文章目录
- 概述
- JD 岗位描述
- 一面
- 二面
- 三面
- HR面
概述
根据会议将面试问题进行总结,很多问题感觉当时没回答好,这是为啥呢?应该还是不熟练吧,或者不善于表达。将次经历分享出来,大家多练练。
JD 岗位描述
私有云平台运维 JD 腾讯云智研发子公司
1.私有云产品的自动化部署及运维交付管理;2.赋能和培养合作伙伴团队,支撑私有云产品部署;
3.产品故障定位和排查,以及维护工作;
4.备注:此岗位为腾讯集团旗下子公司编制岗位。
岗位要求
1.熟练掌握Linux常用命令,熟悉IaaS和常用云产品运维部署,有常见问题的排查经验;
2.掌握shell/python脚本开发,有云平台自动化运维开发经验为加分项;
3.熟悉docker/容器日常运维;熟练掌握K8S运维及故障排查,熟悉其工作机制,熟悉tcs为加分项;
4.熟悉大数据相关服务或者即时通讯领域,大数据要求熟悉hadoop核心组件和框架,熟悉clickhouse使用;即时通讯要求对网络及相关排障比较熟悉;
5.有一定带人或者团队管理经验;
6.备注:此岗位为腾讯集团旗下子公司编制岗位。
一面
HR没有提前约,我只是给了简历。
广东深圳的一个座机打过来就开始问了。
- 你了解虚拟化技术吗?
- kvm virtualbox
- 你主要做什么运维工作?
- k8s的有哪些组间?都是什么关系?
- etcd你了解吗?k8s怎么用?一般存的什么东西?
- etcd 有30gb数据, follower节点同步数据只有3gb。为什么会这么少呢?(例如有个用了很久的集群etcd member大小超过30g,这时候用一个新的etcd学习那个节点只有3g 是什么原因呢)
- 会不会有一些脏数据呢?
- k8s遇到最复杂的故障是什么?
- 两个节点上的pod不通可能是什么原因呢?
- k8s的网络插件有几种?有什么区别和不同?
- dockerfile编写有哪些注意点?
- 容器的启动命令?
- helm file原理?有实际写过吗?
- k8s都有哪些对象?什么场景使用?
- mysql 集群怎么同步数据?
- mysql有哪些锁?
- python有开发哪些脚本?
- prometheus语法了解多少?
- cicd 用了哪些组间?
- ansible playbook会用吗?
- coredump分析过没有?
- linux内核有没有编译过?
- tcpdump解决过什么问题?
- linux 性能优化印象最深刻的是什么?
- 你最大的优点和缺点?
- 最近在看什么书?
结束的很突然,感觉已经挂了
二面
06、21 19:30
面试了27分钟。
江XX
- 自我介绍?
- k8s master 几个节点?我: 三个,高可用节点?面: 为什么是3个?
- etcd 的运维?优化?
- k8s 组件的介绍?关系? <>
- k8s做过什么优化?
有什么要问的呢?
该岗位的工作职责是什么?
腾讯云 产品交付。侧重于TOB
感受:
这位面试官感觉不是很善言谈。问问题也吞吞吐吐的。遇到这种面试官应该主动出击。
例如谈到master 高可用,为什么要三个节点,因为自建的k8s集群是堆叠式的部署方式,etcd 和 k8s 的master共用。k8s master 高可用主要就是kube-apiserver组件的高可用。因为kube-apiserver是有状态的一个应用。只有它才会和后端etcd进行交互保存数据。之所以要用三个节点,这样有利于etcd的故障恢复。etcd 是一个分布式的KV 键值存储系统,基于raft共识协议,当leader节点挂掉之后,follower会以超过半数为原则进行选主。 如果是两个节点也可以做到高可用,但是raft协议的选主过程可能会经历多轮选举才有结果,这段时间etcd 拒绝写入任何数据。
这时候可以说一些关于如何选主的过程? 面试官没问不代表不能说。就是把整个问题的相关的你知道的都倒出来,这样才有利于面试官对你的理解。
这时候你可以说具体是如何选主的?
etcd leader 节点会不停的和follower节点发送心跳,follower节点有一个election_timeout。多个follower的election_timeout 不会同时开始计时, 当leader 节点发送的心跳follower节点未收到,这时follower节点就开始进行选主,拉取选票,多数同意即可成为leader。这是就会把不通的member踢掉。
加入网络发生了分区?会影响数据写入吗?
