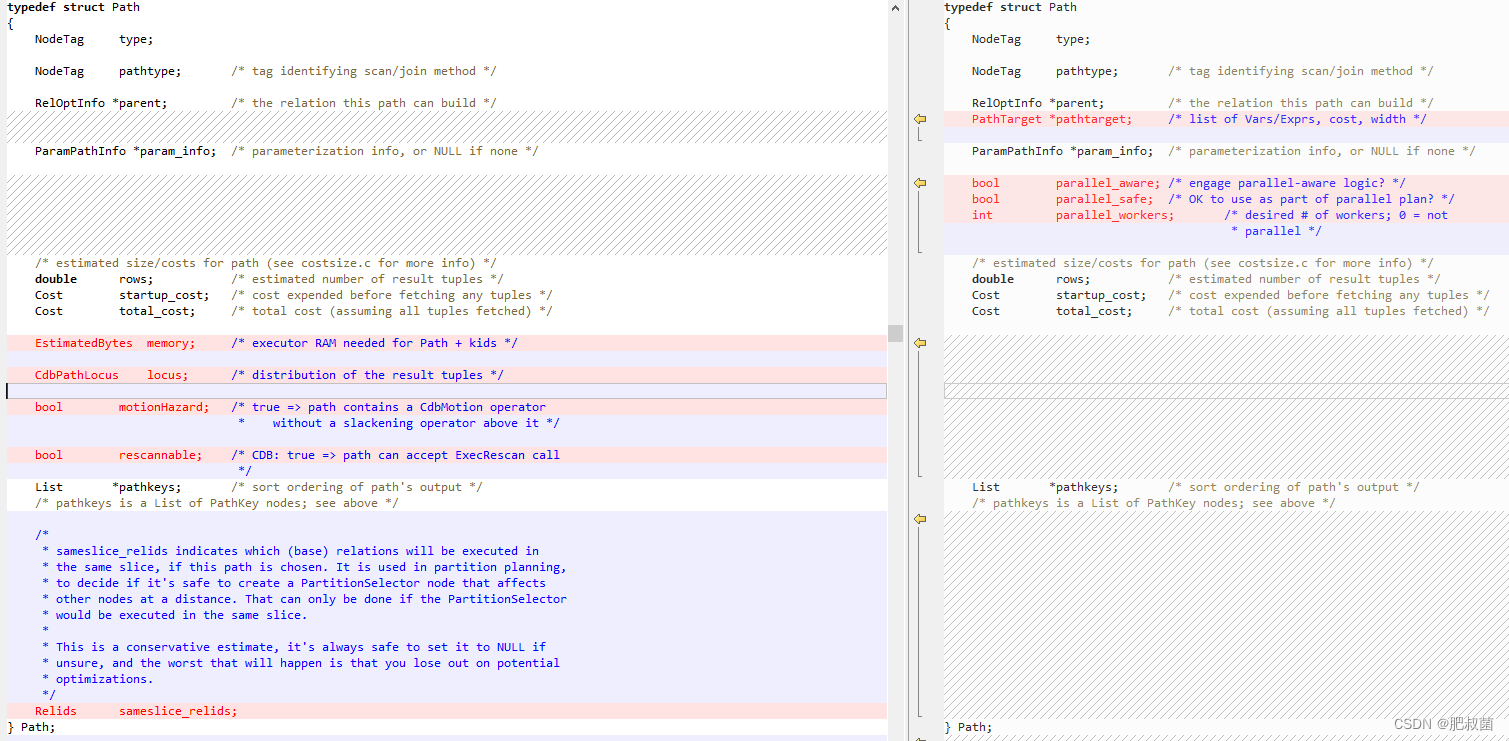
Path表示了一种可能的计算路径(比如顺序扫描或哈希关联),更复杂的路径会继承Path结构体并记录更多信息以用于优化。Greenplum为Path结构体(src/include/nodes/relation.h/Path)新加CdbPathLocus locus字段,用于表示结果元组在当前路径下的重分布和执行策略。Greenplum中表的分布键决定了元组存储时的分布情况,影响元组在那个segment的磁盘上的存储。CdbPathLocus决定了在执行时一个元组(元组可能来自表,也可能来自函数)在不同的进程间(不同segment的QE)的重分布情况,即一个元组该被哪个进程处理。
typedef enum CdbLocusType {
CdbLocusType_Null, // 不用Locus
CdbLocusType_Entry, /* a single backend process on the entry db: usually the qDisp itself, but could be a qExec started by the entry postmaster. */ // 表示entry db(即master)上单个backend进程,可以是QD(Query Dispatcher),也可以是entry上的QE(Query Executor)
CdbLocusType_SingleQE, /* a single backend process on any db: the qDisp itself, or a qExec started by a segment postmaster or the entry postmaster. */ // 任何节点上的单个backend进程,可以是QD或任意QE进程
CdbLocusType_General, /* compatible with any locus (data is self-contained in the query plan or generally available in any qExec or qDisp) */ // 和任何locus都兼容
CdbLocusType_SegmentGeneral,/* generally available in any qExec, but not available in qDisp */
CdbLocusType_Replicated, /* replicated over all qExecs of an N-gang */ // 在所有QEs都有副本
CdbLocusType_Hashed, /* hash partitioned over all qExecs of N-gang */ // 哈希分布到所有QEs
CdbLocusType_HashedOJ, /* result of hash partitioned outer join, NULLs can be anywhere */
CdbLocusType_Strewn, /* partitioned on no known function */ // 数据分布存储,但是分布键未知
CdbLocusType_End /* = last valid CdbLocusType + 1 */
} CdbLocusType;
CdbMotionPath
Greenplum引入了一个新路径CdbMotionPath,用于表示子路径的结果如何从发送方进程传送给接收方进程。优化器使用locus的类型选择最合适的结点进行最合适的数据流向处理,确定合适Motion。
cdbpath_create_motion_path函数Returns a Path that delivers the subpath result to the given locus, or NULL if it can’t be done. ‘pathkeys’ must specify an ordering equal to or weaker than the subpath’s existing ordering. If no motion is needed, the caller’s subpath is returned unchanged. Else if require_existing_order is true, NULL is returned if the motion would not preserve an ordering at least as strong as the specified ordering; also NULL is returned if pathkeys is NIL meaning the caller is just checking and doesn’t want to add motion. Else a CdbMotionPath is returned having either the specified pathkeys (if given and the motion uses Merge Receive), or the pathkeys of the original subpath (if the motion is order-preserving), or no pathkeys otherwise (the usual case).
cdbpath_create_motion_path主要接受两个参数subpath和locus,根据subpath的CdbPathLocus locus字段(表示结果元组在当前路径下的重分布和执行策略)和目标locus,添加相应的motion节点,以更改数据流向。其主要流程如下所示:
- 如果target locus和subpath->locus相同,说明无需添加motion节点
