文章目录
- 1. 编译器工作流
- 1.1. 解析(Parsing)
- 1.2. 遍历(Traversal)
- 1.3 转换(Transformation)
- 1.4 代码生成(Code Generation)
1. 编译器工作流
编译器是将一种语言转化为另一种语言的程序。在编译器工作流中,通常可以分为以下几个步骤:
- 解析(Parsing):解析是将最初原始的代码转换为一种更加抽象的表示(即AST)
- 转换(Transformation):转换将对这个抽象的表示做一些处理。让它能做到编译器期望它做到的事情
- 代码生成(Code Generation):接收处理之后的代码表示,然后把它转换成新的代码
1.1. 解析(Parsing)
- 解析一般分为两个阶段:词法分析(Lexical Analysis)和语法分析(Syntactic Analysis)。
- 词法分析:将源代码分解为一系列词法单元,如标识符、关键字、运算符等。这可以被称为
Token,Token 是一个数组,由一些代码语句的碎片组成,它们可以是数字、标签、标点符号、运算符或者其它任何东西。 - 语法分析:将词法单元(Token)转化为语法树,检查代码是否符合语法规则。抽象语法树是一个嵌套程度很深的对象,用一种更容易处理的方式代表了代码本身,也能给我们更多信息。
- 词法分析:将源代码分解为一系列词法单元,如标识符、关键字、运算符等。这可以被称为
示例一:
原始js代码:
<h1 id="title"><span>hello</span>world</h1>
Token示例:
[
{ type: 'Punctuator', value: '<' },
{ type: 'JSXIdentifier', value: 'h1' },
{ type: 'JSXIdentifier', value: 'id' },
{ type: 'Punctuator', value: '=' },