3个节点和5个节点如何选择呢?
主要看集群规模,100节点以下建议3个节点,否则5个节点。
为了让运维压力小一点,建议5个节点,这样就允许可以同时down掉两个节点,也不会影响分布式系统的运作。
CAP? 可用性 、 一致性、分区容任性
三面
2023年6月25日19:30:00
谭XX 面试官
问题
共27分钟,面试官有准备几个题目让现场回答。
问答题:
- 你做了和k8s相关的运维工作?面试官让具体说说(我balabala了3分钟)
- 使用的哪个版本?为什么 1.22.10? 有什么考量?
- master 几个节点 ? 高可用是如何做的?
- haproxy如何检测节点是否正常?(health check 6443端口)haproxy需要配置vip吗?keepalived 作用?
- 网络插件使用的什么?作用主要是什么?SVC-CIDR / POD-CIDR 在哪里配置?calico 如何给pod分配IP?(这块竟然不深入calico细节…….)
- 监控用什么(prometheus operator)?都配置了哪些指标?pod的内存和cpu是什么组件上报的(kubelet)?
笔试题目:
一共四道题,第一个题目整蒙了,一直没理解面试官的意图
- 请用kubectl 查询下每个节点CPU剩余的可以调度的资源
k get node
k describe node master1
request:
cpu: 1000m
k top node
]# k top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master-node1 487m 13% 5305Mi 35%
k8s-worker-node1 247m 7% 3173Mi 21%
k8s-worker-node2 269m 7% 3455Mi 23%
这里的cpu cores 指的是什么意思?
有五个节点每个节点8 个cpu core,创建100个pod,每个pod的request cpu=1000m。
创建这些pod后 调度器如何调度?
request 的资源是启动的时候必须有这么多资源才能调度成功。cpu是可压缩资源,理论上是可以调度上去的。 实验结果表明这个猜想是错误的。
下面但是没答出来,面试官请我去查。
做一个实验: 创建100个pod 每个pod申请一个1core。
实验结果:只设定request的情况下,只能调度成功4个pod。其余pod都无法调度,具体报错为:
Warning FailedScheduling 4m20s (x46 over 65m) default-scheduler 0/3 nodes are available: 1 node(s) had taint {master: nos}, that the pod didn’t tolerate, 2 Insufficient cpu.
这是什么原因呢? cpu不足?
insufficient cpu经过计算之后确实不够了,我的集群是3个节点,每个节点四个cpu。
- 查询所有pod的requests字段的总和。
# kubectl get pods --all-namespaces -o jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.spec.containers[*].resources.requests.cpu}{'\n'}{end}"
busyboxtest
ingress-demo-app-5967f8fd7d-p8rt7
ingress-demo-app-5967f8fd7d-qsvgz
multi-con
my-static-pod-k8s-master-node1 10m
nginx-app-5ccd894fcb-6k8hj
nginx-app-5ccd894fcb-cfpkf
nginx-app-5ccd894fcb-wqrmp
nginx-dns-8lc8b
nginx-dns-k7ldh
nginx-dns-wd6ff
nginx-test
po 100m
pod-secrets-via-env
pod-secrets-via-file
schedule-test-6cdbf894bd-62l8z 1
schedule-test-6cdbf894bd-6cw8c 1
schedule-test-6cdbf894bd-bm4vv 1
schedule-test-6cdbf894bd-cjnkd 1
schedule-test-6cdbf894bd-m9nl6 1
schedule-test-6cdbf894bd-pzhwl 1
schedule-test-6cdbf894bd-wj7mh 1
schedule-test-6cdbf894bd-wt2t6 1
schedule-test-6cdbf894bd-xnx4c 1
schedule-test-6cdbf894bd-xtskv 1
secret-pod
test
web-server
web-server-f7fcbdc98-rdl6d
web-server-f7fcbdc98-rjmn8
web-server-f7fcbdc98-rw4hr
web-server-f7fcbdc98-xblsj
ingress-nginx-admission-create-n9588
ingress-nginx-admission-patch-rdc86
ingress-nginx-controller-5d886544c7-4rgxp 100m
ingress-nginx-controller-5d886544c7-cjk76 100m
ingress-nginx-controller-5d886544c7-qgbvw 100m
calico-kube-controllers-dcb6dbf69-rdsfn
calico-node-66dw6 250m
calico-node-dz4vc 250m
calico-node-k4tbl 250m
calicoctl
coredns-b9bf78846-rnxpd 100m
coredns-b9bf78846-rvk2b 100m
default-http-backend-5b59f64f64-qf722 10m
etcd-k8s-master-node1 100m
kube-apiserver-k8s-master-node1 250m
kube-controller-manager-k8s-master-node1 200m
kube-proxy-4fqlp
kube-proxy-fglrn
kube-proxy-v9rm6
kube-scheduler-k8s-master-node1 100m
metrics-server-765d987858-q7l7b 100m
tigera-operator-7d7795c47f-2zz8t
- 计算这些pod的总的requests.cpu 共12120m。
这已经超过了节点cpu的总和。12120m > 12000m。所以shcedule-test pod最多只能调度成功4个。这个实验结果应该是面试官想要的。
突然发现资源真的好浪费呀,节点的cpu资源还有很多。节点cpu 使用不到10%。
这个cpu sum requests其实prometheus也可以看到(这是另外一个集群的.)
