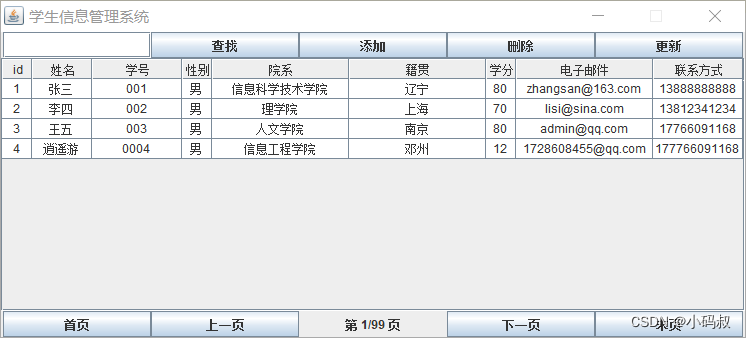
UC伯克利学者联手CMU、斯坦福等,再次推出一个全新模型70亿/130亿参数的Vicuna,俗称「小羊驼」,小羊驼号称能达到GPT-4的90%性能。
- 欢迎使用小羊驼🦙
- 环境搭建
- 权重下载
- 下载 Vicuna Weight
- 下载 LLAMA Weight
- 构建真正的 working weight
- 命令行推理
- 单GPU推理:
- 大功告成!
欢迎使用小羊驼🦙
Github地址
环境搭建
conda create -n py310_chat python=3.10 # 创建新环境
source activate py310_chat # 激活环境
pip install fschat # 安装fschat包
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install --upgrade pip # enable PEP 660 support
pip install -e .
git lfs install
# 如果载好了应该是>>>Git LFS initialized.
安装LFS:
- 如果是 Homebrew,请运行 brew install git-lfs
- 如果是 MacPorts,请运行 port install git-lfs
- 如果是CentOS,请运行yum install git-lfs
权重下载
70亿参数对应的版本是7b;130亿对应的是13b(billion)
下载 Vicuna Weight
git clone https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
# or
git clone https://huggingface.co/lmsys/vicuna-7b-delta-v1.1
请注意,这不是直接的 working weight ,而是LLAMA-13B的 working weight 与 original weight 的差值。(由于LLAMA的规则,我们无法分配LLAMA的 weight 。
下载 LLAMA Weight
这里直接从HuggingFace下载,已转化为 HuggingFace格式的原始LLAMA-7B或LLAMA-13B 权重):
git clone https://huggingface.co/decapoda-research/llama-13b-hf # more powerful, need at least 24G gpu memory
# or
git clone https://huggingface.co/decapoda-research/llama-7b-hf # smaller, need 12G gpu memory
量力而行⬆️上面是官方教程给的,但是7b的权重文件和vicuna-delta的7b对不上
📢注意:LLAMA的权重用这个更好:
llama-7b
构建真正的 working weight
当这两个 weight 备好后,我们可以使用Vicuna团队的工具来创建真正的 working weight 。
执行如下命令创建最终 working weight:
python -m fastchat.model.apply_delta --base /path/to/llama-13bOR7b-hf/ --target /path/to/save/working/vicuna/weight/ --delta /path/to/vicuna-13bOR7b-delta-v1.1/ --low-cpu-mem
>>>
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
Split files for the base model to /tmp/tmptu2g17_d
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [01:47<00:00, 3.26s/it]
Split files for the delta model to /tmp/tmpol8jc2oy
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [01:03<00:00, 31.92s/it]
Applying the delta
33it [02:09, 3.91s/it]
Saving the target model to vicuna/weight/
然而显存很不给力地爆了,用的是Telsa p100(显存16G)
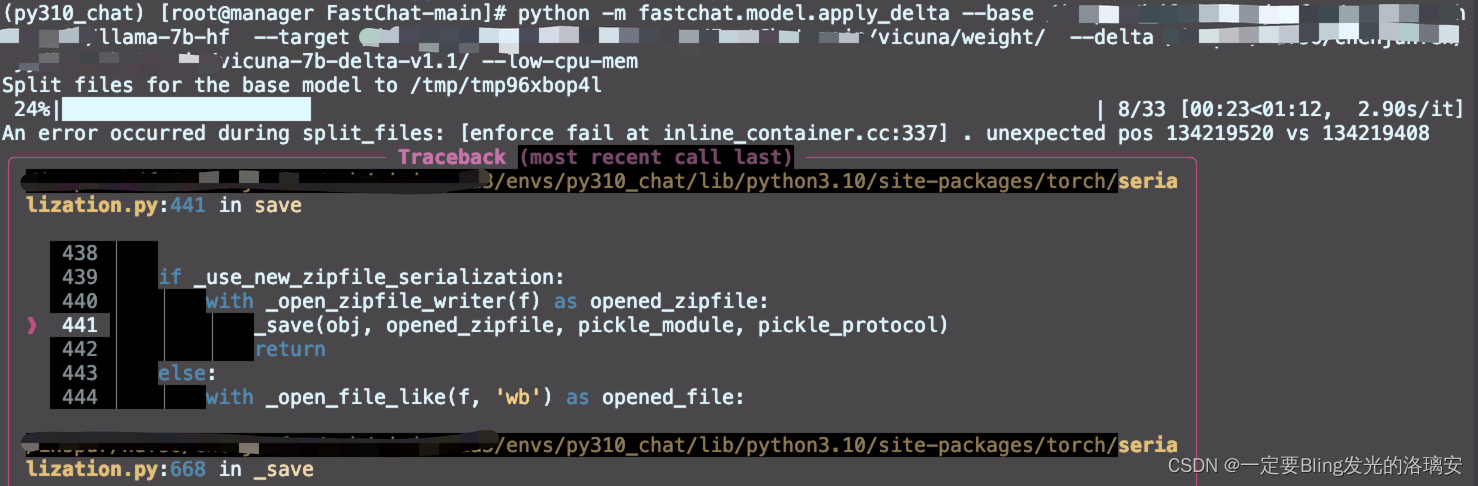
这里要注意你的内存够不够,我下载的是LLAMA-7B的权重文件大约13G,对应的vicuna权重也是13G,同时你还要留够我们真正需要的working权重的空间, 也是13G,所以7B的模型总共需要39G~40G空间。13B的话,我听大佬说LLAMA13B好像要30+G,估算一下总共差不多要快100个G了。
怪不得爆呢~
colab A100救我狗命😝
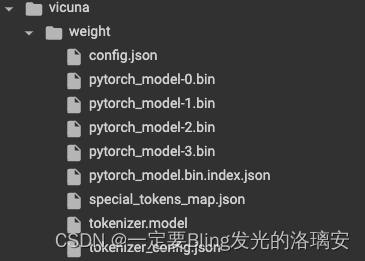
如果用的是7b的模型就是以上output;如果是13b那么就是如下的output:

命令行推理
单GPU推理:
下面的命令要求Vicuna-13B大约有28GB的GPU内存,Vicuna-7B大约有14GB的GPU存储器。
python -m fastchat.serve.cli --model-path vicuna/weight
大功告成!

(▽)开心
参考链接🔗:https://github.com/km1994/LLMsNineStoryDemonTower/tree/main/Vicuna