- 确定target locus和subpath->locus所包含的segment数量,以其中segment数量最少的为准
- 如果target locus是segment或master上的singleton QE或QD进程【a singleton qExec (1-gang) on a segment db or the entry db, or the qDisp process,CdbLocusType_Entry表示entry db(即master)上单个backend进程,可以是QD(Query Dispatcher),也可以是entry上的QE(Query Executor),CdbLocusType_SingleQE任何节点上的单个backend进程,可以是QD或任意QE进程】: 1. entry–>entry不需要motion 2. singleQE–>singleQE不需要motion 3. entry–>singleQE不需要motion(slice’s QE再master上运行) 4. singleQE–>entry创建将任何节点上的单个backend进程的数据流向更改到master单个backend进程(singleton gang)的CdbMotionPath节点(只使用这个节点来表示路径具有’Entry’ locus;将不会在“计划”树中创建相应的“运动”节点,也就是目前没有这种数据流向)5. SegmentGeneral–>entry/singleQE 源locus为master/segment上的QE(generally available in any qExec, but not available in qDisp),为这种情况创建motion。Data is only available on segments, to distingush it with CdbLocusType_General, adding a motion to indicated this slice must be executed on a singleton gang.This motion may be redundant for segmentGeneral --> singleQE if the singleQE is not promoted to executed on qDisp in the end, so in apply_motion_mutator(), we will omit it.数据仅在segment上可用,为了用CdbLocusType_General来区分它,添加一个动作来指示该切片必须在单个singleton gang上执行。如果singleQE最终没有被提升为在qDisp上执行,那么这个动作对于segmentGeneral–>singleQE来说可能是多余的,所以在apply_motion_mutator中,我们将省略它。6. Generall–>entry/singleQE 无需添加morion,可以再任何segment上直接运行(general兼容任何locus)。7. replicated–>singleton/entry 非法 8. Hashed/HashedOJ/Strewn–>singleton/entry 非法 源locus的策略为哈希分布到所有QEs(hash partitioned over all qExecs of N-gang)、哈希分布outer join的结果null分布到任何segment(result of hash partitioned outer join, NULLs can be anywhere)、数据分布存储,但是分布键未知(partitioned on no known function),为这种情况创建motion。
- 如果subpath->locus是segment或master上的singleton QE或QD进程【a singleton qExec (1-gang) on a segment db or the entry db, or the qDisp process,CdbLocusType_Entry表示entry db(即master)上单个backend进程,可以是QD(Query Dispatcher),也可以是entry上的QE(Query Executor),CdbLocusType_SingleQE任何节点上的单个backend进程,可以是QD或任意QE进程】: entry/singleQE–>partitioned或entry/singleQE–>replicated才合法,为这种情况创建motion。
- 如果subpath->locus是Hashed/HashedOJ/Strewn【哈希分布到所有QEs(hash partitioned over all qExecs of N-gang)、哈希分布outer join的结果null分布到任何segment(result of hash partitioned outer join, NULLs can be anywhere)、数据分布存储,但是分布键未知(partitioned on no known function)】:1. 如果目标locus也是Hashed/HashedOJ/Strewn,即partitioned–>partitioned,如果目标locus和源locus相等,则无需创建motion,否则为这种情况创建motion。2. 如果目标locus是replicated,即partitioned–>replicated为这种情况创建motion。其他情况为非法。
