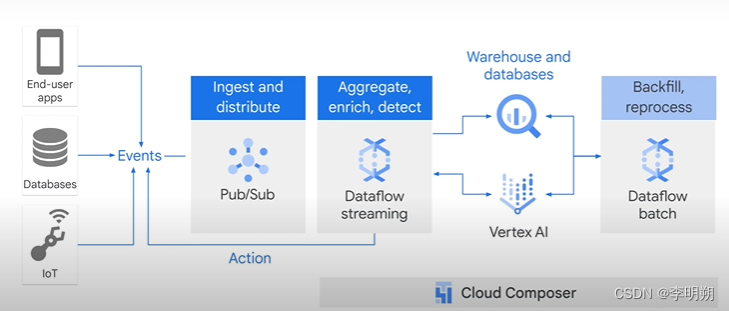
Apache Beam:是一个开源的模型来定义和运行数据处理管道,包括ETL、Batch/Streaming processing。
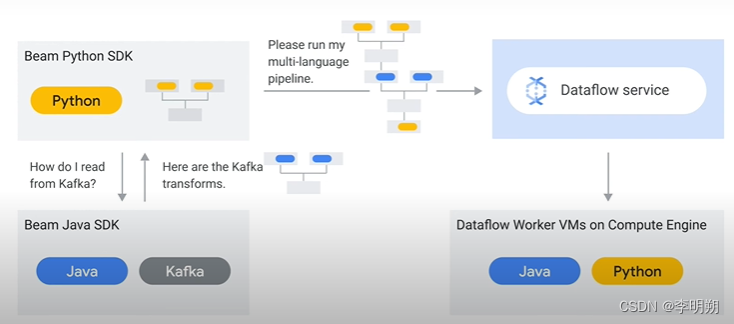
Beam portability:可以理解成一个中间操作层,可以提供跨语言、自定义Docker环境等支持。其中跨语言支持如下图:
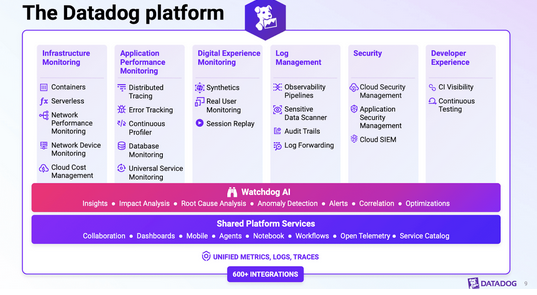
Dataflow是一个全部管理的服务用来在谷歌云执行Apache Beam数据管道。Dataflow是一种serverless和NoOps(自动维护、监控、autoscaling)服务。其服务包括:
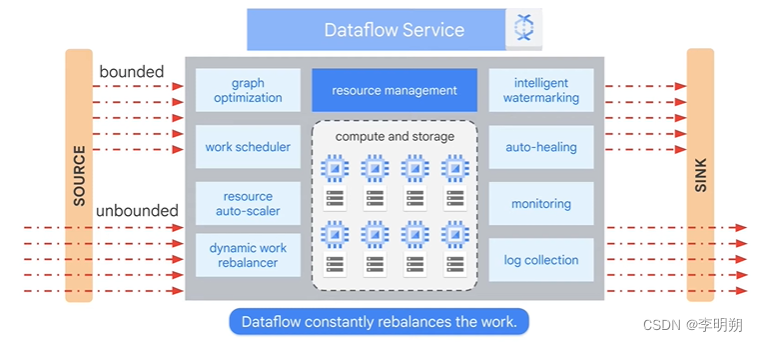
Dataflow的工作流程可以如下图所示:
- Element:数据的单个条目(例如表行)
- PCollection:分布式数据集,输入输出
- Transform:管道中的数据处理
- ParDo:转换类型,可以使用side input

可以使用 Google App Engine Cron 服务创建 cron 作业来运行 Cloud Dataflow 作业
Dataflow模板允许用户快速部署标准任务类型,总共分为三种:
- Streaming:处理连续实时数据,Dataflow Streaming Engine
- Batch:处理批处理数据,Dataflow shuffle服务
- Utility:Bulk compression、deletion、conversion
Dataflow的安全性:
- IAM:developer允许与Dataflow job进行交互,worker提供Compute Engine service account来运行Dataflow工作流节点。
- Data locality:确保数据和元数据在一个区域里
- shared VPC
- private IP:禁用外部IP
更新pipeline的方法:使用drain flag(停止pipelilne并更新)、 json mapping(处理兼容性问题)
Dataflow中的window,可以自定义trigger
- fixed (Tumbling ):每周、每月,包含连续不重叠的时间块
- sliding (Hopping):通过窗口大小和滑动间隔来确定
- sessions:时间块不固定,一般用来捕捉一段时间内的行为
Trigger决定数据到达时何时发出聚合结果。 默认情况下,当watermark经过窗口末尾时发出结果。Apache Beam SDK 可以设置在以下条件的任意组合下运行的触发器:
- 事件时间,由每个数据元素上的时间戳指示。
- 处理时间,是在管道中任何给定阶段处理数据元素的时间。
- 集合中数据元素的数量。
from apache_beam import window
fixed_windowed_items =(
items| 'window'>> beam.WindowInto(window.FixedWindows(60)))
sliding_windowed_items =(
items| 'window'>>beam.WindowInto(window.SlidingWindows(30,5)))
session_windowed_items =(
items | 'window'>> beam.WindowInto(window.Sessions(10 *60)))
由于事件发生的时间和事件经过处理的时间存在延迟,Dataflow的windows中使用Watermarks提供一个lag time来处理晚到的消息队列,一旦消息晚于lag time,我们可以选择是否继续等待。
搭建Pipeline的三种方式:
- 通过模板加载
- 通过Apache beam SDK写代码加载
- 通过SQL加载
使用Python搭建Pipeline
PCollection_out = (PCollection_in| PTransform_1
| PTransform_2
| PTransform_3)
# branching pipeline
PCollection_out_1 = PCollection_in] PTransform_1
PCollection_out_2 = PCollection_in] PTransform_2