{ type: 'String', value: '"title"' },
{ type: 'Punctuator', value: '>' },
{ type: 'Punctuator', value: '<' },
{ type: 'JSXIdentifier', value: 'span' },
{ type: 'Punctuator', value: '>' },
{ type: 'JSXText', value: 'hello' },
{ type: 'Punctuator', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'JSXIdentifier', value: 'span' },
{ type: 'Punctuator', value: '>' },
{ type: 'JSXText', value: 'world' },
{ type: 'Punctuator', value: '<' },
{ type: 'Punctuator', value: '/' },
{ type: 'JSXIdentifier', value: 'h1' },
{ type: 'Punctuator', value: '>' }
]
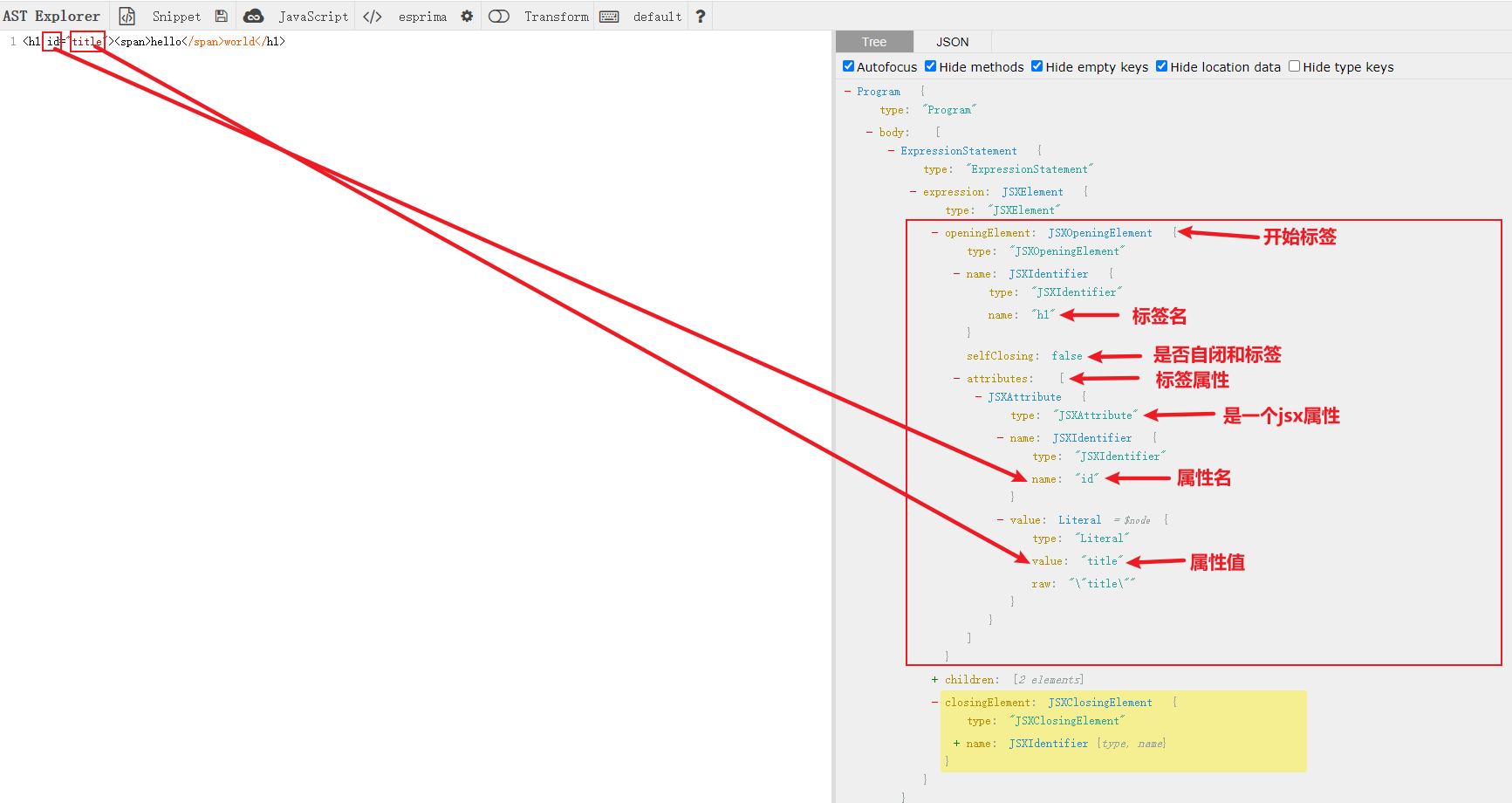
抽象语法树(AST):
将上面的js放到astexplorer中可以生成以下结构:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "JSXElement",
"openingElement": {
"type": "JSXOpeningElement",
"name": {
"type": "JSXIdentifier",
"name": "h1"
},
"attributes": [
{