- 如果subpath->locus是General和任何locus都兼容:1. 如果源和目标locus满足general–>general或general–>replicated或general–>segmentGeneral(master/segment上的QE(generally available in any qExec, but not available in qDisp)),则无需创建motion。2. 如果目标locus是Hashed/HashedOJ/Strewn【哈希分布到所有QEs(hash partitioned over all qExecs of N-gang)、哈希分布outer join的结果null分布到任何segment(result of hash partitioned outer join, NULLs can be anywhere)、数据分布存储,但是分布键未知(partitioned on no known function)】,即general–>partitioned,为这种情况创建motion。其他情况为非法。
- 如果subpath->locus是replicated:如果目标locus也是replicated,即replicated–>replicated,无需创建motion。其他情况为非法。
- 如果subpath->locus是SegmentGeneral(master/segment上的QE(generally available in any qExec, but not available in qDisp)):如果目标locus是Hashed哈希分布到所有QEs(hash partitioned over all qExecs of N-gang),目标locus的segment数量大于subpath->locus,In such a case we redistribute SegmentGeneral to Hashed,为这种情况创建motion。2. 如果目标locus是replicated,且不是UPDATE/DELETE复制表,则为这种情况创建motion。3. 如果目标locus是SegmentGeneral,为这种情况创建motion。其他情况为非法。
Path *cdbpath_create_motion_path(PlannerInfo *root, Path *subpath, List *pathkeys, bool require_existing_order, CdbPathLocus locus){
if (cdbpathlocus_equal(subpath->locus, locus)) return subpath; /* Motion is to change path's locus, if target locus is the same as the subpath's, there is no need to add motion. */
CdbMotionPath *pathnode; int numsegments = CdbPathLocus_CommonSegments(subpath->locus, locus);
if (CdbPathLocus_IsBottleneck(locus)){ /* Moving subpath output to a single executor process (qDisp or qExec)? */
if (CdbPathLocus_IsEntry(subpath->locus) && CdbPathLocus_IsEntry(locus)) { /* entry-->entry? No motion needed. */
subpath->locus.numsegments = getgpsegmentCount(); return subpath;
}
if (CdbPathLocus_IsSingleQE(subpath->locus) && CdbPathLocus_IsSingleQE(locus)) { /* singleQE-->singleQE? No motion needed. */
subpath->locus.numsegments = numsegments; return subpath;
}
if (CdbPathLocus_IsEntry(subpath->locus)) { /* entry-->singleQE? Don't move. Slice's QE will run on entry db. */
subpath->locus.numsegments = numsegments; return subpath;
}
if (CdbPathLocus_IsSingleQE(subpath->locus)) { /* singleQE-->entry? Don't move. Slice's QE will run on entry db. */
if (!bms_is_empty(PATH_REQ_OUTER(subpath))) return NULL; /* If the subpath requires parameters, we cannot generate Motion atop of it. */
/* Create CdbMotionPath node to indicate that the slice must be dispatched to a singleton gang running on the entry db. We merely use this node to note that the path has 'Entry' locus; no corresponding Motion node will be created in the Plan tree. */
pathnode = makeNode(CdbMotionPath); pathnode->path.pathtype = T_Motion;