使用Python运行Dataflow Pipeline
import apache_beam as beam
if __name__ =='__main__':
with beam.Pipeline(argv=sys.argv) as p:
(p
| beam.io.ReadFromText('gs://...') # read input
| beam.FlatMap(count_words) # apply transform
| beam.io.WriteToText('gs://...') # write output
)
# end of with-clause: runs,stops the pipeline
我们可以自定义Pipeline的一些参数
import apache_beam as beam
options ={'project': <project>,
'runner':'DataflowRunner',
'region': <region>,
'setup_file': <setup.py file>)
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **options)
pipeline = beam.Pipeline(options = pipeline_options)
读取输入
with beam.Pipeline(options=pipeline_options) as p:
# Read from Cloud Storage (returns a string)
lines = p | beam.io.ReadFromText("gs://.../input-*.csv.gz")
# Read from Pub/Sub (returns a string)
lines = p | beam.io.ReadStringsFromPubSub(topic=known_args.input_topic)
# Read from BigQuery (returns rows)
query = "SELECT x,y,Z FROM 'project.dataset.tablename'"
BQ_source = beam.io.BigQuerySource(query = <query>,use_standard_sql=True)
BQ_data = pipeline | beam.io.Read(BQ_source)
输出
from apache_beam.io.gcp.internal.clients import bigquery
# Establish reference to BigQuery table
table_spec = bigquery.TableReference(
projectId='clouddataflow-readonly',
datasetId='samples',
tableId='weather_stations')
# Write to BiqQuery table
p | beam.io.WriteToBigQuery(
table_spec,
schema=table_schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE,
create_disposition=beamio.BigQueryDisposition.CREATE_IF_NEEDED)
转换
# Map (fn) uses a callable fn to do a one-to-one transformation.
'WordLengths'>> beam.Map(word,len(word))
# FlatMap is similar to Map, but fn returns an iterable. The iterables are flattened into one PCollection. Non 1:1 relationship
def my_grep(line, term):
if term in line:
yield line
'Grep'>> beam.FlatMap(my_grep(line,searchTerm))
# Pardo: filter/format dataset, extract element, simple computation
# 可以在Pardo添加side input
words = ...