"type": "JSXAttribute",
"name": {
"type": "JSXIdentifier",
"name": "id"
},
"value": {
"type": "Literal",
"value": "title"
}
}
]
},
"children": [
{
"type": "JSXElement",
"openingElement": {
"type": "JSXOpeningElement",
"name": {
"type": "JSXIdentifier",
"name": "span"
}
"attributes": []
},
"children": [
{
"type": "JSXText",
"value": "hello"
}
],
"closingElement": {
"type": "JSXClosingElement",
"name": {
"type": "JSXIdentifier",
"name": "span"
}
}
},
{
"type": "JSXText",
"value": "world"
}
],
"closingElement": {
"type": "JSXClosingElement",
"name": {
"type": "JSXIdentifier",
"name": "h1"
}
}
}
}
]
}
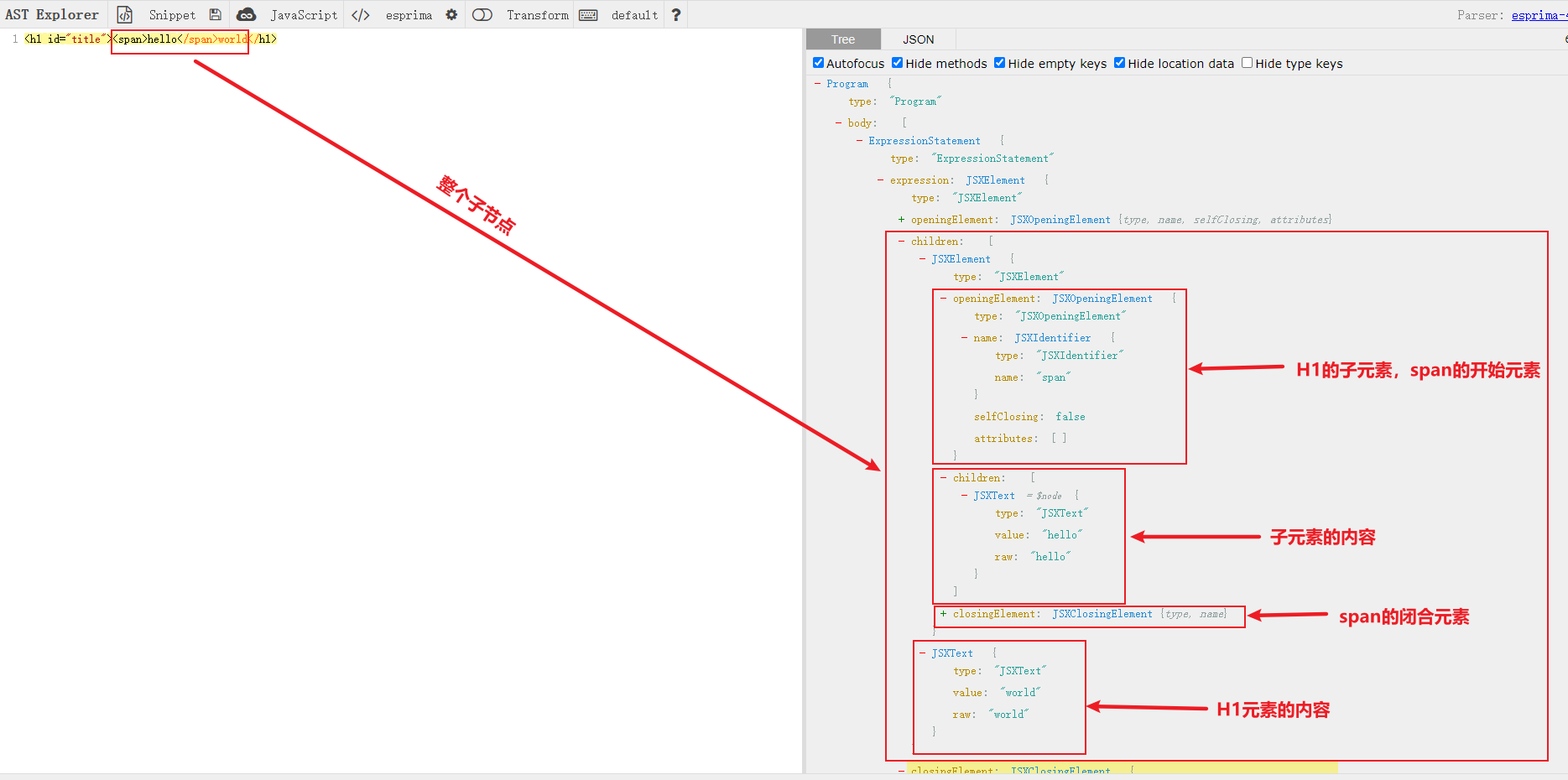
以上就是解析的基本过程。
示例二:利于exprima实现ast
1.新建一个package.json文件
npm init
2.安装 esparima 包
npm install esprima
3.导入 esparima
let esprima = require("esprima");
4.执行以下代码
vscode安装Code Runner
let esprima = require("esprima");