pathnode->path.parent = subpath->parent; pathnode->path.locus = locus; pathnode->path.pathkeys = pathkeys; pathnode->subpath = subpath;
pathnode->path.rows = subpath->rows; pathnode->path.startup_cost = subpath->total_cost; pathnode->path.total_cost = subpath->total_cost;
pathnode->path.memory = subpath->memory; pathnode->path.motionHazard = subpath->motionHazard;
pathnode->path.rescannable = false; /* Motion nodes are never rescannable. */
return (Path *) pathnode;
}
if (CdbPathLocus_IsSegmentGeneral(subpath->locus)) {
if (!bms_is_empty(PATH_REQ_OUTER(subpath))) return NULL; /* If the subpath requires parameters, we cannot generate Motion atop of it. */
/* Data is only available on segments, to distingush it with CdbLocusType_General, adding a motion to indicated this slice must be executed on a singleton gang. This motion may be redundant for segmentGeneral --> singleQE if the singleQE is not promoted to executed on qDisp in the end, so in apply_motion_mutator(), we will omit it. */
pathnode = makeNode(CdbMotionPath); pathnode->path.pathtype = T_Motion;
pathnode->path.parent = subpath->parent; pathnode->path.locus = locus; pathnode->path.pathkeys = pathkeys; pathnode->subpath = subpath;
pathnode->path.rows = subpath->rows; pathnode->path.startup_cost = subpath->total_cost; pathnode->path.total_cost = subpath->total_cost;
pathnode->path.memory = subpath->memory; pathnode->path.motionHazard = subpath->motionHazard;
pathnode->path.rescannable = false; /* Motion nodes are never rescannable. */
return (Path *) pathnode;
}
if (CdbPathLocus_IsGeneral(subpath->locus)){ /* No motion needed if subpath can run anywhere giving same output. */
/* general-->(entry|singleqe), no motion is needed, can run directly on any of the common segments */
subpath->locus.numsegments = numsegments; return subpath;
}
if (require_existing_order && !pathkeys) return NULL; /* Fail if caller refuses motion. */
if (CdbPathLocus_IsReplicated(subpath->locus)) /* replicated-->singleton would give redundant copies of the rows. */ goto invalid_motion_request;
/* Must be partitioned-->singleton. If caller gave pathkeys, they'll be used for Merge Receive. If no pathkeys, Union Receive will arbitrarily interleave the rows from the subpath partitions in no special order. */
if (!CdbPathLocus_IsPartitioned(subpath->locus)) goto invalid_motion_request;
}
else if (CdbPathLocus_IsBottleneck(subpath->locus)) { /* Output from a single process to be distributed over a gang? */ /* Must be bottleneck-->partitioned or bottleneck-->replicated */