class ComputeWordLengthFn(beam.DoFn):
def process(self, element):
return [len(element)]
word_lengths = words | beam.ParDo(ComputeWordLengthFn())
# 聚合函数:GroupByKey(group)、Combine(group)、Faltten(merge)、Partition(split)
# Window:数据默认存在与Global Window里,即从第一个数据开始到最后一个数据结束,我们可以使用Window来处理时间序列问题(按时间分组)
# SlidingWindows代表每个窗口持续60秒,每过30秒开始一个新窗口
beam.WindowInto(beam.window.SlidingWindows(60,30))
3. Dataproc
Dataproc是基于Apache Hadoop和Spark的数据处理服务。
Dataproc定制化集群的两种方法:
- optional component:预定义集群
- initialization actions:通过脚本自定义集群
Dataproc集群的结构:
- 主节点
- workers
- primary workers
- preemptible secondary workers
- non-preemptible secondary workers
- HDFS:当虚拟机关机数据会丢失,可以使用其他GCP存储服务
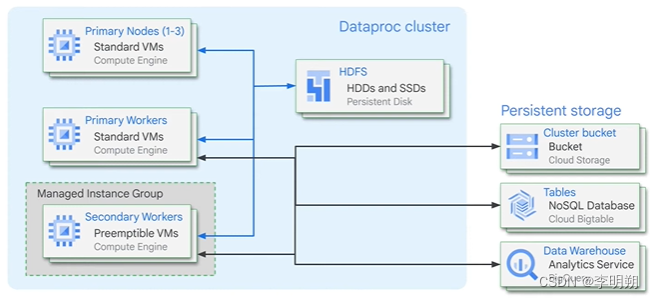
使用Dataproc的步骤:
- 设置:通过console、YAML文件或命令行创建集群
- 配置:集群可以被认为是一个虚拟机,需要配置区域、节点等信息
- 优化:使用preemptible VM,自定义镜像、CPU等可以降低成本
- 使用:开始一个任务
- 监控:使用Cloud Monitor来监控
优化Dataproc:
- 数据区域和集群区域相邻,Auto Zone
- 不要同时处理超过10000输入文件
- 存储方式选择
- HDFS:需要有很多元数据操作、经常修改HDFS文件、需要重命名路径、经常使用append操作、经常使用I/O操作、I/O操作需要非常敏感的延迟
- Cloud Storage:建议默认使用
- 使用Dataproc模板:通过REST API或者命令行使用YAML文件来完成搭建集群等任务
- auto scaling
4. Cloud Data Fusion
Cloud Data Fusion是一个图形化的、无代码的数据管线。主要针对batch data。
Data Fusion的组成部分:
- 控制中心:可以从整体上查看数据集、管线
- 管线:搭建工作流程,可以预览、导出、管理一个项目
- wrangler:为数据集进行数据准备,数据转换、数据质量检查
- rules engine:商业数据转换、指定规则
- 元数据:追踪数据流程
- hub:可用插件
- entities:
- administration
数据管线——有向无环图:有向无环图中有一系列阶段,每个阶段可以是不同的类型,例子如下图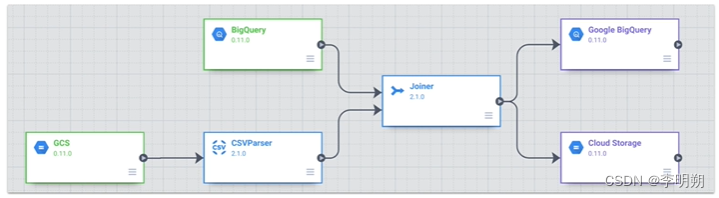
5. 其他工具
Cloud Data Catalog:是一个serverless数据发现和元数据管理服务。
Cloud Composer (Apache Airflow)