let sourceCode = `<h1 id="title"><span>hello</span>world</h1>`;
// jsx: true表示支持jsx;tokens: true表示打印tokens,默认不打印
let ast = esprima.parseModule(sourceCode, { jsx: true, tokens: true });
console.log(ast);
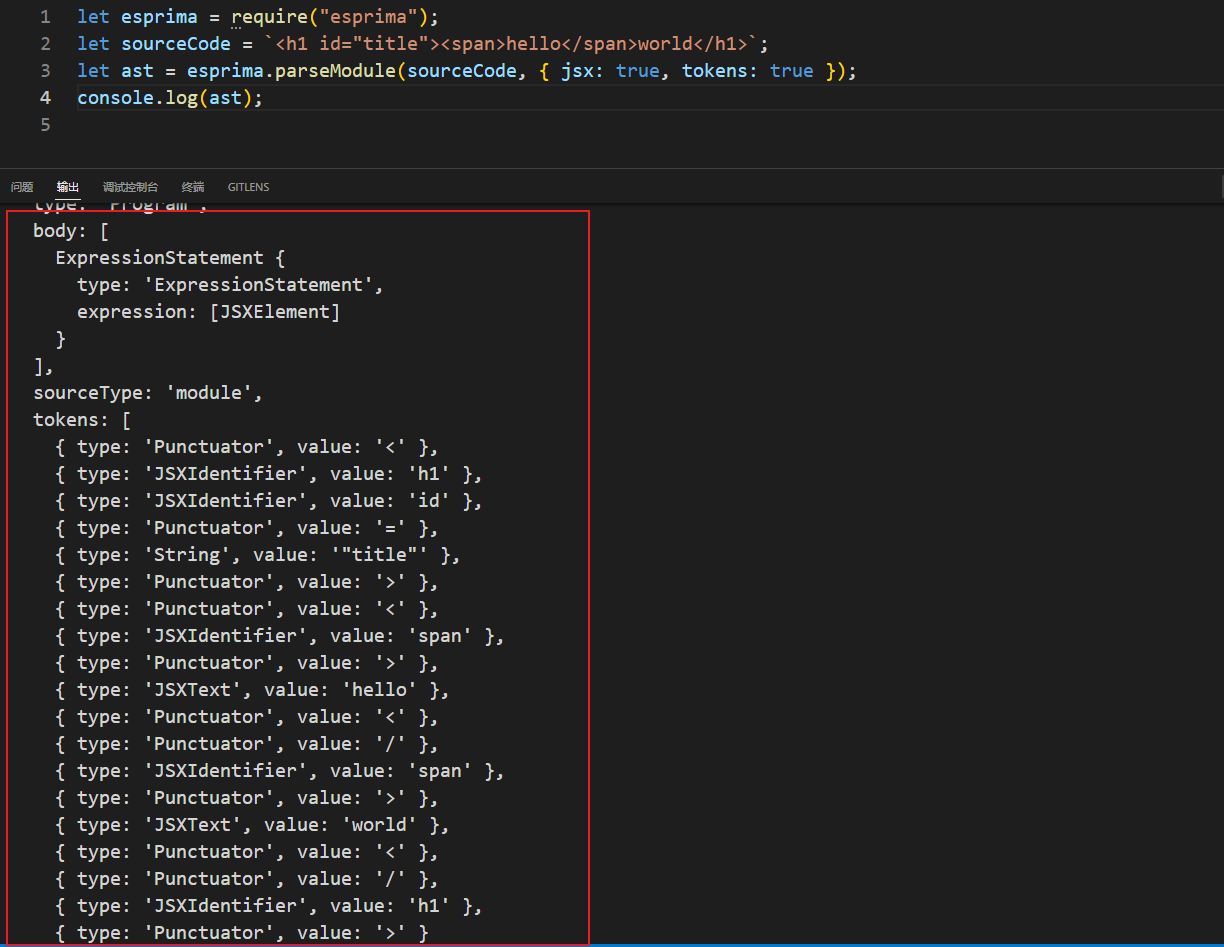
esorima 内部要得到抽象语法树,需经过两个步骤:
1.把源代码进行分词,得到一个tokens的数组
2.把tokens数组转成一个抽象语法树
1.2. 遍历(Traversal)
- 将jsx转换成抽象语法树之后,为了能处理所有的节点,需要采用深度优先遍历
1.安装 estraverse
npm install estraverse-fb
2.导入 estraverse
let estraverse = require("estraverse-fb");
3.执行以下代码
let esprima = require("esprima"); //把JS源代码转成AST语法树
let estraverse = require("estraverse-fb"); //遍历语法树,修改树上的节点
let sourceCode = `<h1 id="title"><span>hello</span>world</h1>`;
// jsx: true表示支持jsx;tokens: true表示打印tokens,默认不打印
let ast = esprima.parseModule(sourceCode, { jsx: true, tokens: true });
// console.log(ast);
// 间距
let tab = 0;