if (!CdbPathLocus_IsPartitioned(locus) && !CdbPathLocus_IsReplicated(locus)) goto invalid_motion_request;
if (require_existing_order && !pathkeys) return NULL; /* Fail if caller disallows motion. */
pathkeys = subpath->pathkeys; /* Each qExec receives a subset of the rows, with ordering preserved. */
}
else if (CdbPathLocus_IsPartitioned(subpath->locus)) { /* Redistributing partitioned subpath output from one gang to another? */
if (CdbPathLocus_IsPartitioned(locus)) { /* partitioned-->partitioned? */
if (cdbpathlocus_equal(subpath->locus, locus)) return subpath; /* No motion if subpath partitioning matches caller's request. */
}
else if (!CdbPathLocus_IsReplicated(locus)) goto invalid_motion_request; /* Must be partitioned-->replicated */
if (require_existing_order) return NULL; /* Fail if caller insists on ordered result or no motion. */
pathkeys = NIL; /* Output streams lose any ordering they had. Only a qDisp or singleton qExec can merge sorted streams (for now). */
}
else if (CdbPathLocus_IsGeneral(subpath->locus)) { /* If subplan uses no tables, it can run on qDisp or a singleton qExec. */
/*
* No motion needed if general-->general or general-->replicated or
* general-->segmentGeneral
*/
if (CdbPathLocus_IsGeneral(locus) ||
CdbPathLocus_IsReplicated(locus) ||
CdbPathLocus_IsSegmentGeneral(locus))
{
subpath->locus.numsegments = numsegments;
return subpath;
}
/* Must be general-->partitioned. */
if (!CdbPathLocus_IsPartitioned(locus))
goto invalid_motion_request;
/* Fail if caller wants no motion. */
if (require_existing_order &&
!pathkeys)
return NULL;
/* Since the motion is 1-to-many, the rows remain in the same order. */
pathkeys = subpath->pathkeys;
}
/* Does subpath produce same multiset of rows on every qExec of its gang? */
else if (CdbPathLocus_IsReplicated(subpath->locus))
{
/*
* If the subpath requires parameters, we cannot generate Motion atop of it.
*/
if (!bms_is_empty(PATH_REQ_OUTER(subpath)))
return NULL;
/* No-op if replicated-->replicated. */
if (CdbPathLocus_IsReplicated(locus))
{
subpath->locus.numsegments = numsegments;
return subpath;
}
/* Other destinations aren't used or supported at present. */
goto invalid_motion_request;
}
/* Most motions from SegmentGeneral (replicated table) are disallowed */
else if (CdbPathLocus_IsSegmentGeneral(subpath->locus))
{
/*
* The only allowed case is a SegmentGeneral to Hashed motion,
* and SegmentGeneral's numsegments is smaller than Hashed's.
* In such a case we redistribute SegmentGeneral to Hashed.
*
* FIXME: HashedOJ?