Cloud Composer是一个管理引擎,用来控制多个GCP服务的运行。Cloud Composer的结构也是一个有向无环图。
Airflow使用operator在有向无环图中来管理其他GCP服务。具体的operator参考官方文档 Google Cloud Operators。
Cloud Composer scheduling的方法:
- 周期性:设定周期来调用
- 事件驱动:使用Cloud Function来调用
使用Python的一个例子
from airflow.contrib.operators import *
# update training data, 指定SQL语句
t1 = BigQueryOperator()
# BigQuery training data export to GCS
t2 = BigQueryToCloudStorageOperator()
# AI Platform training job
t3 = MLEngineTrainingOperator()
# App Engine deploy new version
t4 = AppEngineVersionOperator()
# DAG dependencies
t2.set_upstream(t1)
t3.set_upstream(t2)
t4.set upstream(t3)
Cloud Scheduler
二、可视化与分析
可视化与分析服务包括BigQuery、Looker、Looker Studio
1. Looker
Looker支持BigQuery等超过60个SQL数据库,使用Looker建模语言来定义数据的逻辑。
2. Looker Studio
Looker Studio与Looker不同的地方在于不需要管理的支持来获得数据连接。
建立Looker Studio Dashboard的步骤:
- 选择模板
- 将dashboard与数据源连接
- 探索dashboard
Looker Studio的缓存机制:Looker Studio通过临时存储数据来提高性能并降低查询成本,通过设置数据新鲜度(data freshness)来更新数据。
3. BigQuery
BigQuery是一个全管理的数据仓库,可以存储和分析数据。全管理是指无需考虑BigQuery的部署、安全和可扩展性。BigQuery是column oriented, 通常UTF-8编码。其工作流程如下
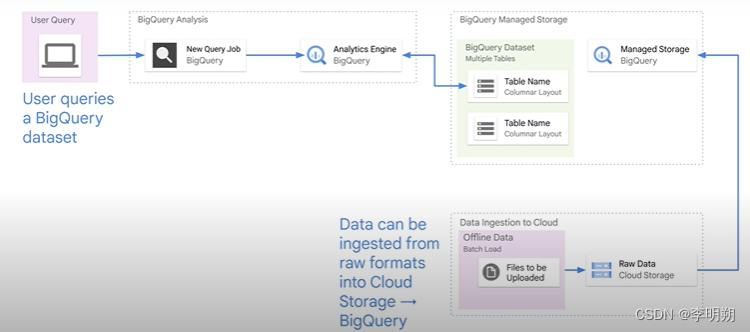
BigQuery的特点
- 与其他 GCP 服务集成:它与各种 GCP 服务(如 Dataflow、Cloud Storage 和 Data Studio)无缝集成,用于数据摄取、存储和可视化。
- 交互方式:网站、命令行、REST API
- 组织结构:项目——数据集——表
- 数据类型:数值型数据、String型数据、日期型数据、其他(布尔型、数组、结构体)
- 任务类型:查询(付费)、导入表、导出表、复制表。
- 可扩展性:BigQuery 可以通过其分布式架构处理和分析海量数据集,无论数据大小如何都可以快速执行查询。
- partitioned tables:分区表被分成多个段,称为分区, 通过将大表划分为较小的分区,您可以通过减少查询读取的字节数来提高查询性能并控制成本。不能修改现有表进行分区。
- normalize:将较大的表分解为较小的相关表,以减少数据重复并提高整体数据库性能。 在规范化模式中,每条信息只存储一次,避免数据不一致和异常。