function padding() {
return " ".repeat(tab);
}
estraverse.traverse(ast, {
enter(node) {
// 进入
console.log(padding() + node.type + "进入");
tab += 2;
},
leave(node) {
// 离开
console.log(padding() + node.type + "离开");
tab -= 2;
},
});
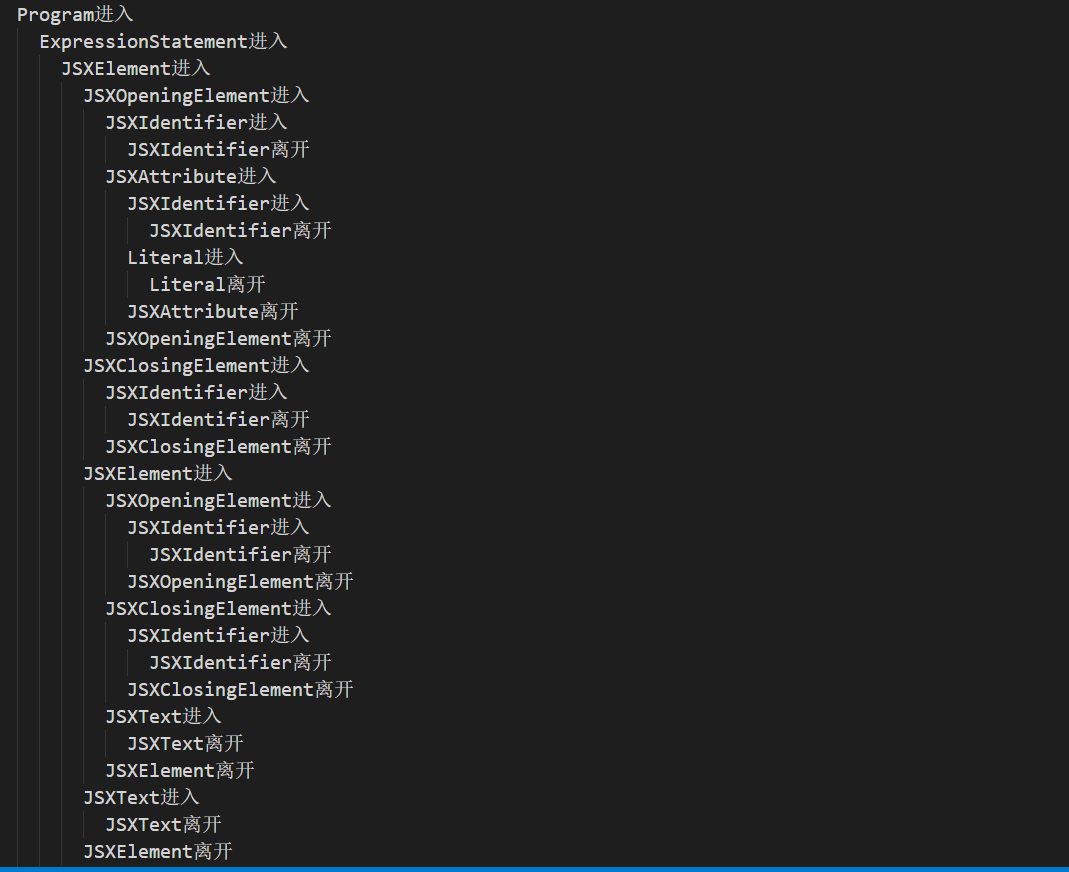
1.3 转换(Transformation)
- 编译器的下一步就是转换,它只是把 AST 拿过来然后对它做一些修改。它可以在同种语言下操作 AST,也可以把 AST 翻译成全新的语言(如vue转换成react,java转换成js等等)。
- 你或许注意到了我们的 AST 中有很多相似的元素,这些元素都有
type属性,它们被称为AST结点。这些结点含有若干属性,可以用于描述AST的部分信息 - 当转换 AST 的时候我们可以
添加、移动、替代这些结点,也可以根据现有的 AST 生成一个全新的 AST。 - 既然我们编译器的目标是把输入的代码转换为一种新的语言,所以我们将会着重于产生一个针对新语言的全新的 AST。
1.4 代码生成(Code Generation)
- 编译器的最后一个阶段是代码生成,这个阶段做的事情有时候会和转换(transformation)重叠,但是代码生成最主要的部分还是根据 AST 来输出代码。
- 代码生成有几种不同的工作方式,有些编译器将会重用之前生成的
token,有些会创建独立的代码表示,以便于线性地输出代码。但是接下来我们还是着重于使用之前生成好的 AST。 - 我们的代码生成器需要知道如何打印AST 中所有类型的结点,然后它会递归地调用自身,直到所有代码都被打印到一个很长的字符串中。