sum(namespace_cpu:kube_pod_container_resource_requests:sum{cluster="$cluster"}) / sum(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu",cluster="$cluster"})
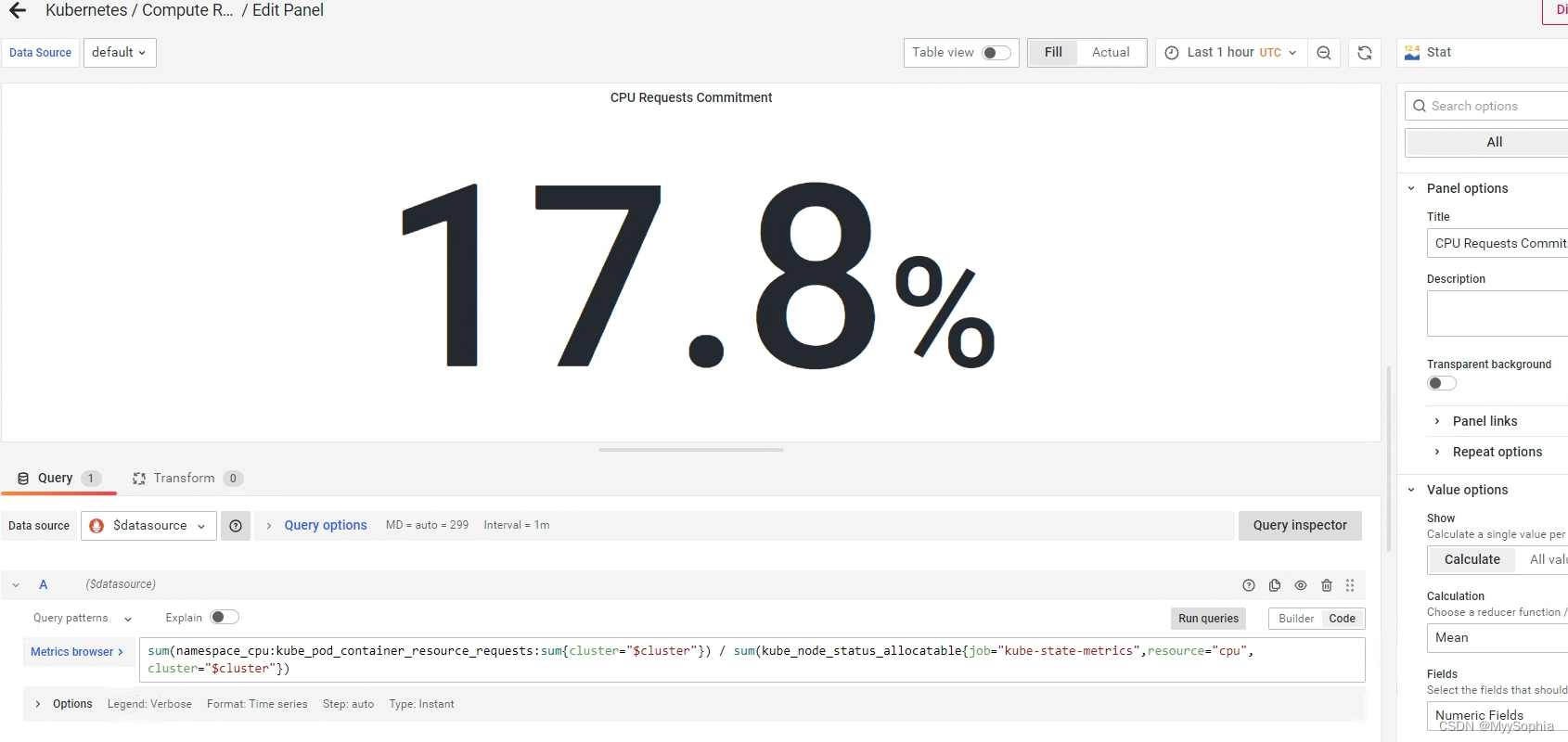
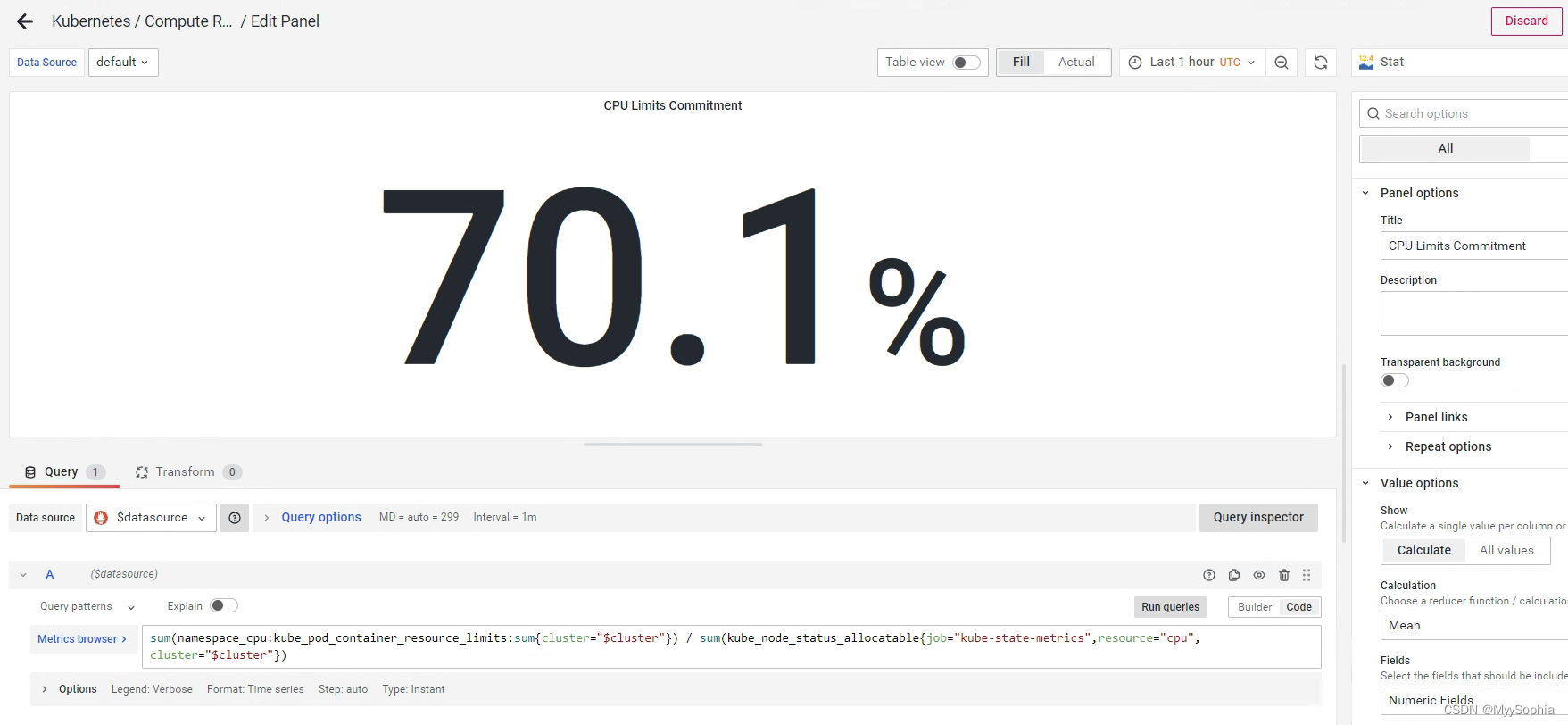
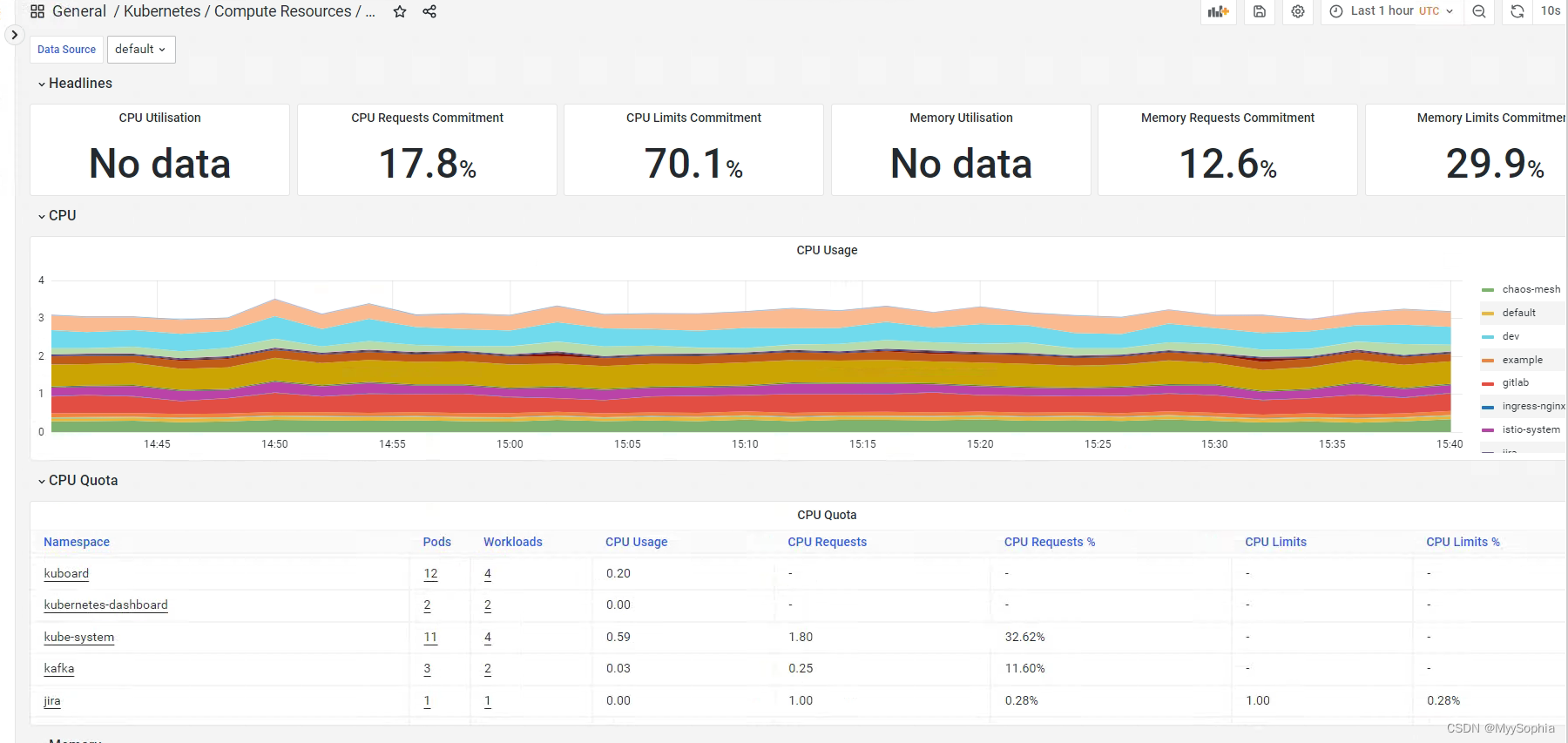
引申问题?
既然schedule-test pod是guaranteed pod,那么就应该优先调度,besteffort qos的pod不应该被驱逐么?
注意: 只写requests.cpu和limit.cpu ,pod的qosClass竟然还是burstable. 同时设定cpu和memory的memory 和limit才会是guaranteed pod。
2.如何查看当前的k8s 都占用了那些网段?
k get po controller-manager -n kube-system
查看controller-manager 的svc CIDR/ pod CIDR . 一般svc 是10.96.0.0/24
pod 的cidr 是10.244/0.0/24
3.shell 找出当前 哪个进程 向 /data 中写入或者读取的 的数据 最多?
iostat -p pid
iotop by 进程的io
ls -l /data 查看是最大的文件
lsof 文件名
查看对应的进程
4.用ansible 批量重启每个节点的kubelet 服务
ansibel k8s-all -m shell -a ‘systemctl restart kubelet’ -k
HR面
未完待续