- denormalize:来自多个表的数据组合到一个表中,以通过减少所需的连接数来提高查询性能。通过对数据进行非规范化,您可以简化复杂的查询并优化数据检索,尤其是在处理聚合和报告时。 当优先考虑读取性能并且可以容忍数据冗余时,通常使用反规范化。
- 外部数据库:指可以直接从 BigQuery 查询的数据源,即使数据未存储在 BigQuery 中。 通过直接查询外部数据源,无需在每次数据发生变化时都将数据重新加载到 BigQuery 存储中。
- 视图:由 SQL 查询定义的虚拟表。可以使用视图为复杂查询或一组有限的数据提供易于重用的名称,然后可以授权其他用户访问这些名称。
- 可以导出为Json/CSV.Avro类型文件,可以通过GZIP压缩
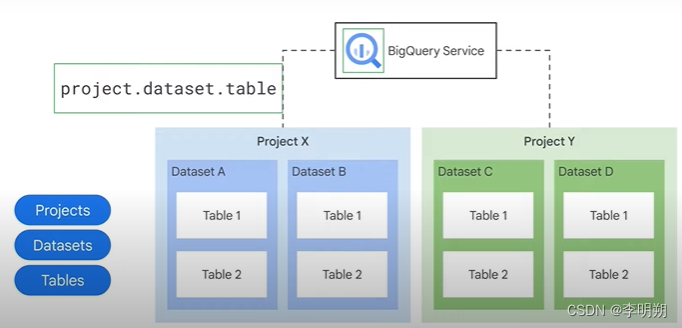
BigQuery权限控制:
- IAM:BigQuery Admin, BigQuery Data Viewer, or BigQuery Job User, project和dataset级别
- Identity-Aware Proxy (IAP):细粒度控制
- authorized view:可以将查询结果分享给特定用户同时不允许他们访问原始数据,可以仅分分享特定的行或列,可以建立一共额外的数据集来存储视图
Bigquery的优化查询:
- 规范化数据库设计将有助于最大限度地减少数据冗余并提高查询效率。
- 当想修改列的数据类型时,可使用query或者新建表。使用query方便但是会产生很大的查询费用,新建表需要额外的存储费用
- 考虑对性能关键型查询的架构进行非规范化,以最大限度地减少 JOIN 操作。
- 根据逻辑边界对表进行分区,以减少查询期间扫描的数据量。
- 使用集群根据特定列以物理方式组织数据,以提高查询性能。
- Schema设计:
- normalize:更好的组织结构、性能优化较差
- denormalize:增加查询速度、使查询更简单
- nested and replicated fields
- anti-patterns
- 避免self-join:自联接用于计算依赖于行的关系。如果使用自联接,它可能会对输出行数进行平方运算。输出数据的增加可能会导致性能变差。
- 避免cross-join:避免使用产生的输出多于输入的联接。
- 避免不均衡分区:在使用 JOIN 子句时,对联接两侧的数据执行 Shuffle 操作,可能会导致槽过载。
- 避免数据倾斜:数据倾斜是指数据分入大小极不均匀的分区这种情况,应该提前进行过滤。
一些SQL基础:
- LIMIT:限制返回结果数量,即使使用LIMIT,也会扫描全表
- ORDER BY:排序,DESC为降序
- FORMAT:格式化结果
- AS:重命名列名为一个别名
- WHERE:筛选结果,不能使用别名
- HAVING: 筛选聚合结果
- CAST:数据类型转换
- LEAD:
- RANK:
- GIS函数:ST_DWithin、 ST_GeogPoint、 ST_Makeline等
- 尽量避免使用 SELECT *
- 聚合函数:SUM(), COUNT(), AVG(), MAX()
- 内置函数:ROUND(保留小数位)
- 处理NULL类型数据
三、预处理和后处理
1. 数据传输
AVRO数据格式:
- 加载速度更快。 即使数据块被压缩,数据也可以并行读取。
- 不需要打字或序列化
- 更容易解析,因为其他格式有一些不明编码的问题,例如Ascii