*/
if (CdbPathLocus_IsHashed(locus) &&
(CdbPathLocus_NumSegments(locus) >
CdbPathLocus_NumSegments(subpath->locus)))
{
pathkeys = subpath->pathkeys;
}
else if (CdbPathLocus_IsReplicated(locus))
{
/*
* Assume that this case only can be generated in
* UPDATE/DELETE statement
*/
if (root->upd_del_replicated_table == 0)
goto invalid_motion_request;
}
else if (CdbPathLocus_IsSegmentGeneral(locus))
{
subpath->locus.numsegments = Min(subpath->locus.numsegments, locus.numsegments);
return subpath;
}
else goto invalid_motion_request;
}
else goto invalid_motion_request;
if (IsA(subpath, MaterialPath)) subpath = ((MaterialPath *) subpath)->subpath; /* Don't materialize before motion. */
/* MPP-3300: materialize *before* motion can never help us, motion pushes data. other nodes pull. We relieve motion deadlocks by adding materialize nodes on top of motion nodes */
/* Create CdbMotionPath node. */
pathnode = makeNode(CdbMotionPath); pathnode->path.pathtype = T_Motion;
pathnode->path.parent = subpath->parent; pathnode->path.locus = locus; pathnode->path.rows = subpath->rows; pathnode->path.pathkeys = pathkeys; pathnode->subpath = subpath;
cdbpath_cost_motion(root, pathnode); /* Cost of motion */
/* Tell operators above us that slack may be needed for deadlock safety. */
pathnode->path.motionHazard = true; pathnode->path.rescannable = false;
return (Path *) pathnode;
invalid_motion_request: /* Unexpected source or destination locus. */
return NULL;
}
query_planner最后一个步骤执行make_one_rel --> make_rel_from_joinlist
make_one_rel --> set_base_rel_pathlist --> set_rel_pathlist --> set_append_rel_pathlist -> create_append_path -> set_append_path_locus --> cdbpath_create_motion_path
make_one_rel --> set_base_rel_pathlist --> set_rel_pathlist -->set_append_rel_pathlist --> get_cheapest_parameterized_child_path --> reparameterize_path -> create_append_path -> set_append_path_locus --> cdbpath_create_motion_path
set_append_rel_pathlist --> generate_mergeappend_paths -> create_merge_append_path -> set_append_path_locus --> cdbpath_create_motion_path
make_one_rel --> set_base_rel_sizes --> set_rel_size
set_rel_size --> set_dummy_rel_pathlist -> create_append_path -> set_append_path_locus --> cdbpath_create_motion_path
set_rel_size --> set_append_rel_size --> set_dummy_rel_pathlist -> create_append_path -> set_append_path_locus --> cdbpath_create_motion_path
set_rel_size -->set_subquery_pathlist --> set_dummy_rel_pathlist -> create_append_path -> set_append_path_locus --> cdbpath_create_motion_path
standard_join_search --> join_search_one_level --> make_join_rel --> join_is_legal --> create_unique_path --> cdbpath_create_motion_path
standard_join_search --> join_search_one_level -->make_rels_by_clause_joins --> make_join_rel --> join_is_legal --> create_unique_path --> cdbpath_create_motion_path
standard_join_search --> join_search_one_level -->make_rels_by_clauseless_joins --> make_join_rel --> join_is_legal --> create_unique_path --> cdbpath_create_motion_path
make_join_rel --> add_paths_to_joinrel --> sort_inner_and_outer --> create_unique_path --> cdbpath_create_motion_path
make_join_rel -->add_paths_to_joinrel --> match_unsorted_outer --> create_unique_path --> cdbpath_create_motion_path
make_join_rel -->add_paths_to_joinrel --> hash_inner_and_outer --> create_unique_path --> cdbpath_create_motion_path
make_join_rel --> mark_dummy_rel -> create_append_path -> set_append_path_locus --> cdbpath_create_motion_path
standard_join_search --> join_search_one_level --> have_join_order_restriction --> has_legal_joinclause --> join_is_legal --> create_unique_path --> cdbpath_create_motion_path
standard_join_search --> join_search_one_level -->make_rels_by_clause_joins --> have_join_order_restriction --> has_legal_joinclause --> join_is_legal --> create_unique_path --> cdbpath_create_motion_path
cdbpath_motion_for_join --> cdbpath_create_motion_path
CdbPathLocus
cdbpath_motion_for_join(PlannerInfo root,
JoinType jointype, / JOIN_INNER/FULL/LEFT/RIGHT/IN */
Path *p_outer_path, / INOUT */