- 不支持编写AVRO文件,但是编写的数据块是。 Bigquerysupts deflate and ntappy编解码器
在GCP中,数据传输是指GCP生态系统中各种服务,区域或环境之间数据的移动。 GCP提供了几种机制和工具来促进数据传输,每个机制都有不同的目的和方案。 以下是GCP中数据传输的一些常见方法:
- 基于网络的数据传输:GCP提供了高性能和安全的网络基础架构,用于在同一区域内或不同区域内的资源之间传输数据。
- 云存储传输服务:Google Cloud Storage提供了一个名为Cloud Storage Transfer Service的专用服务,该服务使您可以在本地系统,其他云存储提供商和Google Cloud Storage之间传输数据。 它支持一次性转移和重复转移,使您能够自动化数据移动和同步任务。
- BigQuery数据传输服务:BigQuery数据传输服务简化了将数据加载到Google BigQuery的过程,该服务可自动化数据提取,转换和加载(ETL)过程,从而使数据更容易摄入大量数据进行分析。
- 传输设备(Transfer Appliance):对于大规模数据传输,GCP提供了传输设备,即在数据中心部署的硬件设备。 可以将数据加载到设备上,然后将其运送到Google中以摄入GCP存储或计算服务。 当您拥有大量的数据时,这种方法很耗时或不切实际,可以通过网络转移。
- 在线交易(Online Transactions)的数据传输服务:用于从在线交易处理(OLTP)数据库(例如Oracle,MySQL和SQL Server)传输数据到Google Cloud Cloud数据库,例如Cloud SQL或Cloud Spanner 。 DTO降低了数据迁移的复杂性,并帮助有效地将数据库工作负载转换为GCP。
- 如果要传输大量文件,则可能需要使用gsutil -m选项,以执行并行(多线程/多处理)副本
- 将较小的文件压缩和组合到更少的较大文件中也是加速传输速度的最佳实践
2. Dataprep
Google Cloud Dataprep 是一项完全托管的数据准备和转换服务,可帮助清理、转换和可视化原始数据以进行分析和下游处理。 它提供了可视化的界面和强大的数据转换能力,让用户无需编写代码即可准备数据。
Dataprepd的架构/组件:
- Dataprep UI:用户交互和配置数据准备步骤的可视化界面。
- 数据连接器:支持从各种来源(包括文件、数据库和云存储)摄取数据的连接器。
- 转换器库:一组预构建的转换和函数,可应用于数据进行清理和转换。
- Recipe:一组数据准备步骤和转换组织成一个可重用的工作流程。
- 数据流:一组精心编排的配方和依赖项,用于定义端到端的数据准备工作流程。
- 作业执行环境:底层
Dataprepd的工作流程:
- 导入数据:连接到文件、数据库或云存储等数据源,并将原始数据导入 Dataprep。
探索和剖析数据:Dataprep 提供数据剖析功能,以了解数据的结构、质量和统计特征。 您可以直观地探索数据并确定需要解决的问题。 - 清理和转换数据:使用可视化界面应用各种转换、过滤、聚合和丰富步骤,根据您的要求清理和重塑数据。
- 预览和验证:预览转换后的数据以确保正确应用所需的更改。 在进行进一步的转换之前验证结果。
- 创建配方和数据流:将您的数据准备步骤组织成可重复使用的配方和数据流。 配方允许您将相同的转换应用于其他数据集,而数据流提供了一种编排多个配方和构建端到端数据准备工作流的方法。
- 执行和安排作业:按需执行数据准备作业或安排它们以特定时间间隔运行。 Dataprep 自动处理执行和资源管理。
- 导出或集成:将转换后的数据导出到您想要的目的地,例如 Google BigQuery、Google 表格或其他云存储。 您还可以将 Dataprep 与其他数据处理或分析工具集成以进行进一步分析。
Dataprepd的主要特征:
- 可视化数据准备:Dataprep 提供了一个直观的可视化界面,使用户能够使用各种内置转换和函数来探索、清理和转换数据。
- 可扩展性和性能:Dataprep 旨在处理大规模数据处理,利用 Google Cloud 基础架构的强大功能来确保高性能和可扩展性。
- 数据连接器:Dataprep 支持各种数据连接器来访问来自多个来源的数据,例如 Google Cloud Storage、BigQuery、关系数据库等。
- 数据转换库:Dataprep 提供丰富的预建转换和函数库,可轻松执行复杂的数据准备任务。
- 协作和共享:Dataprep 允许用户在数据准备项目上进行协作、共享数据流并维护版本历史记录以实现更好的团队协作。
四、机器学习
使用GCP搭建机器学习系统分为三个层次,分别是AI基础、AI开发平台和AI解决方案。
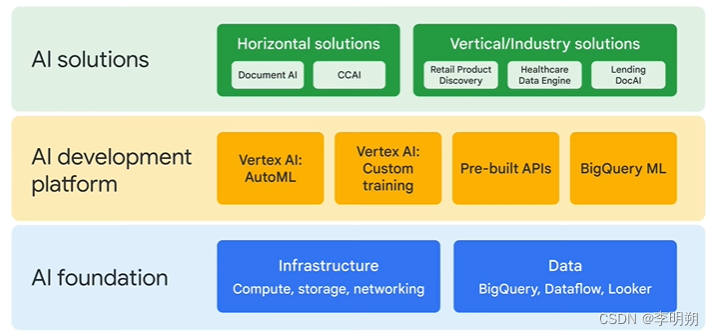
AI开发包括Vertex AI、AutoML,AI解决方案包括Document AI、Contact Center AI等。
搭建AI开发平台的四种方式:Bigquery ML、预训练API、AutoML、自定义训练。四种方式对比如下

1. BigQuery ML
我们可以在BigQuery中使用SQL查询语句来创建和运行机器学习模型。步骤如下:
- ETL,将数据加载到BigQuery
- 选择并预处理特征
- 使用CREATE MODEL命令创建模型
- 使用ML.EVALUATE评估模型表现
- 使用SQL预测语句来调用ml.PREDICT
以下是BigQuery 支持的模型

BigQuery ML的常见命令:
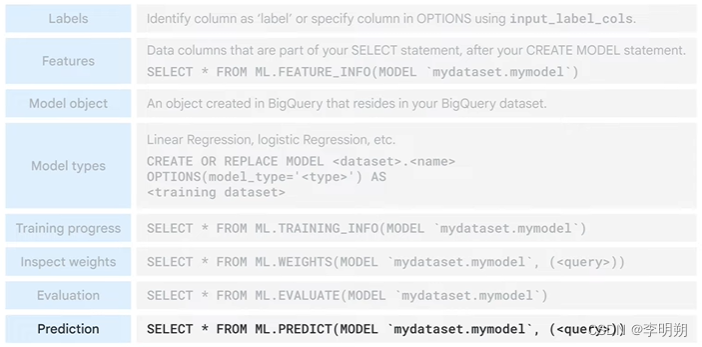
2. Pre-built API
GCP的预建立API包括:
- Speech-to-text API:语音转化为文字
- Cloud Natural Language API:识别实体和情感
- Cloud Translation API:翻译
- Text to Speech API:文本转化语音
- Vision API:识别图片
- Video intelligence API:识别视频
3. AutoML
AutoML是一种不需要代码的解决方案来搭建模型。其核心有两点:
- 迁移学习:
- 神经架构搜索:自动搜索最优模型
AutoML的数据来源可以是Cloud Storage、Big Query或者本地路径。其主要处理以下数据:
- 图片:图片分类、目标检测
- 结构化数据:回归模型、分类模型、时序数据预测,使用Auto ML Table
- 文本:文本分类、实体抽取、情感分析
- 视频:视频分类、目标跟踪、姿态识别
使用AutoML的过程包括训练、部署、服务。其中训练过程中,我们需要准备好原始数据集。数据集保存在csv文件中,第一列代表数据组别(训练集、验证集、测试集),第二列为数据的保存位置,第三列为标签。在部署过程中,模型会在一段时间后被删除,所以我们需要周期性的训练模型。
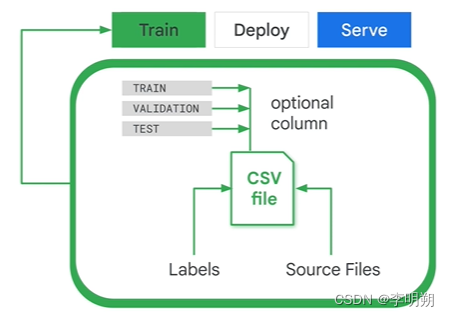