Path *p_inner_path, / INOUT */
List redistribution_clauses, / equijoin RestrictInfo list */
List *outer_pathkeys,
List *inner_pathkeys,
bool outer_require_existing_order,
bool inner_require_existing_order)
cdbpath_dedup_fixup
cdbpath_contains_wts
has_redistributable_clause
turn_volatile_seggen_to_singleqe
以ForeignPath为例
/* ForeignPath represents a potential scan of a foreign table
* fdw_private stores FDW private data about the scan. While fdw_private is not actually touched by the core code during normal operations, it's generally a good idea to use a representation that can be dumped by nodeToString(), so that you can examine the structure during debugging with tools like pprint(). */
typedef struct ForeignPath{
Path path; List *fdw_private;
} ForeignPath;
ForeignPath *create_foreignscan_path(PlannerInfo *root, RelOptInfo *rel, double rows, Cost startup_cost, Cost total_cost, List *pathkeys, Relids required_outer, List *fdw_private) {
ForeignPath *pathnode = makeNode(ForeignPath);
/* Since the path's required_outer should always include all the rel's lateral_relids, forcibly add those if necessary. This is a bit of a hack, but up till early 2019 the contrib FDWs failed to ensure that, and it's likely that the same error has propagated into many external FDWs. Don't risk modifying the passed-in relid set here. */
if (rel->lateral_relids && !bms_is_subset(rel->lateral_relids, required_outer)) required_outer = bms_union(required_outer, rel->lateral_relids);
/* Although this function is only designed to be used for scans of baserels, before v12 postgres_fdw abused it to make paths for join and upper rels. It will work for such cases as long as required_outer is empty (otherwise get_baserel_parampathinfo does the wrong thing), which fortunately is the expected case for now. */ // 尽管此函数仅设计用于扫描baserel,但在v12 postgres_fdw滥用它为join和upper rel创建路径之前。只要required_outer为空(否则get_baserel_parampathinfo会做错误的事情),它就会适用于这种情况,幸运的是,这是目前预期的情况。
if (!bms_is_empty(required_outer) && !(rel->reloptkind == RELOPT_BASEREL || rel->reloptkind == RELOPT_OTHER_MEMBER_REL)) elog(ERROR, "parameterized foreign joins are not supported yet");
pathnode->path.pathtype = T_ForeignScan;
pathnode->path.parent = rel;
pathnode->path.param_info = get_baserel_parampathinfo(root, rel, required_outer);
pathnode->path.rows = rows; pathnode->path.startup_cost = startup_cost; pathnode->path.total_cost = total_cost;
pathnode->path.pathkeys = pathkeys;
switch (rel->ftEntry->exec_location){
case FTEXECLOCATION_ANY: CdbPathLocus_MakeGeneral(&(pathnode->path.locus), getgpsegmentCount()); break;
case FTEXECLOCATION_ALL_SEGMENTS: CdbPathLocus_MakeStrewn(&(pathnode->path.locus), getgpsegmentCount()); break;
case FTEXECLOCATION_MASTER: CdbPathLocus_MakeEntry(&(pathnode->path.locus)); break;
default: elog(ERROR, "unrecognized exec_location '%c'", rel->ftEntry->exec_location);
}
pathnode->fdw_private = fdw_private;
return pathnode;
}
RelOptInfo *make_one_rel(PlannerInfo *root, List *joinlist)
| -- set_base_rel_pathlists(PlannerInfo *root)
| -- set_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, Index rti, RangeTblEntry *rte)
switch (rel->rtekind) case RTE_RELATION: if (rte->relkind == RELKIND_FOREIGN_TABLE)
| -- set_foreign_pathlist(PlannerInfo *root, RelOptInfo *rel, RangeTblEntry *rte)
set_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, Index rti, RangeTblEntry *rte)
else if (rte->inh) set_append_rel_pathlist(root, rel, rti, rte); /* It's an "append relation", process accordingly */
| -- set_append_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, Index rti, RangeTblEntry *rte)
| -- set_rel_pathlist(PlannerInfo *root, RelOptInfo *rel, Index rti, RangeTblEntry *rte)
| -- set_foreign_pathlist(PlannerInfo *root, RelOptInfo *rel, RangeTblEntry *rte)
rel->fdwroutine->GetForeignPaths(root, rel, rte->relid); /* Call the FDW's GetForeignPaths function to generate path(s) */
set_cheapest(rel); /* Select cheapest path */
/*
* CdbPathLocus
*
* Specifies a distribution of tuples across segments.