4. Vertex AI
Vertex AI支持AutoML和自定义训练。
自定义训练环境分为两种:
- 预定义容器:已经预安装了Tensorflow、Scikit Learn等软件包
- 自定义容器:需要自己安装所需要的软件包
Vertex AI提供以下特征以帮助训练和部署“
- Feature Store:用来管理特征
- Vizier:帮助调整超参数
- Explainable AI:帮助解释模型
- Pipelines:帮助自动化和监控机器学习生产线,可以在AI Hub中使用其他人完成的Pipeline
Vertex AI的Pipelines如下图所示
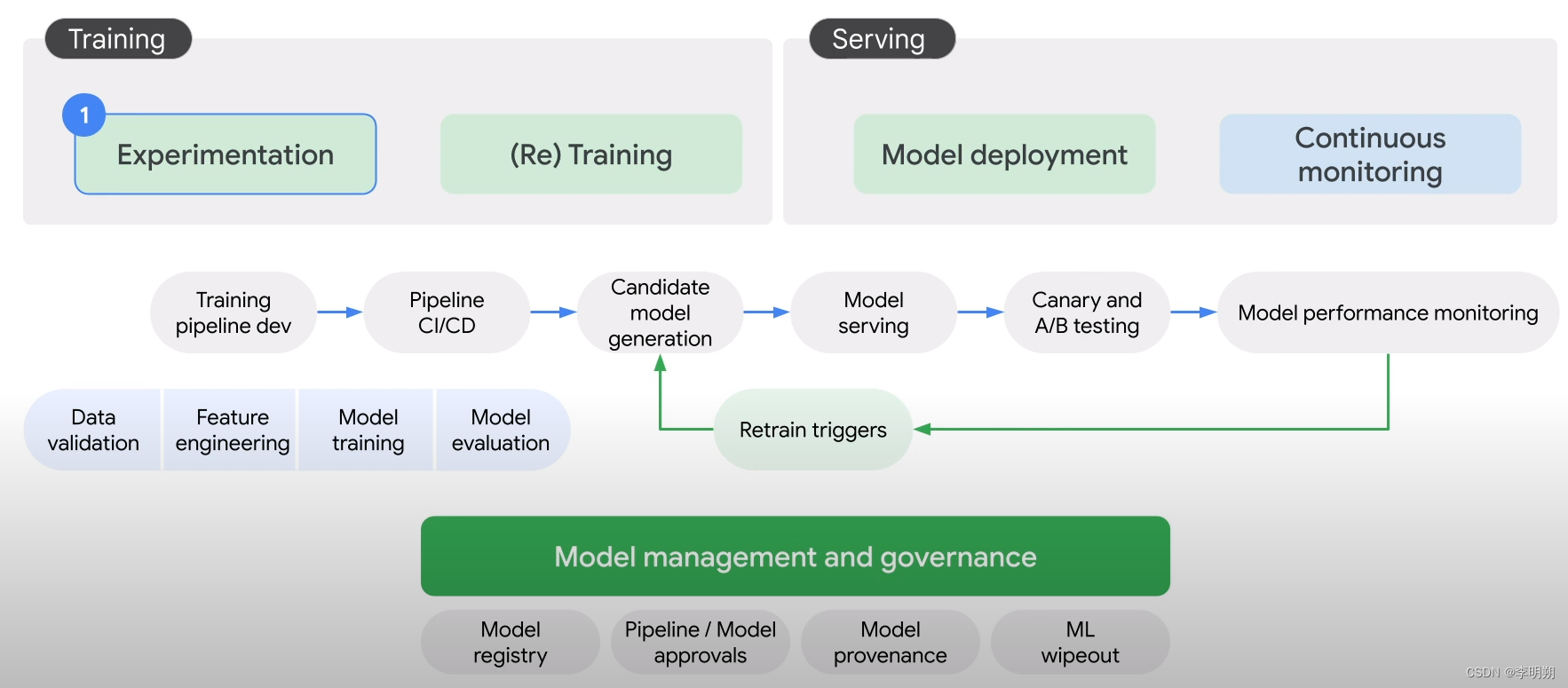
训练一个机器学习模型的工作流程包括:
- 数据准备:上传数据、特征工程
- 模型训练:模型训练、模型评估
- 模型服务:模型部署、模型监控,三种部署方式
- Endpoint:实时预测
- Batch Prediction:非实时预测,例如定时投送广告
- Offline Prediction:需要部署在特定环境
Notebook是运行在computer engine实例中,我们可以定义其实例类型、GPU等。
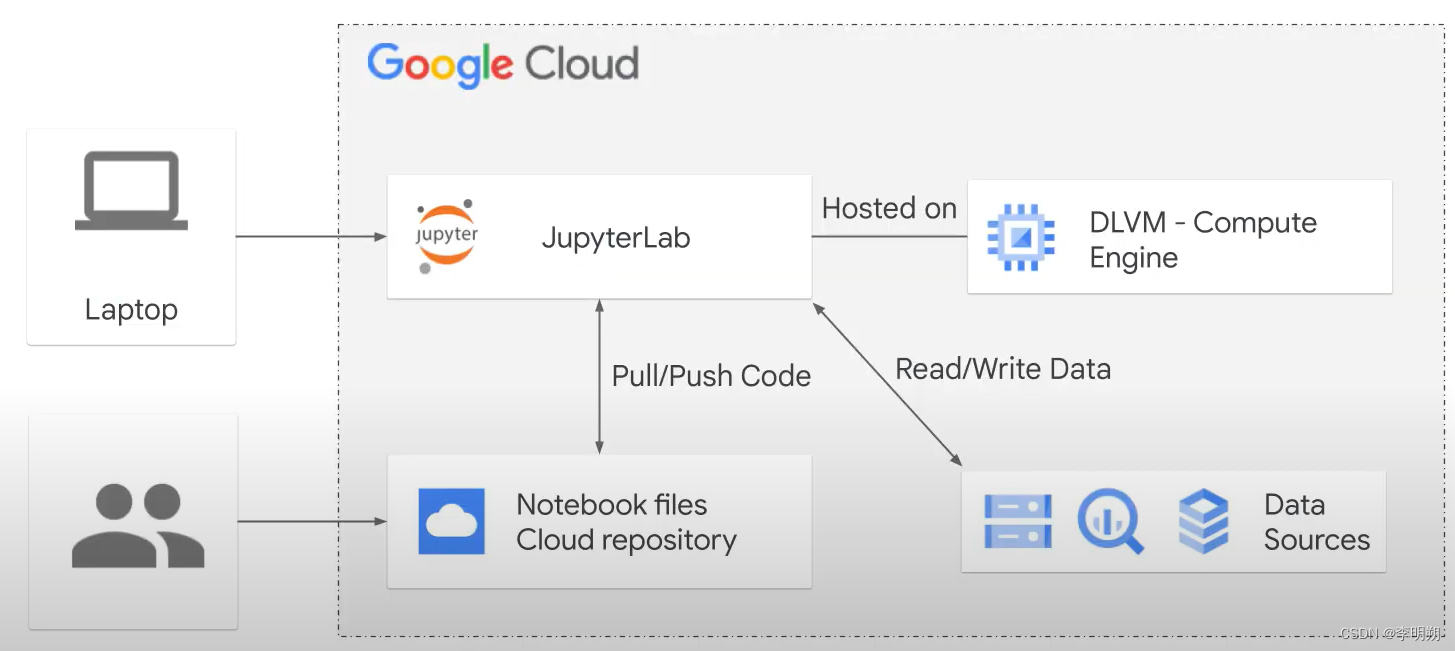
Notebook中的魔法方法:我们可以在notebook中运行BigQuery命令,将BigQuery结果保存到pandas的dataframe中,例如
%%bigquery df
SELECT
*
FROM
'bigquery-public-data.austin_bikeshare.bikeshare_trips'
WHERE
end_station_name = 'Stolen'
print(type(df))
df.head()
结果是一个dataframe表
五、大数据和数据库的一些简单概念
Hadoop:
- 开源MapReduce框架
- Dataproc的底层技术
HDFS:Hadoop的文件系统
Pig:编译成 MapReduce 作业的脚本语言
Hive:数据仓库系统和查询语言
Spark:
- 快速、通用目标的框架
- 用更快速的在内存中的办法解决MapReduce问题
Sqoop:
- 在 Hadoop 和结构化数据存储(关系)之间传输数据
- Sqoop 将数据从关系数据库系统或导入 HDFS。
- 在 Dataproc Hadoop 集群上运行 Sqoop 让您可以访问内置的 Google Cloud Storage 连接器
- 可以使用 Sqoop 将数据直接导入 Cloud Storage
Oozie:
- 用于管理 Apache Hadoop 作业的工作流调度程序系统
- Oozie Workflow 作业是操作的有向无环图 (DAG)
Cassandra:
- 基于BigTable和DynamoDB(Datastore)的宽列存储
- 拥有一个非常繁重的写入系统并且您希望在存储的数据之上拥有一个响应迅速的报告系统的问题的解决方案。
- 不提供 ACID 和关系数据属性
- 支持最终一致性的可用的分区容错系统
- 可能的替代品:Datastore
MongoDB:适用于系统需要schema-less文档存储的用例。
Hbase:可能适用于搜索引擎、分析日志数据或需要扫描大的二维无连接表的任何地方。
Redis:旨在为各种数据结构(如树、队列、链表等)提供内存中搜索,非常适合制作实时排行榜