*
* If locustype is CdbLocusType_Hashed or CdbLocusType_HashedOJ:
* Rows are distributed based on values of a partitioning key. The
* partitioning key is often called a "distribution key", to avoid
* confusion with table partitioning.
*
* A tuple's partitioning key consists of one or more key columns.
* When CdbPathLocus represents the distribution of a table, the
* partitioning key corresponds to the columns listed in DISTRIBUTED BY
* of the table, but the planner can distribute intermediate results
* based on arbitrary expressions.
*
* The partitioning key is represented by a List of DistributionKeys,
* one for each key column. Each DistributionKey contains a list of
* EquivalenceClasses, which contain expressions that can be used
* to compute the value for the key column. Any of the expressions
* can be used to compute the value, depending on what relations are
* available at that part of the plan.
*
* For example, if the query contains a "WHERE a=b" clause, the planner
* would form an EquivalenceClass that contains two members, "a" and "b".
* Because of the WHERE clause, either "a" and "b" can be used to
* compute the hash value. Usually, a DistributionKey contains only one
* EquivalenceClass, because whenever there is an equijoin on two
* expressions, the planner puts them in the same EquivalenceClass.
* However, if there are FULL JOINs in the query, the FULL JOIN quals do
* not form equivalence classes with other quals, because the NULL
* handling is different. See src/backend/optimizer/README for
* discussion on "outerjoin delayed" equivalence classes.
*
* When a path locus is constructed for a FULL JOIN, CdbLocusType_HashedOJ
* is used instead of CdbLocusType_Hashed. The important distinction
* between Hashed and HashedOJ is the semantics for NULLs. In a Hashed
* distribution, a NULL is hashed like any other value, and all NULLs are
* located on a particular segment, based on the hash value of a NULL
* datum. But with HashedOJ, NULL values can legitimately appear on any
* segment!
*
* For join optimization, Hashed and HashedOJ can both be used. In an inner
* join on A=B, NULL rows won't match anyway. And for an OUTER JOIN, it
* doesn't matter which segment the NULL rows appear on, as long as we
* correctly mark the resulting locus also as HashedOJ. But for grouping,
* HashedOJ can not be used, because you might end up with multiple NULL
* NULL groups, one for each segment!
*
* If locustype == CdbLocusType_Strewn:
* Rows are distributed according to a criterion that is unknown or
* may depend on inputs that are unknown or unavailable in the present
* context. The 'distkey' field is NIL.
*
* If the distribution is not partitioned, then the 'distkey' field is NIL.
*
* The numsegments attribute specifies how many segments the tuples are
* distributed on, from segment 0 to segment `numsegments-1`. In the future
* we might further change it to a range or list so discontinuous segments
* can be described. This numsegments has different meaning for different
* locustype:
* - Null: numsegments is usually meaningless in Null locus as it will be
* remade to other locus types later. But there is also cases that we set
* a valid numsegments in Null locus, this value will be kept when remade
* it to other locus types, and it becomes meaningful after that;
* - Entry: numsegments in Entry locus specify the candidate segments to put
* the Entry node on, it's master and all the primary segments in current
* implementation;
* - SingleQE: numsegments in SingleQE locus specify the candidate segments
* to put the SingleQE node on, although SingleQE is always executed on one
* segment but numsegments usually have a value > 1;
* - General: similar with Entry and SingleQE;
* - SegmentGeneral, Replicated, Hashed, HashedOJ, Strewn: numsegments in
* these locus types specify the segments that contain the tuples;
*/
typedef struct CdbPathLocus
{
CdbLocusType locustype;
List *distkey;
int numsegments;
} CdbPathLocus;